A new website for 2020
- I have a new website
- I'm exhausted
- I'm writing a book
- My current workflow
- My initial website + Patreon setup
- Moving away from hugo
- The basic idea
- Closing words
Contents
Hi everyone. Has it been two months since I last posted something? Yes it has!
That seems like a nice round duration, so let's break the silence with a few announcements.
I have a new website
If everything goes well, you're on it right now.
Does it feel okay? Take a minute to accustom yourself to your new surroundings. Identify potential sources of fresh water. Gather some supplies with which to fashion a makeshift shelter.
You good? Good.
We'll come back to that. In great detail. That's, like, the main topic.
I'm exhausted
This isn't overly relevant, but - I'd like to apologize for taking so long to publish something else. Every week that went by without publishing something felt like I was failing my patrons.
Sure, there's a lot going on in the world right now.
If you're reading this from the future, look up 2020 on Wikipedia or something.
It was quite the year.
And I've been following it pretty closely, and everything just... happens, so much, and it's emotionally draining. It's of course much worse for other people, and we need to keep fighting for them.
Point is, I'm sorry.
I tried to make myself feel better with self reminders that the people supporting my work would rather I take care of myself so I can keep writing content for the years to come, rather than burn out yet again.
There seems to be a lot of burn out going around right now. I'm not super surprised. These are difficult times y'all. Take care of yourselves. You have my love and support.
Even now, as I'm about to publish this - I'm exhausted. So I'll do my best to strike a balance and publish regularly - even if that means publishing other things while I'm waiting for the courage to finish up a series.
Okay. That was important. Next announcement.
I'm writing a book
That's right.
Honestly, you should have seen that one coming. I left some hints on Twitter but also, I hope it's obvious by now - to anyone reading my stuff - that I like to write a lot.
Also, against all expectations, I keep receiving encouraging messages that claim that I'm good at explaining stuff, and that my articles have been helpful, and that I should keep going.
I know! I don't believe it either. But here we are.
So a lot of folks have been asking more in-depth questions about Rust. I should have seen it coming, after publishing my whirlwind tour of Rust.
And a lot of those questions are about Rust lifetimes! And I've touched on the topic before, but it was a quick overview, not an in-depth exploration like the series I do.
So I started writing an article, and I didn't really... stop?
I was writing pages and pages and I kept checking the "estimated reading time" counter, and it kept going up and up - one hour, okay. Two hours, that's a bit long. Three hours? Okay, hold on, stop, wait a minute, that's a book.
So it's gonna be a book. Eventually.
It'll first appear in the form of a Patreon-exclusive series, where each part corresponds to a chapter, and eventually, I'm going to take all that content, and generate a PDF or an EPUB of it, and you'll be able to buy the whole thing in one convenient package.
That sounds like a lot of work! I know! And it is!
So before embarking on this adventure for real (I've drafted maybe half the thing?), I wanted to make myself some better content management tools.
My current workflow
Ever since I started my Patreon, I've evolved from "casual, blog-like writing" to writing pieces that will hopefully remain relevant for years to come.
That goal can only be met if the articles are updated regularly, to keep up-to-date with OS limitations, evolutions of formats, crates, and rustc compiler diagnostics.
Right now, when I write a series, I have a Git repository with the code, and I iterate like crazy - two, three parts ahead, and I copy/paste code from the repository to the markdown files. And similarly, I run commands in the terminal and copy/paste the output.
I also make diagrams in draw.io, and I - also - copy and paste them straight into vscode, where an extension is configured to save the image file in the right directory, and add the proper markup.
Arguably, it works! It's relatively fast to write (although the copying and pasting is tedious). But it's really tough to maintain.
Whenever someone points out a problem about an article in the middle of an old series, I need to:
- dig up the Git repo
- figure out where in the commit history I was when I wrote that article
- get everything to compile and run again
- fix the problem
- copy paste all the relevant changes into the article, and possibly the articles after that.
- review all the articles for consistency.
Sometimes I skip some of those steps. And then there's inconsistencies.
So I thought to myself, I need to take this seriously. Each of these series is a project, and it needs to be maintained. And there's a lot of tooling to help maintain code projects, but not nearly the same amount (or quality) for writing projects.
So, I have a solution in mind for series maintainability, a pretty complete set of ideas I can't wait to implement - but before I started work on that, I wanted to revamp my site.
My initial website + Patreon setup
I was excited when I first released Patreon integration for my website.
I was launching everything at the same time! But I wanted to assume minimal maintenance burden and focus on writing. Which worked great.
Back then, I said I would write about the setup, so others could replicate it if they wanted - and then I kinda never did that. So before I talk about the new setup, let's talk about the previous one.
I've probably used half a dozen static site generators for my website.
I definitely remember using nanoc (Ruby), and switching to jekyll (Ruby) at some point. When I launched the Patreon integration, I was using hugo.
Now, I really don't want to be spending any time saying negative things about projects in this post - not when there's so much cool stuff to show off! So all I'll say is this: hugo was easy to get started with, and it stayed relatively out of my way.
I forked one of the more minimal themes, and added the pieces I wanted: cool bear's hot tip, some navigation, etc.
The workflow was:
- Compile markdown content with hugo
- Use s3cmd to deploy to Amazon S3
- Have Cloudflare workers in front of the S3 bucket, to deal with Patreon login and access control.
In order for the Cloudflare worker code to know what articles were exclusive and until when, I used hugo's templating system to output some tags that contained metadata.
At first I tried using proper tags, and then HTML comments, but eventually I got frustrated while debugging it - was Cloudflare stripping them because they had no content? Or was it a caching problem?
So my fallback was to use plain text, s-expression-like tags, like so:
(amos exclusive-until="2020-05-03T07:30:00Z")
(amos title="Thread-local storage")
(amos content-start)
<div class="markdown">
<p>This is the contents of the article</p>
</div>
(amos content-end)
Low-tech? Absolutely. It made it extremely easy to debug, though, and the Cloudflare worker could parse it with no trouble at all, extract the information needed, truncate the content and show the gate if we were in the Patreon-exclusive period.
Speaking of that - truncating HTML is hard, right? The "right way" to do it would've been to parse the HTML, and then modify the DOM, and then re-generate markup from there. But that's not what I did.
Here's an exclusive look at how the Cloudflare worker code did it:
body = body.replace(
/\(amos content-start\)((?:.|\n)*?)\(amos content-end\)/,
(_, content) => {
let teaserRe = /<div class="markdown">(.|\n)*?<p>((.|\n)*?)<\/p>(.|\n)*?<p>((.|\n)*?)<\/p>(.|\n)*?<p>((.|\n)*?)<\/p>(.|\n)*?<p>((.|\n)*?)<\/p>/;
let teaser = teaserRe.exec(content);
if (teaser && teaser.length > 0) {
teaser = `${teaser[0]}</div>`; // gotta close the markdown div
} else {
teaser = "";
}
// etc.
Just take the first four paragraphs!
Not going to lie, I'm awful proud of that one. It's so terrible. It has that everybody stand back energy. But it worked great.
For the login flow, well, Patreon has an OAuth 2 API, so that part was easy. It's just simple HTTPS requests!
Here it is redirecting to the Patreon login URL:
async function handleOAuthLogin(url) {
let u = new URL("https://patreon.com/oauth2/authorize");
let q = u.searchParams;
q.set("response_type", "code");
q.set("client_id", config.OAUTH.clientID);
q.set("redirect_uri", config.OAUTH.redirectURI);
q.set("scope", "identity identity.memberships");
return new Response("Redirecting...", {
status: 307,
headers: {
location: u.toString(),
"set-cookie": cookie.serialize(
"return_to",
url.searchParams.get("return_to") || "/"
)
}
});
}
And here it is handling the OAuth callback:
async function handleOAuthCallback(url, request) {
let code = url.searchParams.get("code");
let postParams = new URLSearchParams();
postParams.set("code", code);
postParams.set("grant_type", "authorization_code");
postParams.set("client_id", config.OAUTH.clientID);
postParams.set("client_secret", config.OAUTH.clientSecret);
postParams.set("redirect_uri", config.OAUTH.redirectURI);
const tokenRes = await fetch("https://www.patreon.com/api/oauth2/token", {
method: "POST",
body: postParams.toString(),
headers: {
"content-type": "application/x-www-form-urlencoded"
}
});
if (tokenRes.status !== 200) {
return new Response(
`Patreon integration error: returned HTTP ${tokenRes.status}`,
{
status: 412
}
);
}
const tokenPayload = await tokenRes.json();
let location = "/";
{
let c = request.headers.get("cookie");
if (c) {
let cookies = cookie.parse(c);
if (cookies.return_to) {
location = cookies.return_to;
}
}
}
let cookieExpiration = new Date();
cookieExpiration.setDate(cookieExpiration.getDate() + 31); // about a month
return new Response("Signed in successfully...", {
status: 307,
headers: {
"set-cookie": cookie.serialize(
"credentials",
JSON.stringify(tokenPayload),
{
expires: cookieExpiration
}
),
location: location
}
});
}
HTTP 412 is "Precondition failed".
