Consuming Ethernet frames with the nom crate
This article is part of the Making our own ping series.
- Sniffing the dumb way
- Two MACs in a rowboat
- Code review + debugging interlude
- Back to our regularly-scheduled parsing
- Real-world errors
- Epilogue
Contents
Now that we've found the best way to find the "default network interface"... what can we do with that interface?
Well, listen for network traffic of course!
use rawsock::open_best_library;
use std::time::Instant;
fn main() -> Result<(), Error> {
let lib = open_best_library()?;
let iface_name = format!(r#"\Device\NPF_{}"#, netinfo::default_nic_guid()?);
let iface = lib.open_interface(&iface_name)?;
println!("Listening for packets...");
// doing some low-cost logging over here
let start = Instant::now();
iface.loop_infinite_dyn(&mut |packet| {
println!(
"{:?} | received {} bytes",
start.elapsed(),
packet.len()
);
})?;
Ok(())
}
Here's a video:
And here's some text, for accessibility:
$ cargo run --quiet Listening for packets... 1.0005401s | received 60 bytes 1.0005401s | received 100 bytes 1.0005401s | received 85 bytes 1.0005401s | received 54 bytes 1.0005401s | received 54 bytes 1.0005401s | received 54 bytes 1.0005401s | received 54 bytes 1.0005401s | received 54 bytes 1.8324313s | received 900 bytes 1.8324313s | received 183 bytes 1.8324313s | received 1392 bytes 1.8324313s | received 1392 bytes 1.8324313s | received 1392 bytes 1.8333986s | received 1392 bytes (cut)
It.. seems to work? Although it's hard to tell, because I haven't printed the contents of each packet. And I haven't printed the contents of each packet, because I don't want to post raw traffic from and to my own computer on the internet, even if I can't make sense of it right now - somebody might!
Sniffing the dumb way
I can think of a way to make sure it works.
Remember in Part 2 when we discovered that
Windows's ping.exe sent lowercase letters of the alphabet?
If the payload for ICMP echo packets isn't compressed (and this seems unlikely), then we should be able to find it in the packets we're sniffing. Let's give it a go.
So we just use .find() and..
iface.loop_infinite_dyn(&mut |packet| {
let now = start.elapsed();
match packet.find("abcdefghijkl") {
Some(_) => println!("{:?} | probably an ICMP packet", now),
None => println!("{:?} | probably *not* an ICMP packet", now),
}
})?;
$ cargo check
Checking ersatz v0.1.0 (C:\msys64\home\amos\ftl\ersatz)
error[E0599]: no method named `find` found for type `&rawsock::common::packet::BorrowedPacket<'_>` in the current scope
--> src\main.rs:23:22
|
23 | match packet.find("abcdefghijkl") {
| ^^^^
Wait, frick, no, &[u8] doesn't have .find. It has contains but that's
just for a single element (a single u8) - which is not helpful here.
How do we find if a slice contains another slice?
Well, there are certainly smart ways to do it, but for the time being we can simply use windows iterators.
haystack.windows(N) gives us an iterator over iterators over all subslices
of length N of haystack. If we call it with N = needle.len(), we can test
all those subslices for equality with needle, and stop whenever we find one
that matches!

Let's make a quick function for that:
fn contains(haystack: &[u8], needle: &[u8]) -> bool {
haystack
.windows(needle.len())
.any(|window| window == needle)
}
No, you know what, let's make it generic over any type that can be thought of as a sequence of bytes:
fn contains<H, N>(haystack: H, needle: N) -> bool
where
H: AsRef<[u8]>,
N: AsRef<[u8]>,
{
let (haystack, needle) = (haystack.as_ref(), needle.as_ref());
haystack
.windows(needle.len())
.any(|window| window == needle)
}
And then use it:
// in main()
iface.loop_infinite_dyn(&mut |packet| {
let now = start.elapsed();
if contains(&packet[..], "abcdefghijkl") {
println!("{:?} | probably an ICMP packet", now);
} else {
println!("{:?} | probably *not* an ICMP packet", now);
}
})?;
$ cargo run --quiet Listening for packets... 1.0005319s | probably *not* an ICMP packet 1.0005319s | probably *not* an ICMP packet 1.0005319s | probably an ICMP packet 1.0005319s | probably an ICMP packet 1.6498447s | probably an ICMP packet 1.6498447s | probably an ICMP packet 1.6498447s | probably *not* an ICMP packet 2.6507489s | probably *not* an ICMP packet 2.6507489s | probably *not* an ICMP packet 2.6507489s | probably *not* an ICMP packet 2.6507489s | probably *not* an ICMP packet 2.6507489s | probably *not* an ICMP packet 2.6507489s | probably an ICMP packet 2.6507489s | probably an ICMP packet
Wonderful!
Note: I was running
ping 8.8.8.8 -tin the background to test this. Otherwise, it's relatively rare to see ICMP packets pass. Not extremely rare, just uncommon enough that it got annoying to wait.
For convenience's sake, let's move our "process packet" function out of main:
use rawsock::BorrowedPacket;
use std::time::{Duration, Instant};
fn main() -> Result<(), Error> {
let lib = open_best_library()?;
let iface_name = format!(r#"\Device\NPF_{}"#, netinfo::default_nic_guid()?);
let iface = lib.open_interface(&iface_name)?;
println!("Listening for packets...");
let start = Instant::now();
iface.loop_infinite_dyn(&mut |packet| {
if !contains(&packet[..], "abcdefghijkl") {
// only handle ICMP packets
return;
}
process_packet(start.elapsed(), packet);
})?;
Ok(())
}
fn process_packet(now: Duration, packet: &BorrowedPacket) {
println!("{:?} | probably an ICMP packet", now);
}
Good. Moving on.
So we know that somewhere in there, there's probably some ICMP packets. But what it is exactly we're getting? Ethernet frames? IP packets? It could be either, depending on the library rawsock is using under the hood.
If it is an Ethernet frame, then it should have the following structure:

And the EtherType for IPv4 is 0x0800. So if we read a 16-bit
integer at position 12, we should be good?
But how do we get a u16 from a &[u8]? Well, by now, we know an unsafe
way to do it:
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let ether_type: u16 = unsafe {
let u16_ptr: *const u16 = transmute(&packet[12]);
*u16_ptr
};
println!("{:?} | ether_type = 0x{:04x}", now, ether_type);
}
$ cargo run --quiet Listening for packets... 6.1546872s | ether_type = 0x0008 6.1547236s | ether_type = 0x0008 6.6612632s | ether_type = 0x0008 6.6613005s | ether_type = 0x0008 7.3471202s | ether_type = 0x0008 7.3471402s | ether_type = 0x0008
Huh. That's 0x0008, not 0x0800. Still, pretty close though. Looks like two bytes
were just swapped?
Remember in Reading files the hard way - Part 3, when we used the byteorder crate?
Well, same. It just so happens that my processor (an Intel i7) is little-endian, but Ethernet is big-endian, so we can't just transmute things at will and expect it to work.
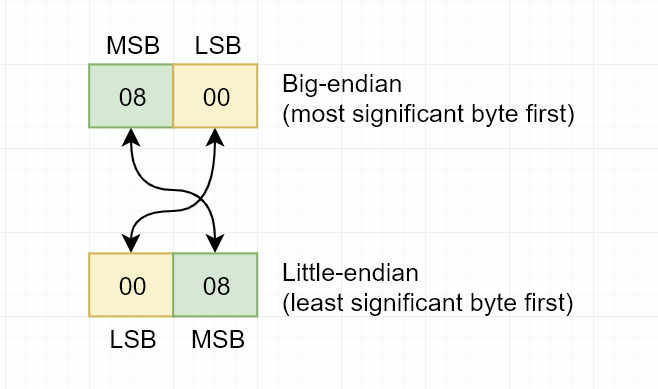
We can do it by hand:
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let (a, b) = (packet[12], packet[13]);
let (a, b) = (a as u16, b as u16);
let ether_type = (a << 8) + b;
println!("{:?} | ether_type = 0x{:04x}", now, ether_type);
}
And it'd work:
$ cargo run --quiet Listening for packets... 1.0068664s | ether_type = 0x0800 1.0069143s | ether_type = 0x0800 2.0119471s | ether_type = 0x0800 3.0154707s | ether_type = 0x0800 3.0154912s | ether_type = 0x0800
But this would only work on little-endian processors. On big-endian processors, we'd be shifting bytes around unnecessarily (and incorrectly).