It's probably the wrong status code for the job, but oh well.
One thing I didn't want to do is maintain a user database. In fact, any kind of persistent storage felt too much for me at this point. So I stored the Patreon credentials right in the cookie.
And then, for every request of logged in users, I just used those to retrieve their current tier. That's a lot of API requests. Sorry, Patreon!
async function getProfileInfo(request, logLines) {
let access_token = null;
let cookieHeader = request.headers.get("cookie");
if (cookieHeader) {
logLines.push(`has cookie`);
let cookies = cookie.parse(cookieHeader);
if (cookies.credentials) {
logLines.push(`cookie has credentials`);
let credentials = JSON.parse(cookies.credentials);
if (credentials && credentials.access_token) {
access_token = credentials.access_token;
logLines.push(`credentials has access_token ${access_token}`);
}
}
}
let url = new URL(request.url);
if (url.searchParams.get("access_token")) {
access_token = url.searchParams.get("access_token");
logLines.push(`access_token overwritten by search param: ${access_token}`);
}
if (!access_token) {
logLines.push(`no access token, giving up`);
return null;
}
logLines.push(`using access token ${access_token}`);
let identityURL = new URL(`https://www.patreon.com/api/oauth2/v2/identity`);
identityURL.searchParams.set(
"include",
[
"memberships",
"memberships.currently_entitled_tiers",
"memberships.campaign"
].join(",")
);
identityURL.searchParams.set("fields[member]", "patron_status");
identityURL.searchParams.set("fields[user]", "full_name,thumb_url");
identityURL.searchParams.set("fields[tier]", "title");
logLines.push(`GET ${identityURL}`);
let identityRes = await fetch(identityURL.toString(), {
headers: {
authorization: `Bearer ${access_token}`
}
});
logLines.push(`HTTP ${identityRes.status}`);
if (identityRes.status != 200) {
logLines.push(`Could not get identity, giving up`);
return null;
}
let identityPayload = await identityRes.json();
const res = {
identityPayload
};
logLines.push([`identityPayload`, identityPayload]);
let store = new JsonApiDataStore();
let user = store.sync(identityPayload);
res.profile = {
fullName: user.full_name,
thumbURL: user.thumb_url
};
logLines.push(`profile:`);
logLines.push(res.profile);
logLines.push(`got ${user.memberships.length} memberships`);
let member = user.memberships.find(
m => m.campaign.id == config.PATREON.campaignID
);
if (member) {
let numTiers = member.currently_entitled_tiers.length;
logLines.push(
`entitled to ${member.currently_entitled_tiers.length} tiers`
);
if (numTiers == 0) {
logLines.push(`not a patron (just a follower?)`);
} else {
res.tier = member.currently_entitled_tiers[0];
}
} else {
logLines.push(`not a member of campaign ${config.PATREON.campaignID}!`);
if (user.id == config.PATREON.creatorID) {
logLines.push(`but is the creator.`);
res.tier = { title: "Creator" };
} else {
logLines.push(`and not the creator, giving up`);
}
}
return res;
}
Patreon's API v2 is extremely flexible, as it lets you query the exact fields you want using the JSON API standard. The jsonapi-datastore npm package was invaluable for that.
It did take a bit of trial and error to find exactly what scopes to request, and how to find campaign information. That's what all the logging is about.
Speaking of logging - that logLines array? Turns out - at least back when
I tried - it was a bit awkward to debug Cloudflare workers. So I had to
find.. ways to do it. I had a debug endpoints that would dump the whole log
(and the result) of getting credentials as a JSON object.
With that done, it was just a matter of... comparing dates, and doing a lot more search and replace on the hugo-generated HTML to make sure the gate worked properly.
Another thing I'm real proud of is the friend codes / friend link system.
As I've stated repeatedly, the main reason I want to write stuff is to share knowledge. So it made sense to me to be... liberal with access control.
But again, I didn't want to use any sort of server-side, persistent storage. So generating tokens and saving them server-side to be validated later was not an option for me.
So I found a way to generate codes that:
- Expire after 48 hours
- Contain the name of the person who generated the friend code (but not in plain text)
- Can only be used for a single page
- Can be validated by the Cloudflare worker without any server-side storage.
I'm not going to go into too many details, because this is definitely "security by obscurity" - there are no secrets involved in generating those codes, to make them just a tiny bit shorter.
I know, I know! You're screaming internally. But the threat model is as follows; the worst thing that can happen with those friend codes is: someone gets early access to one of my articles. That's still good business.
So, if you're out there, and you manage to reverse engineer how the friend code system works, and you manage to generate your own, well:
- You've owned your early access!
- Please contact me with how you did it.
That's about all the tricks I used for the hugo setup. The rest is your run of the mill static site generator business, so I'm not going to bore you with that.
Moving away from hugo
But I wanted more. And also, in general, I've been pretty open about my desire to move away from Go. It goes further than that - not only would I like to avoid writing any more Go code, I would also like to avoid using tools written in Go.
That's not entirely feasible - I haven't found great substitutes, for example, for lego or yay. When I need to extract archives, I find myself using butler a lot of the time. I could go on.
I'm not trying to be an absolutist. But for example, hugo's templating syntax is pretty much the text/template package. It's... opinionated, and not really my cup of tea.
So I was excited to see there was a viable hugo competitor written in Rust - zola. (There are others - but that's the one I went for).
I tried it for a bit, experienced some difficulties with it, and ended up deciding that I would try something else, for a change. For once, I wouldn't try to bend to someone else's defaults.
I would write something "from scratch".
From scratch?
Yeah! I mean... sorta.
According to my Cargo.lock file, my website currently depends on 364
crates. So it's really about standing on the shoulder of a carefully-curated
set of giants.
364 may seem like a lot (and in a way, it is), but please reserve your judgement until after you've heard about everything it does.
So I started making a list of features I wanted. This is the dream scenario, right? Being both the user and the developer. The end result would definitely not be the most "user-friendly" thing, but it would work great for me.
I was brainstorming with a friend, who told me:
but i will point out that this will delay anything else you want to do by at least 6 weeks
Well, joke's on them, because I got it done in two weeks.
Being under constant pressure to realize someone else's prediction was probably very helpful in not giving in to scope creep... too much.
But anyway. It shipped. Yay!
So what does it do?
The basic idea
Well, static site generators are pretty much all the same.
Here's what they do:
- Parse all the markdown files
- Extract the frontmatter from all of them, and store the metadata in one big array.
- Parse all the template files
- Parse and compile all the stylesheets (if they have Sass support)
- Evaluate templates to build all the routes of the site.
- Write that to disk
Some of them, like hugo, have a "serve" mode, for development, and in that mode, I believe it doesn't actually write the output to disk, just somewhere in memory, which is better!
But still that's... a lot of work to do. And it's a lot of disk reads/writes.
It always seemed a bit silly to me that, when it comes to content management systems, you either have the "parse everything into an array" approach (static site generators), or the "database is the single source of truth" approach.
Couldn't there be... a middle ground?
So hey, SQLite has been around for.. twenty years now. And they've pledged to maintain it for another thirty.
SQLite is not very good at multiple concurrent writers - you want something a little more beefy for that, maybe PostgreSQL or... nope that's it. You want PostgreSQL for that.
But that's not the workload I have. I mostly need multiple concurrent readers, with some rare writes, and I'd like to minimize disk I/O, and I'd like to make some queries. And SQLite is great at that.
But I still wanted "a folder of markdown files" to be the single source of truth. I don't want "losing the content database" to be a thing I need to look out for. I don't want to deal with backups any further than "that git repository has local copies on at least three of my personal machines and it's on GitHub somewhere".
Also, I don't want to deal with migrations too much. SQLite is actually not great at that part. It's not impossible, it's just not as nice as PostgreSQL.
So, first step: crawl the content directories and find all the files. Okay, there is a crate for that - ignore.
Next step: read the contents of all those files, and hash them. From the start, I wanted to allow incremental builds. Some static site generators don't have them, and it makes iterating on an article extremely painful. Like, several seconds from saving an article to seeing a change.
So crawling goes like this: ignore walks a bunch of directories, like
content/, static/, sass/, etc. Instead of doing a stat on each entry,
it uses the metadata given by the directory walking APIs of each operating
system, and yields Entry structs:
pub struct Entry {
pub disk_path: PathBuf,
pub logical_path: String,
pub size: u64,
}
The disk_path is the absolute path of the file on disk, for example
C:\msys64\home\amos\ftl\fasterthanli.me\content\articles\a-new-website-for-2020\index.md.
The logical_path is a forward-slash path, relative to the base directory,
for example content/articles/a-new-website-for-2020/index.md.
Those entries are sent to a std::sync::mpsc::Sender, and the receiving end is turned into a parallel iterator with rayon:
pub fn walk_assets(config: &Config, sink: Sender<WalkerEvent>) -> Result<()> {
let (tx, rx) = channel();
let mut walk_result = Ok(());
let mut send_result = Ok(());
rayon::scope(|s| {
let walk_result = &mut walk_result;
let send_result = &mut send_result;
s.spawn(move |_| {
*walk_result = (|| -> Result<()> {
for &prefix in &["content", "static", "sass", "templates"] {
walk_dir(config, prefix, |entry| {
tx.send(entry)?;
Ok(())
})?;
}
Ok(())
})();
});
*send_result = rx
.into_iter()
.par_bridge()
.map_with(sink, process_entry)
.collect::<Result<_>>();
});
walk_result?;
send_result?;
Ok(())
}
From there, using as many threads as it takes to use all CPU cores, each entry is hashed. Since we know we're going to read the whole file, I opted to let the kernel do its own memory management by using the memmap crate:
pub fn process_entry(sink: &mut Sender<WalkerEvent>, entry: Entry) -> Result<()> {
log::trace!("Walk found item {}", entry.logical_path);
let contents: Box<dyn Deref<Target = [u8]> + Send + Sync> = if entry.size == 0 {
Box::new(EmptyContents {})
} else {
let file = File::open(&entry.disk_path)?;
let mm = unsafe { MmapOptions::new().map(file.file())? };
Box::new(mm)
};
let hash = entry.hash(&contents)?;
let item = WalkerItem {
inline: entry.is_inline(),
path: entry.logical_path,
disk_path: entry.disk_path,
hash,
size: entry.size as i64,
contents,
};
sink.send(WalkerEvent::Add(item))?;
Ok(())
}
Why the EmptyContents dance? Well, it turns out you can't memmap
an empty file.
Now - I said I wanted to minimize disk I/O, didn't I? So for all text input files, I want to store the contents directly in the SQLite database, and have it manage caching.
However, for other types of files, like png images or mp4 videos, I'd rather have those on disk, so as to not clutter the sqlite content database unnecessarily:
impl Entry {
pub fn is_inline(&self) -> bool {
match self.disk_path.extension() {
Some(x) => match x.to_string_lossy().as_ref() {
"md" | "scss" | "html" | "json" | "liquid" => true,
_ => false,
},
_ => false,
}
}
}
So inline input files have their context as a TEXT column directly
in the input_files database, and all the other files are copied into
the .futile/cache directory:
$ ls -l .futile/cache | head .rw-r--r-- 1.3M amos 26 Jun 10:45 0a8c795439e4e15e .rw-r--r-- 29k amos 26 Jun 10:45 0a44ef526393197d .rw-r--r-- 18k amos 26 Jun 10:45 0a68cb0715b45b9f .rw-r--r-- 49k amos 26 Jun 10:45 0a90248acba23047 .rw-r--r-- 2.1k amos 26 Jun 10:45 0a536673aa0ecf00 .rw-r--r-- 30k amos 26 Jun 10:45 0aedf1b5fdb1300e .rw-r--r-- 2.4k amos 26 Jun 10:45 0b0bc534c167203c .rw-r--r-- 32k amos 26 Jun 10:45 0b5b24873117badb .rw-r--r-- 23k amos 26 Jun 10:45 0b58bdf032f45479 .rw-r--r-- 15k amos 26 Jun 10:45 0b87e6bfdd5e9e7a
Wait, does that mean the server has two copies of every static asset?
Yes it does! And with the amount of storage you can get for cheap in 2020, that isn't going to start being a problem before 2050, probably. And if it does become a problem and I really need to halve my storage requirements, I could just store the whole thing on a ZFS pool, which does deduplication.
Before you ask: doing symbolic links is not an option, for reasons that will become clear later.
For the hash, I didn't need a cryptographic one. Just something really fast, and with a low collision chance. So I picked seahash:
impl Entry {
pub fn hash(&self, contents: &[u8]) -> Result<String> {
Ok(format!("{:016x}", seahash::hash(contents)))
}
}
Also - I'm storing it as a string. Even though a seahash is an u64.
Turns out - sqlite can't store u64, only i64. And the templating
engine I picked only supports i32, nothing bigger.
So the canonical representation for an input file's hash is a fixed-length string. And this enables other nice things.
For example, the primary key for the input_files table is the hapa TEXT
column - a hash+path.
$ sqlite3 .futile/content.db SQLite version 3.32.2 2020-06-04 12:58:43 Enter ".help" for usage hints. sqlite> SELECT hapa FROM input_files LIMIT 3; 004598c9cc589ba6,static/img/the-simplest-shared-library/ugdb-mov-from-dylib.png 0065c77a4eddd148,templates/shortcodes/figure.html.liquid 0069d86f920fb6ae,static/img/rust-lifetimes/v8-was-freed.png
So, when we're crawling for the first time, we do a whole lot of inserts
into the input_files table. All in a transaction, and with write-ahead
logging enabled, for speed.
The next time around, for each file we crawl and hash, we check if it's already in the DB. If it is, great! If not, we insert it.
Everything in futile - that's what I named my "almost-static site server" -
revolves around revisions. A revision is simply a version of the content
that we can serve.
The next step is to construct a set of "revision files" - all the input files
that are relevant for a specific revision. Why do that? Because I want to be
able to serve the whole website using only .futile/cache/ and .futile/content.db.
Why? When deploying a new revision, things are moved around - .md files
get changed, .png files get renamed, all sorts of things happen on disk.
And when deploying a static site to S3, that's a problem. In the middle of
a deployment (with s3cmd), you're serving an invalid version of your site.
Maybe the HTML pages get uploaded before the relevant PNG images are - so if someone visits the website at that point, they get broken images.
With futile, that doesn't happen. Once a revision is built, only the DB
and cache are used to serve it - you could wipe out anything else. When
I deploy, the production server pulls from the Git repository, and
nothing breaks because those files aren't used to serve content.
And that's why symbolic links wouldn't work.
So, let's summarize - when futile starts up, it:
- crawls all files
- normalizes their paths
- hashes them
- updates the
input_filestable in the content DB- it does only inserts, no deletes
But what happens if the input files change while futile is running?
Well, both in development and in production futile watches for file changes using the notify crate. It debounces those events - if it hasn't received any changes in 250 milliseconds, it starts making another revision using that knowledge.
If it's notified about a file changing, it re-hashes it and sees if it needs
to be inserted into input_files. Sometimes that's unnecessary, as the file
was only touched, not actually changed.
If it's notified about a file being removed... it doesn't actually change
anything to the input_files table - it just won't be part of the
revision_files set for the next revision.
If it's notified about a directory changing, it just walks it, again, with
the ignore crate.
This is exceedingly fast. Both for development and for production deploys. And it wouldn't get any slower if there were many more pages in the database. It's only rebuilding what it needs to.
And another cool thing? If the revision fails to build - it just keeps serving the previous "known good" one.
So, what are the next step? Well, once we've got input_files and
revision_files all filled up, we still have many things to do.
For every input_files for which there exists a revision_files for the
revision we're currently building, and which has a hapa that ends in .md,
we insert into the pages table, as needed.
What does the pages table contain?