Plus, writing this by hand is kinda error-prone. I'm not ashamed to admit that I - your humble servant - frequently get bit-twiddling wrong.
I'm also not ashamed to admit that I prefer portable, declarative(-ish) code.
Luckily, here we don't even have to bring the byteorder crate in (we're
watching our Cargo.toml size and compile times, remember?). The Rust
standard library contains everything we need.
Unluckily, it wants a fixed-size array, ie. [u8; 2], not a slice, ie.
&[u8] - which we have.
But look on the bright side! Unsafe no more:
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let ether_type = {
let mut ether_type = [0u8; 2];
ether_type.copy_from_slice(&packet[12..14]);
// "be" stands for "big endian"
u16::from_be_bytes(ether_type)
};
println!("{:?} | ether_type = 0x{:04x}", now, ether_type);
}
You may be wondering - does copy_from_slice really need to be passed
&packet[12..14]?
Would just &packet[12..] suffice?
It would not. It would panic.
This also explains why copy_from_slice does not return a Result. It just
panics. Just like trying to subslice with invalid indices will also panic.
Does this work?
$ cargo run --quiet Listening for packets... 1.0005347s | ether_type = 0x0800 1.0005645s | ether_type = 0x0800 2.0012903s | ether_type = 0x0800 2.0013114s | ether_type = 0x0800 3.0014023s | ether_type = 0x0800 3.0014241s | ether_type = 0x0800
Yeah! Seems okay. We don't know yet if they're actually ICMP packets, but at least, it looks like we're getting Ethernet frames that contain IPv4 packets. Either that, or many coincidences are happening in a row (which is always a possibility, because computers).
Two MACs in a rowboat
How about we check that the MAC addresses look reasonable? We know MAC
addresses look something like 12:34:56:78:9A:BC, so, let's make a quick struct.
This is not the last we've seen of Ethernet, so, let's make an ethernet module.
// in `src/main.rs` mod ethernet;
// in `src/ethernet.rs`
use std::fmt;
#[derive(PartialEq, Eq, Clone, Copy)]
pub struct Addr([u8; 6]);
impl fmt::Display for Addr {
fn fmt(&self, w: &mut fmt::Formatter) -> fmt::Result {
let [a, b, c, d, e, f] = self.0;
write!(
w,
"{:02X}-{:02X}-{:02X}-{:02X}-{:02X}-{:02X}",
a, b, c, d, e, f
)
}
}
impl fmt::Debug for Addr {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
fmt::Display::fmt(self, f)
}
}
MAC addresses are sometimes formatted as "12:34:45:67:89:AB", but according to some IEEE document, the "12-34-45-67-89-AB" form is preferred, so that's what we'll use.
It's also the format used in ipconfig /all's output on Windows 10 at least.
As a bonus, the hyphen-separated format doesn't look anything like IPv6 addresses. No confusion!
Let's also make a convenience method to "build" a MacAddress from a slice:
// in `src/ethernet.rs`
impl Addr {
pub fn new(slice: &[u8]) -> Self {
let mut res = Self([0u8; 6]);
// note: this will panic if the slice is too small!
res.0.copy_from_slice(&slice[..6]);
res
}
}
Then, for readability, let's define a read_u16 function, which will read
a big-endian 16-bit integer from a slice.
All together, we get:
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let read_u16 = |slice: &[u8]| {
let mut res = [0u8; 2];
res.copy_from_slice(&slice[..2]);
u16::from_be_bytes(res)
};
let dst = ethernet::Addr::new(&packet[0..]);
let src = ethernet::Addr::new(&packet[6..]);
let ether_type = read_u16(&packet[12..]);
println!(
"{:?} | dst {} | src {} | typ 0x{:04x}",
now, dst, src, ether_type
);
}
$ cargo run --quiet Listening for packets... 404.8053ms | dst 14-0C-76-6A-71-BD | src F4-D1-08-0B-7E-BC | typ 0x0800 404.8525ms | dst F4-D1-08-0B-7E-BC | src 14-0C-76-6A-71-BD | typ 0x0800 1.4515468s | dst 14-0C-76-6A-71-BD | src F4-D1-08-0B-7E-BC | typ 0x0800 1.4515697s | dst F4-D1-08-0B-7E-BC | src 14-0C-76-6A-71-BD | typ 0x0800 2.8507864s | dst 14-0C-76-6A-71-BD | src F4-D1-08-0B-7E-BC | typ 0x0800 2.8508097s | dst F4-D1-08-0B-7E-BC | src 14-0C-76-6A-71-BD | typ 0x0800 3.6322431s | dst 14-0C-76-6A-71-BD | src F4-D1-08-0B-7E-BC | typ 0x0800 3.6322665s | dst F4-D1-08-0B-7E-BC | src 14-0C-76-6A-71-BD | typ 0x0800
This looks good!
We can immediately see that there's pairs of packets, from F4-D1...
to 14-0C..., and back. Probably echo requests and responses!
Do those look legit? Remember that blocks of MAC addresses are assigned to network hardware vendors, so we can simply look those up in an online database, and we find that:
F4-D1-08-0B-7E-BCis manufactured by "Intel Corporate"14-0C-76-6A-71-BDis manufactured by "FREEBOX SAS"
Which would definitely match my Wi-Fi adapter and my ISP's box.
Code review + debugging interlude
So we've parsed a little bit of Ethernet.
Should we be happy? Yes!
Should we be content! No!
Our parsing code right now is very imperative, and it's not immediately obvious what's going on.
Here it is again with annotations:
// FIXME: why is this a closure? seems generally useful,
// it should be somewhere else.
let read_u16 = |slice: &[u8]| {
// TODO: are we sure this optimizes nicely?
// or does it to unnecessarily allocations left and right?
let mut res = [0u8; 2];
res.copy_from_slice(&slice[..2]);
u16::from_be_bytes(res)
};
let dst = ethernet::Addr::new(&packet[0..]);
// TODO: are we sure that `dst` is 6 bytes?
// or is it 4 bytes and we're skipping 2 bytes here?
let src = ethernet::Addr::new(&packet[6..]);
// TODO: same questions
let ether_type = read_u16(&packet[12..]);
// TODO: check if `read_u16` takes a slice of any length >= 2,
// or only slices of length 2 exactly.
And for that, we're going to want a few crates.
But first, a diversion: does from_be_bytes optimize nicely?
Let's build a sample program:
$ mkdir wat $ cargo init
// in `wat/src/main.rs`
#[inline(never)]
pub extern "C" fn read_u16(slice: &[u8]) -> u16 {
let mut res = [0u8; 2];
res.copy_from_slice(&slice[..2]);
u16::from_be_bytes(res)
}
fn main() {
println!("{}", read_u16(&[0x12, 0x34]));
println!("{}", read_u16(&[0x56, 0x78]));
}
Let's include debug symbols, because we want a release build here:
# at the end of `wat/Cargo.toml` [profile.release] debug = true
$ cargo build --release
Compiling wat v0.1.0 (C:\msys64\home\amos\ftl\wat)
Finished release [optimized + debuginfo] target(s) in 0.30s
We'll use x64dbg to find out. We can just open up the
wat\target\release directory in explorer and drag our .exe into the
x64dbg window.