- Everything from the frontmatter, including
title,date,exclusive_until,tags, etc. - A content offset
This is very fast, for a bunch of reasons. First, the whole contents of all
those .md files is already in the database - they're inline input_files.
Second, I'm using a hand-rolled parser to identify where the frontmatter starts, and where it ends.
Third, I'm using the toml and serde crate to parse the front matter contents, both of which are fast.
Here's how the frontmatter parser looks:
enum State {
SearchForStart,
ReadingMarker { count: usize, end: bool },
ReadingFrontMatter { buf: String, line_start: bool },
SkipNewline { end: bool },
}
#[derive(Debug, thiserror::Error)]
enum Error {
#[error("EOF while parsing frontmatter")]
EOF,
}
impl FrontMatter {
pub fn parse(name: &str, input: &str) -> Result<(FrontMatter, usize)> {
let mut state = State::SearchForStart;
let mut payload = None;
let offset;
let mut chars = input.char_indices();
'parse: loop {
let (idx, ch) = match chars.next() {
Some(x) => x,
None => return Err(Error::EOF)?,
};
match &mut state {
State::SearchForStart => match ch {
'+' => {
state = State::ReadingMarker {
count: 1,
end: false,
};
}
'\n' | '\t' | ' ' => {
// ignore whitespace
}
_ => {
panic!("Start of frontmatter not found");
}
},
State::ReadingMarker { count, end } => match ch {
'+' => {
*count += 1;
if *count == 3 {
state = State::SkipNewline { end: *end };
}
}
_ => {
panic!("Malformed frontmatter marker");
}
},
State::SkipNewline { end } => match ch {
'\n' => {
if *end {
offset = idx + 1;
break 'parse;
} else {
state = State::ReadingFrontMatter {
buf: String::new(),
line_start: true,
};
}
}
_ => panic!("Expected newline, got {:?}",),
},
State::ReadingFrontMatter { buf, line_start } => match ch {
'+' if *line_start => {
let mut state_temp = State::ReadingMarker {
count: 1,
end: true,
};
std::mem::swap(&mut state, &mut state_temp);
if let State::ReadingFrontMatter { buf, .. } = state_temp {
payload = Some(buf);
} else {
unreachable!();
}
}
ch => {
buf.push(ch);
*line_start = ch == '\n';
}
},
}
}
// unwrap justification: option set in state machine, Rust can't statically analyze it
let payload = payload.unwrap();
let fm: Self = toml::from_str(&payload)
.map_err(|e| Report::from(e).wrap_err(format!("while parsing {:?}", name)))?;
Ok((fm, offset))
}
}
This is probably not the smartest way to do it. But it works, and it's real fast.
So, not only does it return the frontmatter data as a Rust struct, it also returns an offset - where the markdown actually starts.
The result is inserted into the pages table - which also has a hapa
(hash+path) as its primary key. But there are other tables we have to care
about.
For example, I changed the URL scheme a little when making futile. Previously,
all my articles had URLs like /blog/:year/:slug. Now, I've split everything
into /articles/:slug, and /series/:serie-slug/:part-slug.
But I don't want the old links to be dead! So, each page can have redirects. Here's the frontmatter from one of my most popular article:
date = 2020-02-19T14:30:00Z title = "Working with strings in Rust" aliases = ["/blog/2020/working-with-strings-in-rust/"] tags = ["rust"] [extra] patreon = true
And yes, yes, a command-line tool was written to automatically convert from Hugo frontmatter to futile frontmatter.
Of course. There was a hundred pages to switch over! What did you expect?
So, aliases go into page_aliases (again, primary key is a hapa), tags go
into page_tags - but also denormalized into the tags column of pages,
as a JSON array.
Also, anything under [extra] goes into the extra column of pages, as a
JSON object.
There's a couple other page-related tables which I'll come to later.
Okay - so we've got a bunch of pages. What do we do with them? We create
routes! There's a bunch of different route kinds - thanks serde-repr.
#[derive(Serialize_repr, Deserialize_repr, Debug, Clone, Copy, TryFromPrimitive)]
#[repr(u32)]
pub enum RevisionRouteKind {
Unknown = 0,
StaticAsset = 1,
Page = 3,
Stylesheet = 4,
PageRedirect = 5,
}
Static assets are kinda easy. We just need to find all input files that
came from the static/ folder. And everything is in a database! So what do
we do? We query for them!
There's a couple crates involved here:
- rusqlite, an ergonomic SQLite wrapper for rust
- serde_rusqlite, which allows serializing to query parameters, and deserializing from rows
- r2d2 and r2d2_sqlite for connection pools (not shown here)
Here's the entire create_static_asset_routes function:
/// Create routes for all static assets
pub fn create_static_asset_routes(db: &Connection, rev_id: &str) -> Result<()> {
#[derive(Deserialize, Debug)]
struct Row {
hapa: Hapa,
}
let mut insert_route = RevisionRoute::insert_prepare(&db)?;
let mut stmt = db.prepare(
"
SELECT input_files.hapa
FROM input_files
WHERE EXISTS (
SELECT 1
FROM revision_files
WHERE revision_files.hapa = input_files.hapa
AND revision_files.revision = ?1
)
AND input_files.hapa NOT REGEXP '[.]md$'
",
)?;
let mut rows = from_rows::<Row>(stmt.query(params![&rev_id])?);
while let Some(row) = rows.next() {
let row = row?;
insert_route(&RevisionRouteIn {
revision: &rev_id,
route_path: row.hapa.path().trim_start_matches("static/"),
parent_route_path: None,
kind: RevisionRouteKind::StaticAsset,
hapa: &row.hapa,
template: None,
})?;
}
Ok(())
}
And just like that, we have routes for /img/logo.png that point to
static/img/logo.png.
One could argue this WHERE EXISTS should be a JOIN instead.
And one might well be right. But the opportunities for optimization are legion. I had to stop myself a hundred times over.
It's still wicked fast for now. And if it's not fast enough later, there's still time to think of other strategies - there's nothing inherent to the design of futile that would make it slow.
But wait a minute... REGEXP?
Astute SQLite users may notice that, while it
is valid syntax, regexp support in SQLite is not built-in. There's a
loadable module for it, but I don't want to worry about .so files.
Luckily, rusqlite lets us augment SQLite with Rust functions, so, thanks to
the regex crate...
fn make_db_pool(path: &Path, migrations: Vec<Box<dyn Migration>>) -> Result<Pool> {
let on_init = |db: &mut Connection| {
db.pragma_update(None, "journal_mode", &"WAL".to_string())?;
db.create_scalar_function(
"regexp",
2,
FunctionFlags::SQLITE_UTF8 | FunctionFlags::SQLITE_DETERMINISTIC,
move |ctx| {
assert_eq!(ctx.len(), 2, "called with unexpected number of arguments");
let regexp: Arc<Regex> =
ctx.get_or_create_aux(0, |vr| -> Result<_> { Ok(Regex::new(vr.as_str()?)?) })?;
let is_match = {
let text = ctx
.get_raw(1)
.as_str()
.map_err(|e| rusqlite::Error::UserFunctionError(e.into()))?;
regexp.is_match(text)
};
Ok(is_match)
},
)?;
Ok(())
};
let manager = SqliteConnectionManager::file(path).with_init(on_init);
let pool = Pool::new(manager)?;
{
let mut db = pool.get()?;
migrations::migrate_all(&mut db, migrations)?;
}
Ok(pool)
}
Boom. REGEXP support, backed by a very fast engine.
I mean.. I haven't benchmarked the regex crate, but look at the default
Cargo features - there's even
SIMD in there, for crying out loud.
And sure, using REGEXP in a query condition means doing a linear scan.
That's okay - if performance becomes an issue, I could always add another
column to input_files, and index on that.
Again - I haven't been able to think of any potential performance problems in futile that can't be solved with more denormalization.
So, if you're the type to spot all the little inefficiencies - let it go. God, it's full of compromises in there. I know. I know. Focus on the cool stuff!
Okay, so, static asset routes are done, what about page routes and redirect routes?