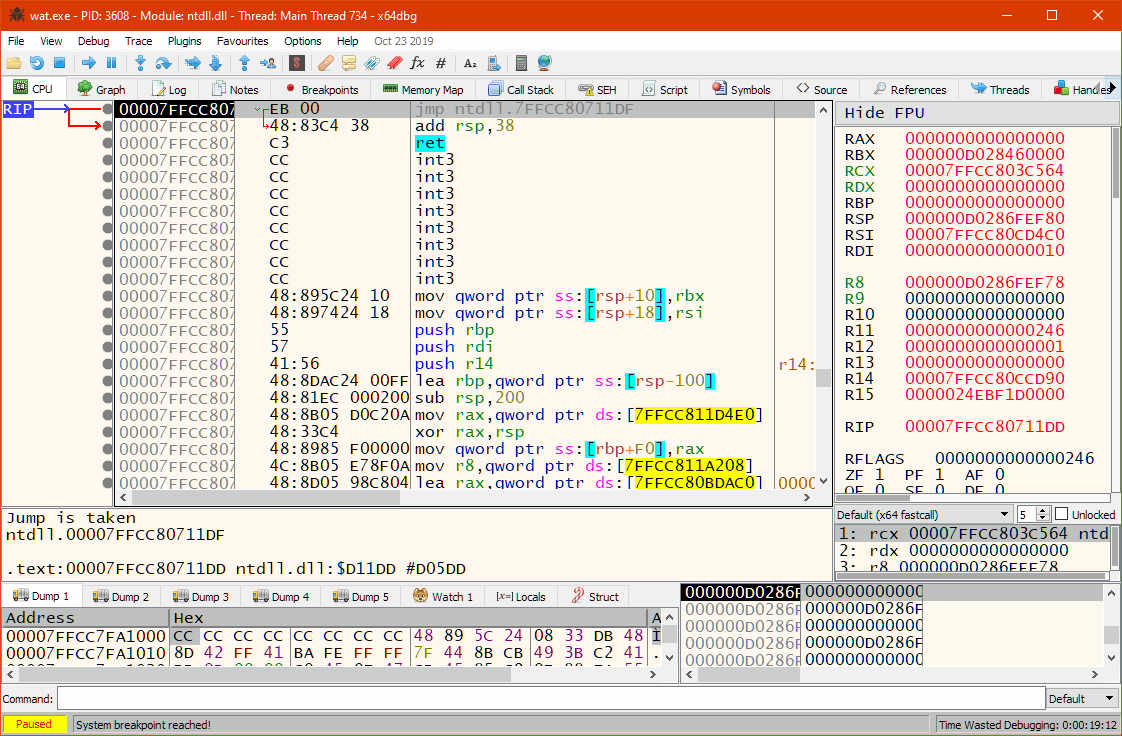
To find our function, we can use the "Symbols" tab:
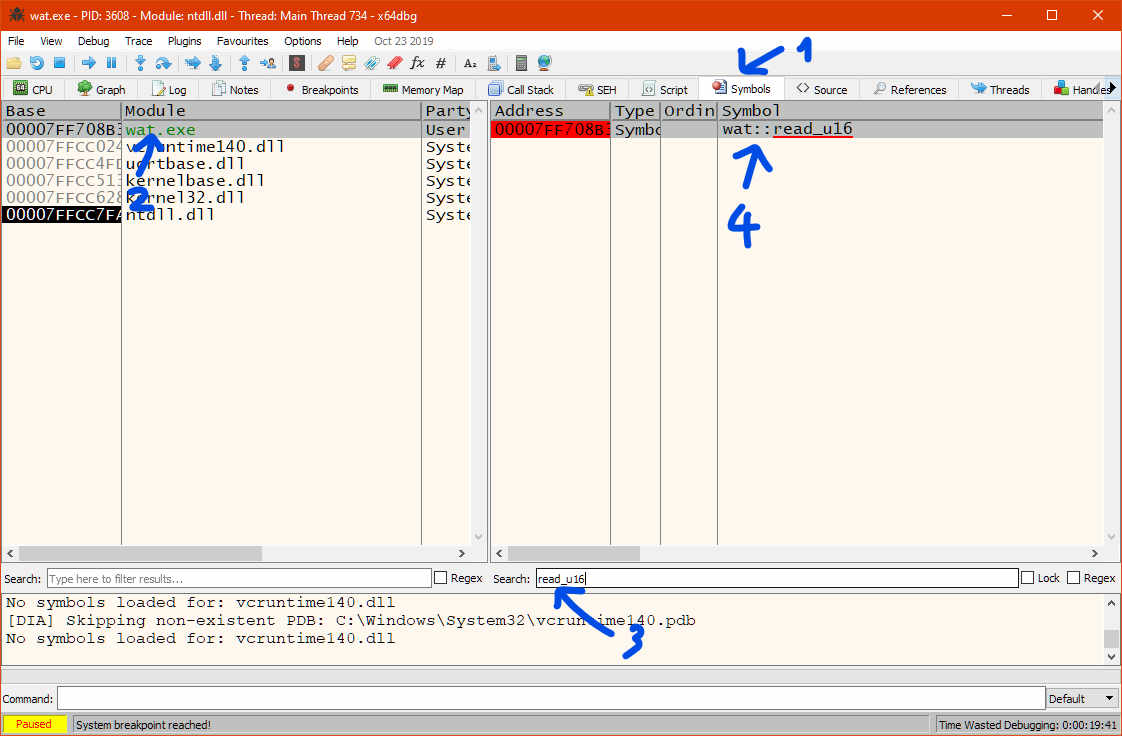
Double-clicking on the symbol brings us to its disassembly:
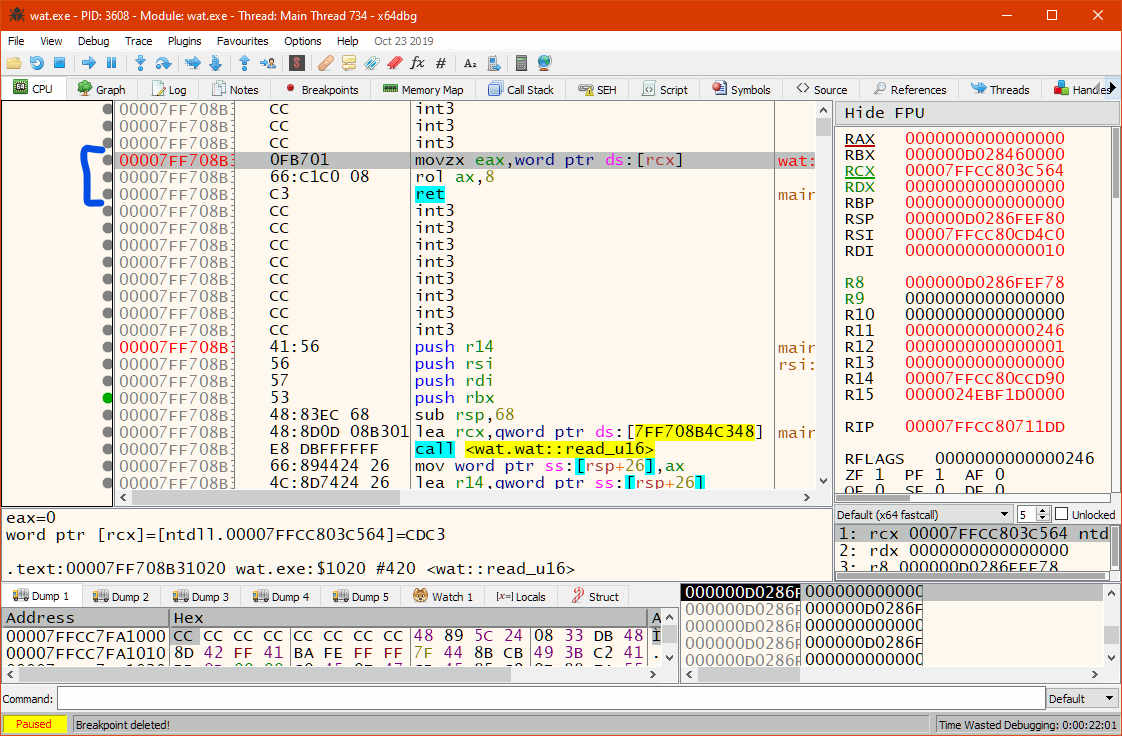
Yeah that's uhh pretty short.
movzx eax, word ptr ds:[rcx] rol ax, 8 ret
Let's set a breakpoint and start debugging:
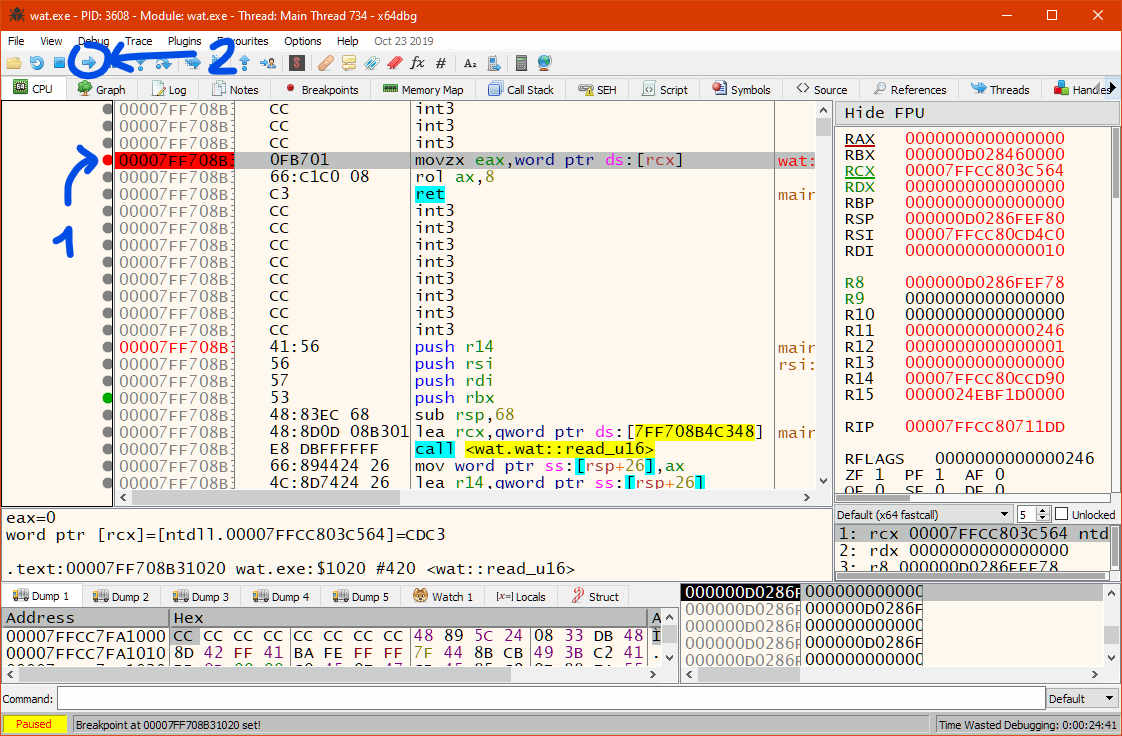
Here we are at the very start of read_u16:
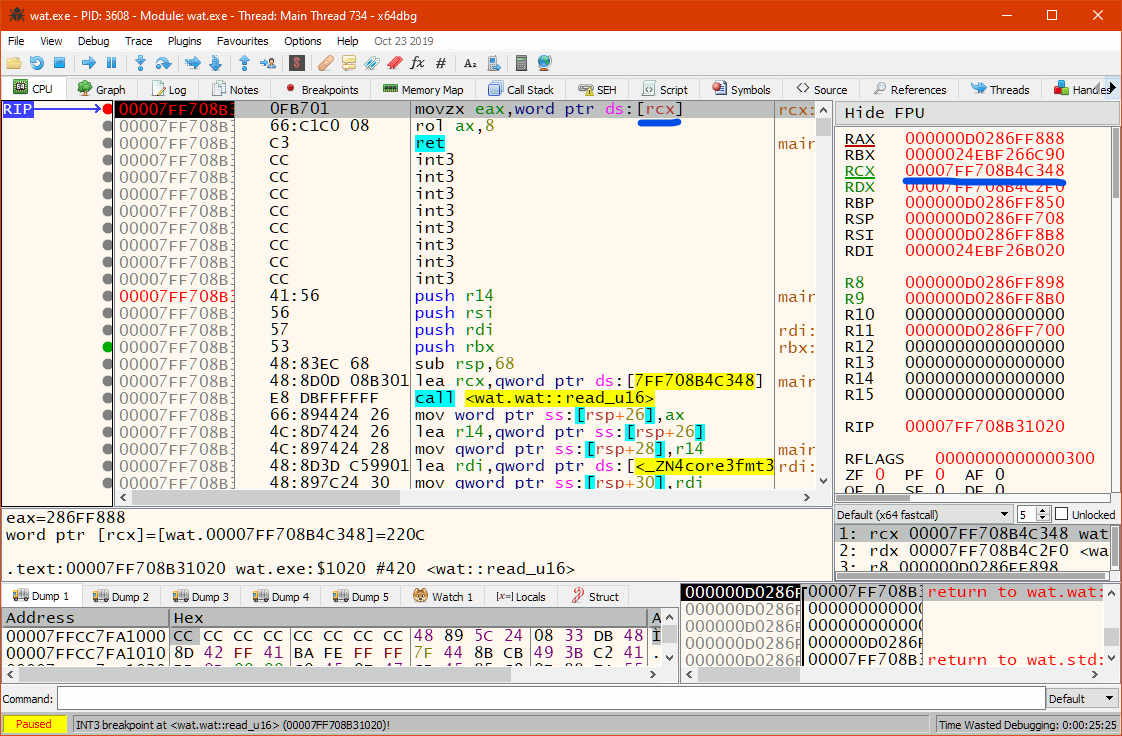
There's only one argument passed to read_u16, and it's a slice.
It appears the address of the slice's contents are passed through
the RCX register, which seems correct on Microsoft x64.
movzx eax, word ptr ds:[rcx]
We're reading a word (two bytes, 16 bits) from memory, starting from
the address contained in the RCX register. We're also zero-extending
(that's the zx in movzx), so that the rest of EAX contains zeroes.
Which, after movzx, it does!
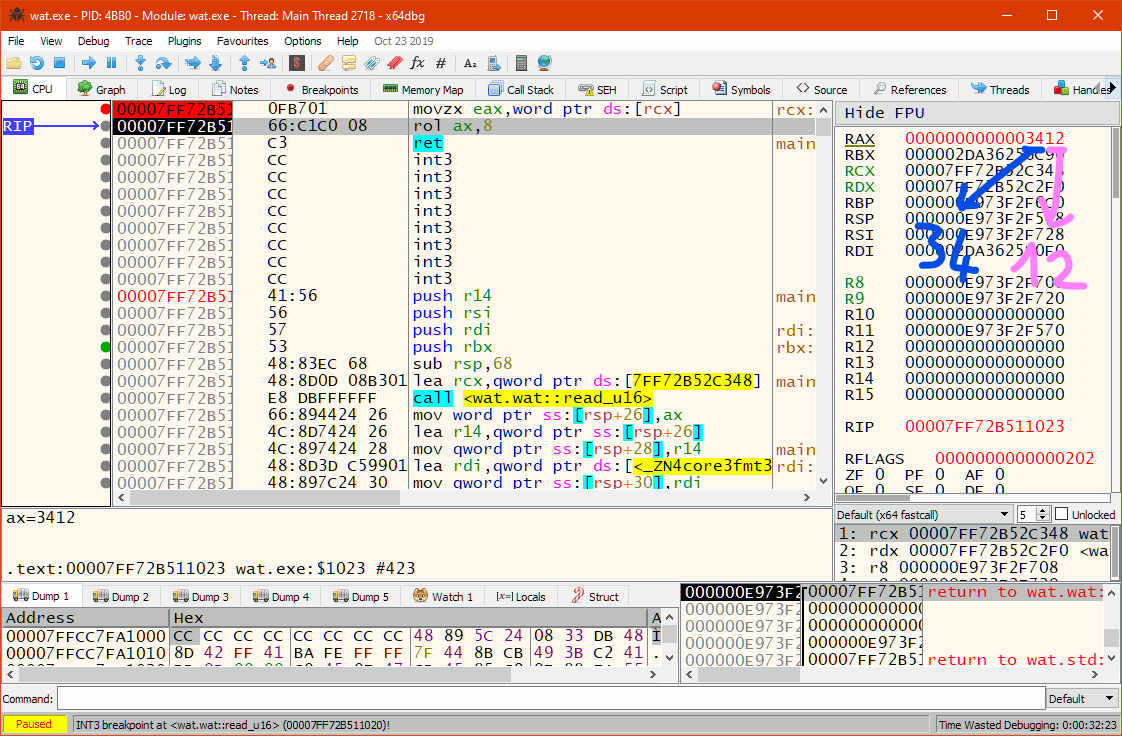
All that's left is to rotate the AX register (16-bit wide) left 8 bits and...
rol ax, 8
wait.. just rotate left? Does it wrap around?