It's similarly easy - just a few queries:
pub fn create_page_routes(db: &Connection, rev_id: &str) -> Result<()> {
let rev_id = &rev_id;
let mut insert_route = RevisionRoute::insert_prepare(&db)?;
let pages = Page::for_revision(&db, &rev_id)?;
for page in &pages {
insert_route(&RevisionRouteIn {
revision: &rev_id,
kind: RevisionRouteKind::Page,
route_path: &page.route_path,
parent_route_path: do_parent_path(&page.route_path)
.as_ref()
.map(|x| -> &str { x }),
template: page.template.as_ref().map(|x| -> &str { x }),
hapa: &page.hapa,
})?;
}
// insert redirects for aliases
{
#[derive(Deserialize)]
struct Row {
hapa: Hapa,
route_path: String,
}
let mut stmt = db.prepare(
"
SELECT *
FROM page_aliases
WHERE EXISTS (
SELECT 1 FROM revision_files
WHERE revision_files.revision = ?1
AND revision_files.hapa = page_aliases.hapa
)
",
)?;
let mut rows = from_rows::<Row>(stmt.query(params![&rev_id])?);
while let Some(row) = rows.next() {
let row = row?;
insert_route(&RevisionRouteIn {
revision: &rev_id,
kind: RevisionRouteKind::PageRedirect,
route_path: &row.route_path,
parent_route_path: None,
hapa: &row.hapa,
template: None,
})?;
}
}
Ok(())
}
If you're wondering how route paths are constructed: I wanted first-class support for "colocated assets", which means that whereas I previously had:
content/blog/2020/doing-stuff.mdstatic/img/doing-stuff-1.png
I now have:
content/articles/doing-stuff/index.mdcontent/articles/doing-stuff/doing-stuff-1.png
So, to_route_path is "index.md-aware":
pub fn to_route_path(path: &str) -> Result<Cow<str>> {
let route_path = path
.trim_start_matches("content")
.trim_end_matches("/index.md")
.trim_start_matches("/");
let ext_re = regex::Regex::new("[.][^.]+$")?;
let route_path = ext_re.replace(route_path, "");
Ok(route_path)
}
Which leaves us with stylesheet routes.
There's not much competition there - writing pure CSS is still a hassle for a bunch of reasons, and SASS is queen.
I didn't want to rely on either the JavaScript or C sass implementations, though. By chance, I didn't have to! The rsass crate supports a good enough subset for my needs.
There's one tiny issue with it - its API doesn't allow supplying partials
via a trait. It expects a Path, so it can do the file lookup itself.
So, fair enough, let's just use a temporary folder. Here's the whole stylesheet compilation pipeline:
/// Use revision files to compile "sass/style.scss", using a temporary
/// directory to let it access partials.
pub fn compile_stylesheets(config: &Config, db: &Connection, rev_id: &str) -> Result<()> {
let sass_tmp_dir = config.cache_dir().join(format!("tmp-sass-{}", &rev_id));
let _deferred_remove = RemoveDirAllOnDrop {
path: sass_tmp_dir.clone(),
};
let mut stmt = db.prepare(
"
SELECT hapa, data
FROM input_files
WHERE input_files.hapa REGEXP ',sass/[^.]+.scss$'
AND EXISTS (
SELECT 1 FROM revision_files
WHERE revision_files.hapa = input_files.hapa
AND revision_files.revision = ?1
)",
)?;
#[derive(Deserialize, Debug)]
struct Row {
hapa: Hapa,
data: String,
}
let mut rows = from_rows::<Row>(stmt.query(params![&rev_id])?);
while let Some(row) = rows.next() {
let row = row?;
let mut dest_path = sass_tmp_dir.clone();
for tok in row.hapa.path().split('/') {
dest_path.push(tok);
}
std::fs::create_dir_all(dest_path.parent().unwrap())?;
std::fs::write(&dest_path, &row.data)?;
}
let out = rsass::compile_scss_file(
&sass_tmp_dir.join("sass").join("style.scss"),
Default::default(),
)?;
let mut insert_revision_stylesheet = RevisionStylesheet::insert_prepare(&db)?;
insert_revision_stylesheet(&RevisionStylesheetIn {
revision: &rev_id,
name: "style",
data: std::str::from_utf8(&out)?,
})?;
let mut insert_route = RevisionRoute::insert_prepare(&db)?;
insert_route(&RevisionRouteIn {
revision: &rev_id,
route_path: "style.css",
parent_route_path: None,
kind: RevisionRouteKind::Stylesheet,
hapa: &Hapa::new("", "style"),
template: None,
})?;
Ok(())
}
struct RemoveDirAllOnDrop {
path: PathBuf,
}
impl Drop for RemoveDirAllOnDrop {
fn drop(&mut self) {
if let Err(e) = std::fs::remove_dir_all(&self.path) {
log::warn!("Could not remove temporary dir: {}", e);
}
}
}
Is this a dirty hack? Absolutely.
Did I ship that in production? You better believe it.
Wait, does that mean all stylesheets are recompiled for every revision?
Absolutely cool bear. And it takes 25 milliseconds on a ten-year-old Lenovo X200, out of the ~170 milliseconds it takes it to make an incremental revision.
Again - if it ever becomes a problem, it could be given the heavy caching treatment.
Which brings us to templates.
Oh, templates. Did I go back and forth on that one.
I really liked zola's templating system, tera. But ultimately, after looking at the API design, extension opportunities, and reviewing the code a little, I decided against using it.
The idea behind ramhorns appealed to me a lot too. For starters, dynamite logo. And you can tell extreme care has been taken both in designing the API, and in the implementation itself. Performance! Correctness!
Ultimately, I found the mustache templating
language a bit too limiting, so
I decided to go with liquid instead. Which is
a Rust implementation of the templating language tera is inspired by in the
first place!
But there was an important design question I hadn't solved yet.
I knew I wanted templating - evaluated at runtime - because it was going to take a lot of iteration to get the layout of the website just right, and linking the project was already taking multiple seconds at that point.
If you end up recompiling a project that depends on 364 crates over and over,
and link times have got you down, you may want to give the LLVM linker,
lld, a try.
It's as simple as installing it (pacman -S lld) and slapping this in your
.cargo/config (either in your home directory, or in the project directory):
[target.x86_64-unknown-linux-gnu]
rustflags = [
"-C", "link-arg=-fuse-ld=lld",
]
But what I hadn't thought about was: how was I going to pass data from
futile into the templating engine?
Some templating engines allow registering Rust functions that can be called from the template source. But input variables usually need to be owned by the templating engine.
And liquid, the templating engine I ended up picking, well.. doesn't have
support for functions. What it does let you do though, is define custom
tags, blocks, and filters.
What's a filter?
Well, in a liquid template, you can pipe an expression into... a filter, and get something else, like that:
<p>
The current revision is {{ revision }}.
</p>
<p>
The revision string has {{ revision | size }} characters.
</p>
You can keep piping to your heart's content. And filters not only have an input, they also have positional arguments and keyword arguments.
For example, the date filter takes a format string as
a positional argument:
Published on {{ page.date | date: "%b %e, %Y" }}
So I thought to myself - I have a database. I don't want to query all the information in it and pass it as input variables. Maybe I could use filter to somehow fetch only the information I need?
Say I'm rendering an individual page, and the columns of the relevant
pages row are passed as an input parameter, maybe I could use custom filters
to do something like this:
{{ page | page_markup | markdown }}
Where page_markup is a custom filter that takes an object as input, looks
up its hapa property, makes a DB query, and returns the the part after
content_offset.
And markdown is another custom filter that uses pulldown-cmark to render Markdown to HTML.
And folks, that's exactly what I did.
Except... I started to think of all the filters I'd need to write.
God, I love passages like these.
You can feel the tension mounting.
You know it's building up to something good. Or terrible. Possibly both.
What's that cool bear?
Nothing, nothing, keep going.
Getting a single page's markup was easy. But what about listings? What if I needed to get a list of all the pages with a specific tag? Or a list of all the recent articles? Or the parts of a series? Or the next part of a series?
I would be writing filters until the cows come home. And the cows really don't feel like coming home right now.
Also, writing filters in liquid is quite involved - due to how flexible the API is.