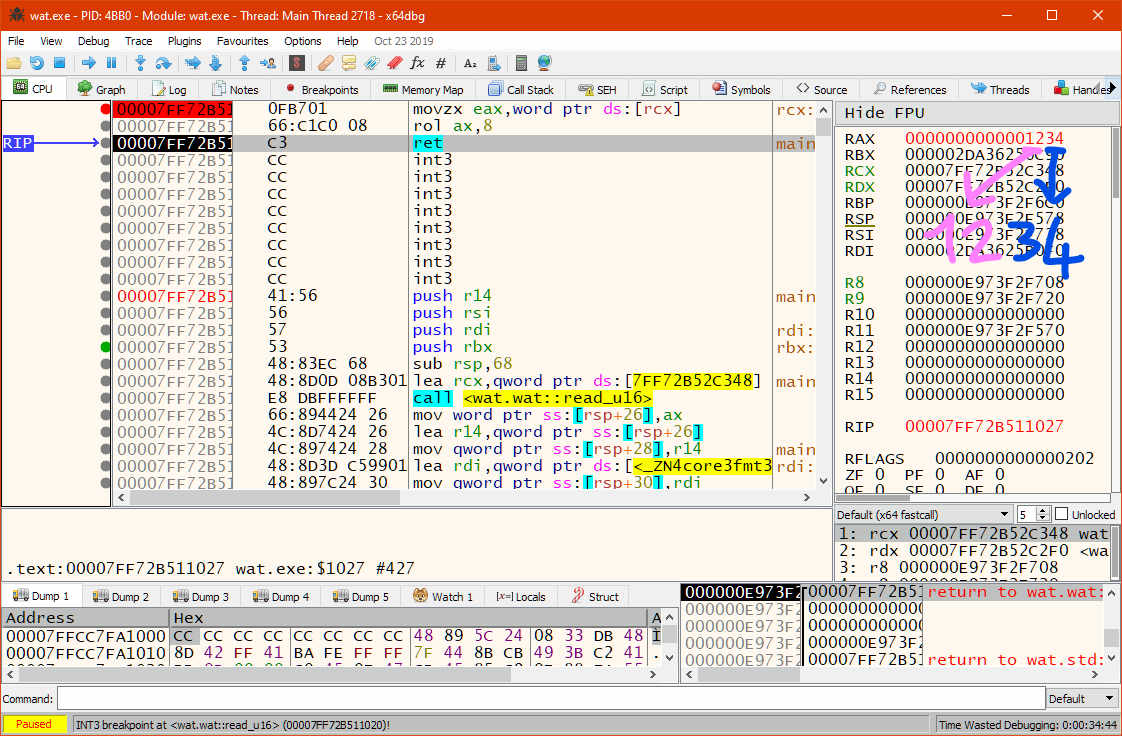
Yeah! Apparently it does.
We now have the u16 we want in RAX, and, what a coincidence, that's also
the register used to return integers in the Microsoft x64 calling convention.
So, to answer our question, yes, u16::from_be_bytes (and even copy_from_slice)
optimize really well.
Back to our regularly-scheduled parsing
Before we took a detour through x64dbg-land, I said I wanted our parsing to be more declarative.
First off, I want an ethernet::Frame structure.
// in `src/ethernet.rs`
use custom_debug_derive::*;
#[derive(CustomDebug)]
pub struct Frame {
pub dst: Addr,
pub src: Addr,
#[debug(format = "0x{:04x}")]
pub ether_type: u16,
}
Second, I want it to have a parse method:
// still in `src/ethernet.rs`
impl Frame {
pub fn parse(i: &[u8]) -> Self {
let read_u16 = |slice: &[u8]| {
let mut res = [0u8; 2];
res.copy_from_slice(&slice[..2]);
u16::from_be_bytes(res)
};
Self {
dst: Addr::new(&i[0..]),
src: Addr::new(&i[6..]),
ether_type: read_u16(&i[12..]),
}
}
}
Our process_packet function now becomes:
// in `src/main.rs`
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let frame = ethernet::Frame::parse(packet);
println!("{:?} | {:?}", now, frame);
}
Does it still work? Why wouldn't it!
$ cargo run --quiet
Listening for packets...
1.0004896s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
1.0005298s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
2.0009547s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
2.0009996s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
But still our code is very imperative.
We're going to use one of my all-time favorite crates: nom.
The nom crate has changed a lot over the course of its life.
We'll be using version 5, which I hear is significantly better than the previous releases.
In particular, nom 5 is based on impl Fn rather than macros, making the
code easier to read and write, and even giving a performance boost!
$ cargo add nom
Adding nom v5.0.1 to dependencies
nom is a parser combinators library, which means we'll get to.. combine..
parsers.
A parser is just a function that takes an input, and returns a result.
If we look for be_u16 in nom's documentation we'll find two variants:
one in nom::number::complete and one in nom::number::streaming. We're
only interested in the former, as we have complete Ethernet frames available.
Its signature is as follows:
pub fn be_u16<'a, E: ParseError<&'a[u8]>>(i: &'a[u8]) -> IResult<&'a[u8], u16, E> {
// (cut)
}
We immediately notice IResult, which is a nom type. Why not just use Result ?
Because parsers consume part of the input. So in case of success, they'd
typically return a tuple: (remaining_input, parsed).
Can we use it to replace our read_u16 ? Let's see.
use nom::number::complete::be_u16;
impl Frame {
pub fn parse(i: &[u8]) -> Self {
let (_, ether_type) = be_u16::<()>(&i[12..]).unwrap();
Self {
dst: Addr::new(&i[0..]),
src: Addr::new(&i[6..]),
ether_type,
}
}
}
$ cargo run --quiet
Listening for packets...
999.8623ms | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
999.8913ms | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
2.000622s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
2.0006446s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
3.0006469s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
3.0006706s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
Yeah! Seems to work!
Although we've been very naughty:
- We've completely ignored errors (by specifying
E=(), and using.unwrap()) - We're.. not actually combining parsers
If we want to combine parsers, we'll need to make a parser for Addr.
We can do that as an associated method:
// in `src/ethernet.rs`
use nom::{bytes::complete::take, combinator::map, error::ParseError, IResult};
impl Addr {
pub fn parse<'a, E>(i: &'a [u8]) -> IResult<&'a [u8], Self, E>
where
E: ParseError<&'a [u8]>,
{
map(take(6_usize), Self::new)(i)
}
}
Whoa, that's a lot of use directives. Get used to those!
Let's walk through these:
Addr::parseis a parser - it takes an input and returns anIResult<I, O, E>take(N)returns a parser - that takes 6 bytes and returns them as a slicemap(P, F)runs the parserPand, if successful, runs its output throughFbefore returning- In our case, we transform a
&[u8]into anethernet::Addr
- In our case, we transform a
Here's another way to write the same thing:
// in `src/ethernet.rs`
use nom::{combinator::map, error::ParseError, number::complete::be_u8, sequence::tuple, IResult};
// note: `be_u8` and `le_u8` are the same thing, they're just here for
// completeness. There's no such thing as a "big-endian byte", but it
// looks nicer that way.
impl Addr {
pub fn parse<'a, E>(i: &'a [u8]) -> IResult<&'a [u8], Self, E>
where
E: ParseError<&'a [u8]>,
{
// note: tuple((a, b, c)) returns an IResult<I, (A, B, C), E>
map(
tuple((be_u8, be_u8, be_u8, be_u8, be_u8, be_u8)),
|(a, b, c, d, e, f)| Self([a, b, c, d, e, f]),
)(i)
}
}
...but I like the first version better.
How do we use our new parser?
Well, we can keep being naughty:
impl Frame {
pub fn parse(i: &[u8]) -> Self {
let (_, dst) = Addr::parse::<()>(&i[0..]).unwrap();
let (_, src) = Addr::parse::<()>(&i[6..]).unwrap();
let (_, ether_type) = be_u16::<()>(&i[12..]).unwrap();
Self {
dst,
src,
ether_type,
}
}
}
This sure still works:
$ cargo run --quiet
Listening for packets...
999.5699ms | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
999.5999ms | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
1.9995319s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
1.9995561s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
2.3363625s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: 0x0800 }
2.3364035s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: 0x0800 }
...but, again, this completely defeats the purpose of nom. What we want is
to combine those, like that:
use nom::{number::complete::be_u16, sequence::tuple};
impl Frame {
pub fn parse<'a, E>(i: &'a [u8]) -> IResult<&'a [u8], Self, E>
where
E: ParseError<&'a [u8]>,
{
map(
tuple((Addr::parse, Addr::parse, be_u16)),
|(dst, src, ether_type)| Self {
dst,
src,
ether_type,
},
)(i)
}
}
Nowwww we're getting somewhere.
But I'm getting tired of typing those 'a and where E: ParseError by hand.
How about we make a parse module that has some types for us.
// in `src/main.rs` mod parse;
// in `src/parse.rs` pub type Input<'a> = &'a [u8]; pub type Result<'a, T> = nom::IResult<Input<'a>, T, ()>;
// in `src/ethernet.rs`
impl Addr {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
map(take(6_usize), Self::new)(i)
}
}
impl Frame {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
map(
tuple((Addr::parse, Addr::parse, be_u16)),
|(dst, src, ether_type)| Self {
dst,
src,
ether_type,
},
)(i)
}
}
Ahhh. Much better.
Of course, we need to change our process_packet function a bit, to account
for error handling:
fn process_packet(now: Duration, packet: &BorrowedPacket) {
match ethernet::Frame::parse(packet) {
Ok((_remaining, frame)) => {
println!("{:?} | {:?}", now, frame);
}
Err(e) => {
println!("{:?} | could not parse ethernet frame: {:?}", now, e);
}
}
}
And our sample program - still doing the same thing - works again.
But speaking of errors, what happens if we call ethernet::Frame::parse with
invalid input? Say, an incomplete frame?
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let incomplete_packet = &packet[..2];
match ethernet::Frame::parse(incomplete_packet) {
// (cut)
}
}
$ cargo run --quiet Listening for packets... 999.9702ms | could not parse ethernet frame: Error(()) 999.9991ms | could not parse ethernet frame: Error(()) 2.0000975s | could not parse ethernet frame: Error(()) 2.0001199s | could not parse ethernet frame: Error(())
Oh right. We chose the empty tuple, (), as our error type.
Let's fix that.
// in `src/parse.rs` use nom::error::ErrorKind as NomErrorKind; pub type Input<'a> = &'a [u8]; pub type Result<'a, T> = nom::IResult<Input<'a>, T, (Input<'a>, NomErrorKind)>;
$ cargo run --quiet Listening for packets... 644.1433ms | could not parse ethernet frame: Error(([20, 12], Eof)) 644.1723ms | could not parse ethernet frame: Error(([244, 209], Eof)) 1.6446712s | could not parse ethernet frame: Error(([20, 12], Eof)) 1.6446948s | could not parse ethernet frame: Error(([244, 209], Eof))
It's something! nom::error::ParseError is implemented for (I, nom::error::ErrorKind).
What if we want something a little more.. custom?
// in `src/parse.rs`
use nom::error::ErrorKind as NomErrorKind;
pub type Input<'a> = &'a [u8];
pub type Result<'a, T> = nom::IResult<Input<'a>, T, Error<Input<'a>>>;
#[derive(Debug)]
pub struct Error<I> {
pub errors: Vec<(I, NomErrorKind)>,
}
$ cargo check --quiet error[E0277]: the trait bound `parse::Error<&[u8]>: nom::error::ParseError<&[u8]>` is not satisfied --> src\ethernet.rs:37:9 | 37 | map(take(6_usize), Self::new)(i) | ^^^ the trait `nom::error::ParseError<&[u8]>` is not implemented for `parse::Error<&[u8]>` | = note: required by `nom::combinator::map` (many more errors omitted)
Oh right, we need to actually implement that trait.
I wouldn't put you - the reader - through all of that if it wasn't going to come in handy later. In the meantime, just consider it a leisurely walk through some of nom's internals.
// in `src/parse.rs`
use nom::error::{ErrorKind as NomErrorKind, ParseError as NomParseError};
pub type Input<'a> = &'a [u8];
pub type Result<'a, T> = nom::IResult<Input<'a>, T, Error<Input<'a>>>;
#[derive(Debug)]
pub struct Error<I> {
pub errors: Vec<(I, NomErrorKind)>,
}
impl<I> NomParseError<I> for Error<I> {
fn from_error_kind(input: I, kind: NomErrorKind) -> Self {
let errors = vec![(input, kind)];
Self { errors }
}
fn append(input: I, kind: NomErrorKind, mut other: Self) -> Self {
other.errors.push((input, kind));
other
}
}
$ cargo run --quiet
Listening for packets...
999.5487ms | could not parse ethernet frame: Error(Error { errors: [([20, 12], Eof)] })
999.5803ms | could not parse ethernet frame: Error(Error { errors: [([244, 209], Eof)] })
2.0000408s | could not parse ethernet frame: Error(Error { errors: [([20, 12], Eof)] })
2.0001096s | could not parse ethernet frame: Error(Error { errors: [([244, 209], Eof)] })
Cool!
You may have noticed our parse::Error type actually holds a Vec of errors.
Why is this important? So we can have multiple errors of course.
The context combinator allows us to add some, well, context, to our errors.
In other words it allows us to attach to our errors information about what it is
we were trying to parse.
Let's use it now:
// in `src/ethernet.rs`
use nom::{
bytes::complete::take, combinator::map, error::context, number::complete::be_u16,
sequence::tuple,
};
impl Addr {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
context("MAC address", map(take(6_usize), Self::new))(i)
}
}
impl Frame {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
context(
"Ethernet frame",
map(
tuple((Addr::parse, Addr::parse, context("EtherType", be_u16))),
|(dst, src, ether_type)| Self {
dst,
src,
ether_type,
},
),
)(i)
}
}
Huh, this doesn't change the output at all. Let's look at the implementation
of the context combinator:
/// create a new error from an input position, a static string and an existing error.
/// This is used mainly in the [context] combinator, to add user friendly information
/// to errors when backtracking through a parse tree
#[cfg(feature = "alloc")]
pub fn context<I: Clone, E: ParseError<I>, F, O>(context: &'static str, f: F) -> impl Fn(I) -> IResult<I, O, E>
where
F: Fn(I) -> IResult<I, O, E> {
move |i: I| {
match f(i.clone()) {
Ok(o) => Ok(o),
Err(Err::Incomplete(i)) => Err(Err::Incomplete(i)),
Err(Err::Error(e)) => Err(Err::Error(E::add_context(i, context, e))),
Err(Err::Failure(e)) => Err(Err::Failure(E::add_context(i, context, e))),
}
}
}
Okay.. looks like it calls add_context on our Error type. I don't remember
implementing that, do you? Maybe there's a default implementation in the ParseError
trait..
pub trait ParseError<I>: Sized {
// (cut: other fns)
/// create a new error from an input position, a static string and an existing error.
/// This is used mainly in the [context] combinator, to add user friendly information
/// to errors when backtracking through a parse tree
fn add_context(_input: I, _ctx: &'static str, other: Self) -> Self {
other
}
}
Oh. It's just throwing the context away.
We're going to need an enum. NomErrorKind is already an enum, but none of the variants
take a string, they're just simple cases like so:
pub enum ErrorKind {
Tag,
MapRes,
MapOpt,
Alt,
IsNot,
// etc.
}
So let's make our own ErrorKind:
#[derive(Debug)]
pub enum ErrorKind {
// ooh that's why `nom::error::ErrorKind` was aliased to `NomErrorKind`:)
Nom(NomErrorKind),
Context(&'static str),
}
#[derive(Debug)]
pub struct Error<I> {
// was NomErrorKind, now ErrorKind
pub errors: Vec<(I, ErrorKind)>,
}
impl<I> NomParseError<I> for Error<I> {
fn from_error_kind(input: I, kind: NomErrorKind) -> Self {
// was (input, kind)
let errors = vec![(input, ErrorKind::Nom(kind))];
Self { errors }
}
fn append(input: I, kind: NomErrorKind, mut other: Self) -> Self {
// was (input, kind)
other.errors.push((input, ErrorKind::Nom(kind)));
other
}
// new!
fn add_context(input: I, ctx: &'static str, mut other: Self) -> Self {
other.errors.push((input, ErrorKind::Context(ctx)));
other
}
}
Now we can see exactly where parsing failed:
$ cargo run --quiet
Listening for packets...