Here's an example filter, that encodes its input as JSON (that was extremely useful while debugging templates):
use crate::templating::convert_errors;
use liquid::ValueView;
use liquid_core::{to_value, Display_filter, Filter, FilterReflection, ParseFilter};
#[derive(Clone, FilterReflection)]
#[filter(
name = "to_json",
description = "Serialize a value to json",
parsed(ToJsonFilter)
)]
pub struct ToJson;
#[derive(Debug, Display_filter)]
#[name = "to_json"]
struct ToJsonFilter {}
impl ParseFilter for ToJson {
fn parse(
&self,
_arguments: liquid_core::parser::FilterArguments,
) -> liquid_core::Result<Box<dyn Filter>> {
Ok(Box::new(ToJsonFilter {}))
}
fn reflection(&self) -> &dyn FilterReflection {
self as &dyn FilterReflection
}
}
impl Filter for ToJsonFilter {
fn evaluate(
&self,
input: &dyn ValueView,
_runtime: &liquid_core::Runtime,
) -> liquid_core::Result<liquid_core::Value> {
convert_errors(|| {
let output = serde_json::to_string_pretty(&input.to_value())?;
Ok(to_value(&output)?)
})
}
Pretty verbose right? And that one doesn't even take arguments!
But nobody say anything bad about liquid, because I love its API. I love
it so much I ended up submitting two pull requests to it. And I quit pull
requests a while ago.
Why did I send pull requests? Well, the first thing I did when playing liquid
is wonder... can we put more serde in it?
Sure, liquid_core::Value implements both serde::Serialize and
serde::Deserialize - which means you can deserialize it from, and serialize
it to, a format like JSON. Or TOML. Or msgpack. Or bincode. Or one of the other
hundred formats implemented against serde.
But what I wanted to do... was take a &dyn liquid_core::ValueView, and
"translate it" into one of my own structs.
A struct just like that:
#[derive(Deserialize, Debug)]
struct FilterInput<'a> {
#[serde(borrow)]
hapa: Cow<'a, str>,
}
And yes, you're reading it right, I wanted to borrow from liquid. While
it's evaluating a filter, it's giving us a dyn ValueView, not an owned
Value - which make sense, because you can pipe the same variable to
different filters.
Because I wanted that, I did the only logical thing to do... I wrote a
ValueView deserializer.
Here's a bit of it:
pub struct ValueDeserializer<'de> {
input: &'de (dyn ValueView + 'de),
}
impl<'de> ValueDeserializer<'de> {
pub fn from_value(input: &'de (dyn ValueView + 'de)) -> Self {
Self { input }
}
}
pub fn from_value<'a, T>(v: &'a dyn ValueView) -> Result<T, Error>
where
T: Deserialize<'a>,
{
let mut deserializer = ValueDeserializer::from_value(v);
let t = T::deserialize(&mut deserializer)?;
Ok(t)
}
impl<'de, 'a> de::Deserializer<'de> for &'a mut ValueDeserializer<'de> {
type Error = Error;
fn deserialize_any<V>(self, _visitor: V) -> Result<V::Value, Self::Error>
where
V: serde::de::Visitor<'de>,
{
return Err(Error::Unimplemented);
}
fn deserialize_struct<V>(
self,
_name: &'static str,
_fields: &'static [&'static str],
visitor: V,
) -> Result<V::Value, Self::Error>
where
V: serde::de::Visitor<'de>,
{
let input = self.input.as_object().ok_or(Error::ExpectedObject)?;
visitor.visit_map(ObjectDeserializer::new(input))
}
fn deserialize_str<V>(self, visitor: V) -> Result<V::Value, Self::Error>
where
V: serde::de::Visitor<'de>,
{
let scalar = self.input.as_scalar().ok_or(Error::ExpectedScalar)?;
match scalar.into_cow_str() {
Cow::Borrowed(s) => visitor.visit_borrowed_str(s),
Cow::Owned(s) => visitor.visit_string(s),
}
}
// etc.
}
So my filters borrow their input from liquid templates. It's pretty great.
Anyway.
Point is - I didn't want to be writing a hundred filters. It would've kinda defeated the purpose of quick iteration, because every new filter is Rust, so I need to recompile and link the whole thing, which, again, takes several seconds even on my good laptop, the 2020 Core i7 one.
So I thought... hey... you know what's really good at querying stuff... and already has a query language... that I know how to write... somewhat...
SQLite.
SQLite is good at querying stuff.
So I made a query filter.
Bwahahahaha there it is.
Wanna see me list all the pages for a given tag?
{% capture pages_sql %}
SELECT pages.*
FROM pages
JOIN revision_routes ON revision_routes.hapa = pages.hapa
WHERE revision_routes.revision = ?1
AND (
revision_routes.parent_route_path = 'articles'
OR revision_routes.parent_route_path GLOB 'series/[^/]*'
)
AND EXISTS (
SELECT 1
FROM page_tags
WHERE page_tags.hapa = pages.hapa
AND page_tags.name = ?2
)
{% unless config.drafts %}
AND NOT pages.draft
{% endunless %}
{% unless config.future %}
AND pages.date < datetime('now')
{% endunless %}
ORDER BY pages.date DESC
{% endcapture %}
{% assign pages = pages_sql | query: revision, tag_name %}
Ohh yes.
And you know, the whole content database is there, so you can query whatever you want. With SQL. And proper argument passing. In the templates.
So for example, futile doesn't know how to list the parts of a series.
The templates do it. The templates even do pagination, with LIMIT and
OFFSET. The templates list all existing tags, by querying the page_tags
table.
Once I got all that up and running, I spent a large amount of time iterating on templates, adding all the navigation I wanted - and more!
Do you know how search works for statically-generated websites?
99% of the time, it goes something like:
- Dump all the content in a JSON file
- Tokenize maybe?
- Pray to the lunar gods
This is... it's a solution alright. It's not great if you have a lot of content, which, hello, that's me.
In that case, there's the 1% solution - be smart and using something like, oh, I don't know, Rust and Wasm and bloom filters to do client-side full-text search. That's what tinysearch does.
And that's, you know, another solution. It has drawbacks, like: the index takes forever to generate, because it involves compiling a Rust crate to wasm - the index is jammed directly in the "binary".
Also, it is full text search, but it's not able to show which part of the page matched - it can't show snippets, or highlight. Because it doesn't have the actual contents of the page, it only has a filter, which tells it whether it matches or not.
Finally, I'm in a funny situation where I want a different set of content to be searchable, depending on:
- The Patreon tier you're subscribed to
- What date it currently is
If I had a single index, folks could search in the "timed exclusive" content, and that's, well it's not a showstopper, it's just not great.
If I had two indices, I would need to regenerate the "public" one anytime an article's time-lock expired.
So anyway, that's why the previous hugo-based setup didn't have search.
But that was then... and this is now... and now, we have SQLite.
And while I wasn't looking (okay, in 2015), SQLite got really good full-text search support. This "really good" is in the context of what statically-generated website usually have.
So, we have full-text search, with proper unicode tokenization:
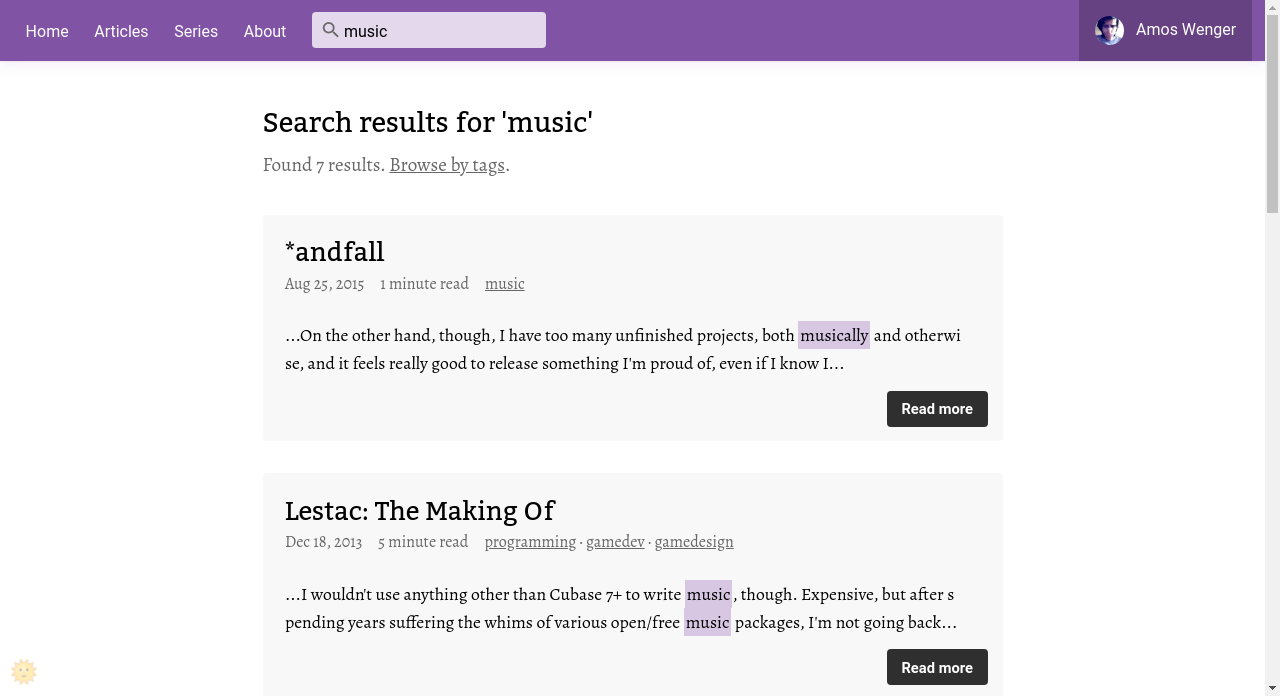
I'm really excited about that feature. No amount of taxonomies can really replace full-text search. As the amount of content on the website continues to grow, I want people to be able to quickly find articles where I talked about a specific crate, or where I used profanity.