1.0001186s | Error(Error { errors: [([20, 12], Nom(Eof)), ([20, 12], Context("MAC address")), ([20, 12], Context("Ethernet frame"))] })
1.0001786s | Error(Error { errors: [([244, 209], Nom(Eof)), ([244, 209], Context("MAC address")), ([244, 209], Context("Ethernet frame"))] })
2.0002709s | Error(Error { errors: [([20, 12], Nom(Eof)), ([20, 12], Context("MAC address")), ([20, 12], Context("Ethernet frame"))] })
2.0003059s | Error(Error { errors: [([244, 209], Nom(Eof)), ([244, 209], Context("MAC address")), ([244, 209], Context("Ethernet frame"))] })
Although.. I'm not in love with that error format.
How about we prettify it a little bit?
$ cargo add hex_slice
WARN: Added `hex-slice` instead of `hex_slice`
Adding hex-slice v0.1.4 to dependencies
$ echo "thanks cargo-edit, I promise not to typo it again"
// in `src/parse.rs`
use std::fmt;
impl<'a> fmt::Debug for Error<&'a [u8]> {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "/!\\ ersatz parsing error\n")?;
for (input, kind) in self.errors.iter().rev() {
let prefix = match kind {
ErrorKind::Context(ctx) => format!("...in {}", ctx),
ErrorKind::Nom(err) => format!("nom error {:?}", err),
};
let maxlen = 40;
let input = if input.len() > maxlen {
&input[input.len() - maxlen..]
} else {
input
};
use hex_slice::AsHex;
write!(f, "{:<30} {:x}\n", prefix, input.as_hex())?;
}
Ok(())
}
}
We're also going to adjust our process_packet() function a bit - by
matching the error more precisely.
As long as we never use the cut combinator, and never use any streaming
parsers, we should only ever get nom::Err::Error, never nom::Err::Failure
(from cut) or nom::Err::Incomplete (from streaming parsers).
This will make the output even cleaner:
fn process_packet(now: Duration, packet: &BorrowedPacket) {
let incomplete_packet = &packet[..2];
match ethernet::Frame::parse(incomplete_packet) {
Ok((_remaining, frame)) => {
println!("{:?} | {:?}", now, frame);
}
Err(nom::Err::Error(e)) => {
println!("{:?} | {:?}", now, e);
}
// this will crash *loudly* if our assumptions were wrong
_ => unreachable!(),
}
}
$ cargo run --quiet Listening for packets... 303.8231ms | /!\ ersatz parsing error ...in Ethernet frame [14 c] ...in MAC address [14 c] nom error Eof [14 c] 303.8853ms | /!\ ersatz parsing error ...in Ethernet frame [f4 d1] ...in MAC address [f4 d1] nom error Eof [f4 d1] 1.3050234s | /!\ ersatz parsing error ...in Ethernet frame [14 c] ...in MAC address [14 c] nom error Eof [14 c] 1.3050716s | /!\ ersatz parsing error ...in Ethernet frame [f4 d1] ...in MAC address [f4 d1] nom error Eof [f4 d1]
That already looks a lot better. I wonder if it's useful to print the input for every line though. What if we give a slightly longer truncated Ethernet frame, so that it fails in, say, the middle of reading the EtherType?
// in `src/main.rs`
fn process_packet(now: Duration, packet: &BorrowedPacket) {
// was `..2`
let incomplete_packet = &packet[..13];
// cut: call ethernet::Frame::parse()
}
$ cargo run --quiet Listening for packets... 1.0010714s | /!\ ersatz parsing error ...in Ethernet frame [f4 d1 8 b 7e bc 14 c 76 6a 71 bd 8] ...in EtherType [8] nom error Eof [8] 1.0011471s | /!\ ersatz parsing error ...in Ethernet frame [14 c 76 6a 71 bd f4 d1 8 b 7e bc 8] ...in EtherType [8] nom error Eof [8]
Yeah! It is useful!
Although.. I'm not fond of the way hex-slice shows hex values. I'd like them
to be two-character wide no matter what.
Also, [8] is not extremely useful as far as context goes. Is it the first 8?
Or the second one?
...in Ethernet frame [f4 d1 8 b 7e bc 14 c 76 6a 71 bd 8]
^ ^
this one ? or this one ?
$ cargo rm hex-slice
Removing hex-slice from dependencies
We can do better than this.
use std::fmt;
impl<'a> fmt::Debug for Error<&'a [u8]> {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "/!\\ ersatz parsing error\n")?;
let mut shown_input = None;
let margin_left = 4;
let margin_str = " ".repeat(margin_left);
// maximum amount of binary data we'll dump per line
let maxlen = 60;
// given a big slice, an offset, and a length, attempt to show
// some data before, some data after, and highlight which part
// we're talking about with tildes.
let print_slice =
|f: &mut fmt::Formatter, s: &[u8], offset: usize, len: usize| -> fmt::Result {
// decide which part of `s` we're going to show.
let (s, offset, len) = {
// see diagram further in article.
// TODO: review for off-by-one errors
let avail_after = s.len() - offset;
let after = std::cmp::min(avail_after, maxlen / 2);
let avail_before = offset;
let before = std::cmp::min(avail_before, maxlen / 2);
let new_start = offset - before;
let new_end = offset + after;
let new_offset = before;
let new_len = std::cmp::min(new_end - new_start, len);
(&s[new_start..new_end], new_offset, new_len)
};
write!(f, "{}", margin_str)?;
for b in s {
write!(f, "{:02X} ", b)?;
}
write!(f, "\n")?;
write!(f, "{}", margin_str)?;
for i in 0..s.len() {
// each byte takes three characters, ie "FF "
if i == offset + len - 1 {
// ..except the last one
write!(f, "~~")?;
} else if (offset..offset + len).contains(&i) {
write!(f, "~~~")?;
} else {
write!(f, " ")?;
};
}
write!(f, "\n")?;
Ok(())
};
for (input, kind) in self.errors.iter().rev() {
let prefix = match kind {
ErrorKind::Context(ctx) => format!("...in {}", ctx),
ErrorKind::Nom(err) => format!("nom error {:?}", err),
};
write!(f, "{}\n", prefix)?;
match shown_input {
None => {
shown_input.replace(input);
print_slice(f, input, 0, input.len())?;
}
Some(parent_input) => {
// `nom::Offset` is a trait that lets us get the position
// of a subslice into its parent slice. This works great for
// our error reporting!
use nom::Offset;
let offset = parent_input.offset(input);
print_slice(f, parent_input, offset, input.len())?;
}
};
}
Ok(())
}
}
Here's the diagram I drew to help me write this code:
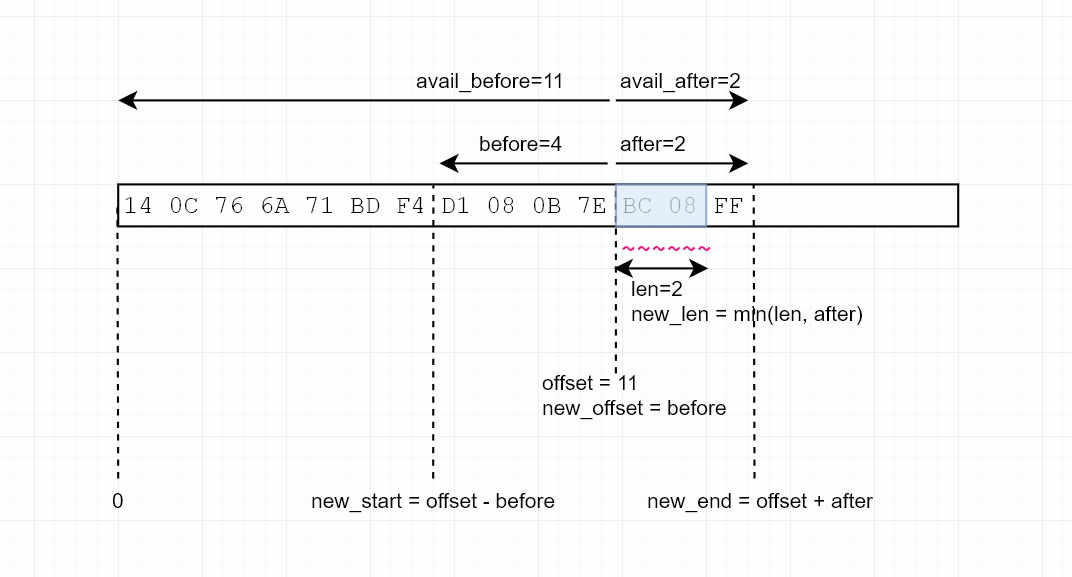
I'm fairly happy with the result:
$ cargo run --quiet
Listening for packets...