Since we're talking about features - "log in with Patreon" was relatively straight-forward to implement. I haven't even talked about the server itself yet!
The HTTP content is served with tide. And I do requests to Patreon using surf. I decode responses with serde_json, and I navigate through JSON API payloads with jsonapi.
I changed up the Patreon implementation a little, so it only makes requests to the Patreon API now and then, instead of on every request. A nice side effect is that page loads are faster for logged-in users.
Speaking of server - there are some nice things in development that are disabled in production. For example, if I get something really wrong, say, in an SQL query, I get a nice 500 page, with color-backtrace in the browser - and error context, courtesy of jane-eyre.
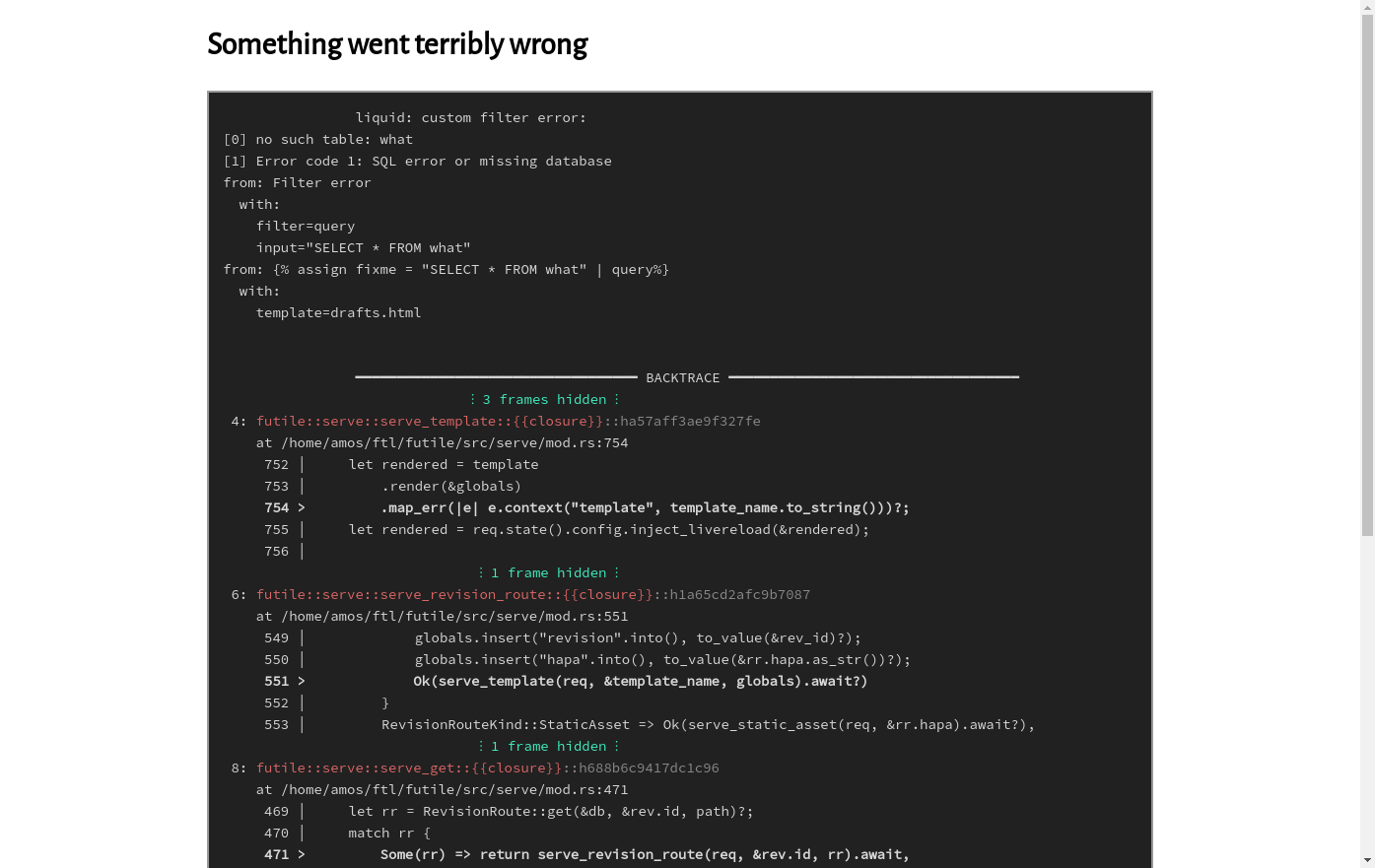
How does it work? Well, termcolor has a WriteColor trait that you can just implement, and have it write, y'know, HTML spans instead of ANSI escape codes.
Also - live reload! That one was easy - I just used tide's built-in support for server-sent events.
A tiny bit of javascript is injected on all pages in development, which listens for server-sent events. Any time the site switches to a new revision, it also broadcasts a message to all SSE clients, and the page reloads itself.
Even the 500 page reloads itself!
Friend codes work roughly the same way - although I changed up the secret recipe a little. Also, now, instead of having to click on a button to generate a friend link, it shows up at the top of every page that is a timed exclusive - for Silver patrons and above. So it's just a copy/paste away at all times.
And then there's a lot of quality of life stuff that I forget, because I got used to it so fast.
But here's one thing I haven't forgotten.
Typically, simple statically-generated website setups don't come with cache busting out of the box. So if you deploy a new stylesheet, or an update to an image, and you have a caching proxy like Cloudflare in front of it, you're going to have to clear its cache manually - and even then, that won't clear the visitors' browser cache.
Because the path of the new resource is the same as the old resource, and since it's a static resource, it's set to be cached for some time.
Cache-busting is the idea of adding a version, or a hash, to the path of static resources, so that when the resource changes, the path changes.
And of course, you can do that in other static site generators - hugo has, uhh, pipes? And I'm sure zola's got something as well. But here are things I don't want to do:
- I don't want to use shortcodes for every image I insert in my articles. Standard markdown is good enough for images.
- I don't want the site builder to fingerprint images when it's rendering an article
And luckily, with futile, I don't have to do either.
Using one of Cloudflare's crates, lol_html,
I'm able to post-process all the markdown-rendered HTML, and look for <img>
tags with a relative src attribute.
If I can find a corresponding local resource, I generate a cachebusted URL,
turning, say, search.png into
content/articles/a-new-website-for-2020/search.f8a8b75e05aff0b9.png.
And the futile router takes care of finding the original resource, and serve
it.
That's not the only rewriting I do with lol_html! For example, I add
loading=lazy to all <img> and <video> tags. And since the old
resource paths (with the hash of the previous version of an image asset)
are still valid, images don't suddenly break when you're scrolling halfway
through a page.
And that's not even all of it! I also use lol_html to truncate HTML.
Remember how the old setup just "found the first four paragraphs" with
regular expressions?
Well, no more.
futile's truncate_html filter counts characters in text nodes, and drops
every node after reaching a maximum amount:
let char_count = AtomicU64::new(0);
let mut skip: bool = false;
let mut rewriter = HtmlRewriter::try_new(
Settings {
element_content_handlers: vec![
element!("*", |el| {
if char_count.load(Ordering::SeqCst) > max {
if el.tag_name() == "p" {
skip = true;
}
}
if skip {
el.remove();
}
Ok(())
}),
text!("*", |txt| {
if matches!(txt.text_type(), TextType::Data) {
char_count.fetch_add(txt.as_str().len() as u64, Ordering::SeqCst);
}
Ok(())
}),
],
..Settings::default()
},
output_sink,
)?;
rewriter
.write(input.as_bytes())
.map_err(|e| liquid_core::Error::with_msg(format!("rewriting error: {:?}", e)))?;
drop(rewriter);
Ok(to_value(&std::str::from_utf8(&output[..])?)?)
That's how the "summaries" are generated in page listings.
Speaking of manipulating markup - there's other tricks in my new bag.
See that beautiful syntax highlighting? I used to use highlight.js on my hugo setup, because when I started using it, it didn't have a built-in syntax highlighter.
Now hugo has its own syntax highlighter, and there's also syntect for Rust (based on TextMate grammars), and I have.... feelings, and emotions, about them, because most syntax highlighters:
- lack flexibility - like, generating
<span>s with colors as inline styles, or having a limited set of grammars - slather SCREAMING RED BACKGROUND on anything it doesn't understand
I actually couldn't get syntect to run at all, but I know that's what zola
uses, and it definitely had both of those shortcomings.
Then I discovered tree-sitter. Which has proper grammars, not, you know, a gigantic pile of regular expressions.
It's not ideal yet - I couldn't find a tree-sitter grammar for X86 Assembly, for example, and I couldn't be bothered to ship the HTML one, but I'm confident that, over time, I would be able to either write those myself, or nerd-snipe others into doing it.
How does that plug into the whole pipeline? Well, pulldown-cmark basically gives you an iterator of events - an event stream if you will.
And you know what happens to iterators around here? They get mapped.
pub fn process_markdown_to_writer<W>(input: &str, langs: Arc<Langs>, w: W) -> Result<()>
where
W: Write,
{
let parser = Parser::new_ext(input, options());
struct Code {
lang: String,
source: String,
}
let mut current = None;
let iter = parser.map(|ev| {
match &ev {
Event::Start(Tag::CodeBlock(CodeBlockKind::Fenced(lang))) => {
current = Some(Code {
lang: lang.to_string(),
source: Default::default(),
});
return Event::Text("".into());
}
Event::End(Tag::CodeBlock(CodeBlockKind::Fenced(_))) => {
if let Some(current) = current.take() {
let mut out: String = String::new();
use std::fmt::Write;
let lang = langs.get(¤t.lang);
write!(&mut out, r#"<pre>"#,).ok();
let tag = lang.map(|l| l.name).unwrap_or(¤t.lang);
if !tag.is_empty() {
write!(
&mut out,
r#"<div class="language-tag">{}</div>"#,
lang.map(|l| l.name).unwrap_or(¤t.lang)
)
.ok();
}
write!(&mut out, r#"<div class="code-container"><code>"#).ok();
if let Err(e) = highlight_code(&mut out, ¤t.source, &lang) {
if !e.benign() {
log::warn!("Highlight error: {}", e);
}
write_code_escaped(&mut out, ¤t.source).ok();
}
write!(&mut out, "</code></div></pre>").ok();
return Event::Html(out.into());
}
}
Event::Text(code) => {
if let Some(current) = current.as_mut() {
current.source.push_str(code);
return Event::Text("".into());
}
}
_ => {}
}
ev
});
html::write_html(w, iter)?;
Ok(())
}
How flexible is tree-sitter-highlight? Extremely!
Enough that I can generate <span> tags with very short class names:
fn highlight_code(
w: &mut dyn std::fmt::Write,
source: &str,
lang: &Option<&Lang>,
) -> std::result::Result<(), HighlightError> {
let lang = lang.ok_or(HighlightError::NoLang)?;
let conf = lang.conf.as_ref().ok_or(HighlightError::NoHighlighter)?;
let mut highlighter = Highlighter::new();
let highlights = highlighter
.highlight(conf, source.as_bytes(), None, |_| None)
.map_err(|e| HighlightError::CouldNotBuildHighlighter(format!("{:?}", e)))?;
for highlight in highlights {
let highlight = highlight.unwrap();
match highlight {
HighlightEvent::Source { start, end } => {
write_code_escaped(w, &source[start..end]).unwrap();
}
HighlightEvent::HighlightStart(Highlight(i)) => {
write!(w, r#"<i class=hh{}>"#, i).unwrap();
}
HighlightEvent::HighlightEnd => {
write!(w, r#"</i>"#).unwrap();
}
}
}
Ok(())
}
The class attribute is non-double-quoted on purpose.
That's invalid XHTML, but valid HTML5. And there's a lot of those, so, y'know. Hard to resist.
And by using classes instead of inline styles... it works with both the light theme and the dark theme. Oh yeah! Did I mention there's a dark theme?

You can switch to it using the sun/moon semi-transparent button at the lower-left corner, or you can set log in with Patreon, and set it in your settings.
Speaking of settings, guess what you can enable?

That's right, ligatures for the code font! Opt-in by popular demand.
Is that the whole content pipeline? Of course not!
I do want shortcodes. And at some point, I managed to get them to sorta work, by simply parsing every article as a liquid template, and evaluating that.
This wasn't especially fast, and it had other problems, like for example,
accidentally including liquid-specific syntax in an article, like {{that}}.
So, after careful consideration, I figured that... there was a disturbing lack of the nom crate in that project.
So I wrote a parser for shortcodes. Not only that, but it's a streaming parser -
it returns an Iterator of Result<Chunk<'a>>, which borrow from the input!
#[derive(PartialEq, Eq, Debug)]
pub enum Chunk<'a> {
Text(&'a str),
Shortcode(Shortcode<'a>),
}
#[derive(PartialEq, Eq, Debug)]
pub struct Shortcode<'a> {
pub name: &'a str,
pub body: Option<&'a str>,
pub args: Args<'a>,
}
#[derive(PartialEq, Eq, Debug)]
pub enum Value<'a> {
String(&'a str),
Number(i32),
Boolean(bool),
}
It parses syntax like:
Hello, here's a tip:
{% sc tip %}
Sometimes it's easier to do it yourself.
{% endsc %}
And here's a YouTube video:
{% sci youtube id="foobar" %}
Wasn't that fun.
Then, each shortcode is its own (pre-parsed) liquid template, is evaluated at the right time, with the right arguments. Speaking of arguments? Those borrow from the markdown input as well.
How? Well, you remember how liquid filters take a &dyn ValueView as their
input? Well, liquid templates take a &dyn ObjectView as their globals.
So I just implemented ObjectView on Shortcode<'a>. So many copies
avoided. It's beautiful, I think I'm going to shed a tear.
Now, if only pulldown-cmark would allow streaming input, the whole
flow, from original markdown file to rendered HTML, going through
shortcodes, markdown parsing, syntax highlighting, HTML generation and HTML
rewriting, could be streaming.
But noooo. Pull parsers have streaming output, but they need the whole input. So there's a couple copies in there still. Darn! At least I get to re-use buffers when mass-processing pages!
Closing words
Honestly, I think that's all of it.
I've had a grand old time developing all of that, and I sincerely hope it doesn't come crashing down at the first hint of mass traffic, but I don't see why it would.
I did get it to crash in production - but only when I tried making a static build with musl so I could copy binaries directly from my ArchLinux development machine to my Debian server.
Turns out, in 2020, there's still a bunch of crates that will just cause
segmentation faults when used with musl. That's okay though. I solved the
problem another way - by switching the server to ArchLinux.
Anyway, shout out to Heztner for auctioning off perfectly fine servers for a very reasonable monthly fee - check it out for yourselves.
I'd like to give special thanks to all the folks who've supported me during the development of this new version of the website - Pascal Hertleif is probably to blame for the initial impulse, but you can probably blame Jesús Higueras and Brendan Molloy for a lot of the bike shedding.
And of course, a big thank you to all my patrons, who've stuck with me through the storm. Everything's up and running now - the normal publishing shall resume shortly.
Although, like I said earlier, I still have an idea for a tool, that would allow me to maintain large series with much less effort, and I really want to do that - but it'll be for the next series, not for Making our own executable packer.
Until then, take care!
If you liked what you saw, please support my work!