1.0008906s | /!\ ersatz parsing error
...in Ethernet frame
14 0C 76 6A 71 BD F4 D1 08 0B 7E BC 08
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
...in EtherType
14 0C 76 6A 71 BD F4 D1 08 0B 7E BC 08
~~
nom error Eof
14 0C 76 6A 71 BD F4 D1 08 0B 7E BC 08
~~
Real-world errors
We've only seen synthetic errors for now, so how about a real one?
There's only a handful of EtherType values we care about, so let's make
it an enum:
$ cargo add derive-try-from-primitive
Adding derive-try-from-primitive v0.1.0 to dependencies
// in `src/ethernet.rs`
use derive_try_from_primitive::*;
#[derive(Debug, TryFromPrimitive)]
#[repr(u16)]
pub enum EtherType {
IPv4 = 0x0800,
}
Make a parser for it:
impl EtherType {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
context(
"EtherType",
map(be_u16, |x| EtherType::try_from(x).unwrap()),
)(i)
}
}
Use it in Frame:
#[derive(Debug)]
pub struct Frame {
pub dst: Addr,
pub src: Addr,
pub ether_type: EtherType,
}
Use it in Frame's parser:
impl Frame {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
context(
"Ethernet frame",
map(
tuple((Addr::parse, Addr::parse, EtherType::parse)),
|(dst, src, ether_type)| Self {
dst,
src,
ether_type,
},
),
)(i)
}
}
And take it for a spin:
// in `src/main.rs`
fn process_packet(now: Duration, packet: &BorrowedPacket) {
// was `incomplete_packet`
match ethernet::Frame::parse(packet) {
// etc.
$ cargo run --quiet
Listening for packets...
999.8431ms | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: IPv4 }
999.889ms | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: IPv4 }
1.7093166s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: IPv4 }
1.7093598s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: IPv4 }
2.7247371s | Frame { dst: 14-0C-76-6A-71-BD, src: F4-D1-08-0B-7E-BC, ether_type: IPv4 }
2.7247634s | Frame { dst: F4-D1-08-0B-7E-BC, src: 14-0C-76-6A-71-BD, ether_type: IPv4 }
So far so good.
Remember that we're still pinging 8.8.8.8 in the background.
What happens if we start pinging google.com instead? A the moment, it
resolves to [2a00:1450:4007:817::200e] for me and that.. doesn't look like
IPv4.
$ cargo run --quiet Listening for packets... thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', src\libcore\option.rs:378:21 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
Well. Something certainly happened. But it brought down our entire packet sniffer with it.
Which isn't great.
What happened?
Well, we've used the
derive-try-from-primitive
crate to get EtherType::try_from.
It performs mappings from u16 values to EtherType variants:
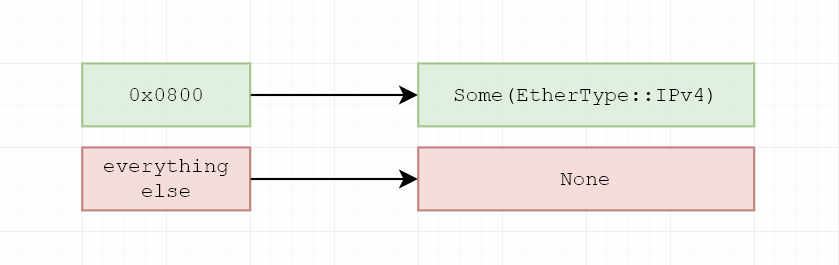
..and then we call .unwrap() on it:
impl EtherType {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
context(
"EtherType",
map(be_u16, |x| EtherType::try_from(x).unwrap()),
)(i)
}
}
...which panics on None. So everything is expected. I just kind of glossed it
over so we had an opportunity to fix it later.
How do we fix it though?
We can add.. a custom error type!
// in `src/parse.rs`
#[derive(Debug)]
pub enum ErrorKind {
Nom(NomErrorKind),
Context(&'static str),
// new!
Custom(String),
}
// new!
impl<I> Error<I> {
pub fn custom(input: I, msg: String) -> Self {
Self {
errors: vec![(input, ErrorKind::Custom(msg))],
}
}
}
// omitted: new match arm in the `fmt::Debug` implementation
Then, instead of having EtherType::parse be a pure parser combinator, we
can "stop" after calling be_u16 (if it succeeded), and check that it's a
unknown EtherType value.
impl EtherType {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
let original_i = i;
let (i, x) = context("EtherType", be_u16)(i)?;
// `i` is now the remaining input after reading the be_u16
match EtherType::try_from(x) {
Some(typ) => Ok((i, typ)),
None => {
let msg = format!("unknown EtherType 0x{:04X}", x);
// we could hardcode `&original_i[..4]` but why bother?
use nom::Offset;
let err_slice = &original_i[..original_i.offset(i)];
Err(nom::Err::Error(parse::Error::custom(err_slice, msg)))
}
}
}
}
The result is very readable:
$ cargo run --quiet
Listening for packets...
1.0000231s | /!\ ersatz parsing error
...in Ethernet frame
14 0C 76 6A 71 BD F4 D1 08 0B 7E BC 86 DD 60 00 00 00 00 28
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
unknown EtherType 0x86dd
14 0C 76 6A 71 BD F4 D1 08 0B 7E BC 86 DD 60 00 00 00 00 28 3A 80 2A 01 0E 35 2F D6 8F 60 E4 5F
~~~~~
1.0001009s | /!\ ersatz parsing error
...in Ethernet frame
F4 D1 08 0B 7E BC 14 0C 76 6A 71 BD 86 DD 60 00 00 00 00 28
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
unknown EtherType 0x86dd
F4 D1 08 0B 7E BC 14 0C 76 6A 71 BD 86 DD 60 00 00 00 00 28 3A 39 2A 00 14 50 40 07 08 17 00 00
~~~~~
nom is a powerful parsing library, that can be used both for text formats and binary formats.
With a few impl blocks here and there, it can easily support custom error handling.
Its "parser combinator" approach makes for code that's both readable and fast.
Wait, wait, cool bear, hold on, wait.
We haven't checked what kind of instructions our code actually generates.
Time to make a release build and start up x64dbg.
$ cargo build --release
Compiling proc-macro2 v0.4.30
Compiling semver-parser v0.7.0
(cut: many more lines)
Compiling ersatz v0.1.0 (C:\msys64\home\amos\ftl\ersatz)
Finished release [optimized] target(s) in 29.91s
$ butler sizeof ./target/release/ersatz.exe
Total size of ./target/release/ersatz.exe: 352.00 KiB
Honestly? 352 KiB isn't that bad.
Let's hope we can find our way through the executable...
I was able to find the symbol
_ZN6ersatz8ethernet5Frame5parse17h813008bcdcb13adbE, which looks promising.
I was not able to find any trace of EtherType::parse - I'm assuming it has
been inlined.
I analyzed the function and visualized it as a graph. The graph unfortunately doesn't fit in a single screenshot. Although, the overview view does:
We can see that it calls ersatz.sub_... twice (although it checks the return
value first):
If everything goes well, it keeps on trucking:
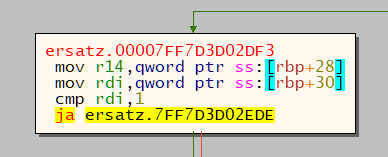
And then... ooooh would you look at that - looks a lot like our read_u16 from before!
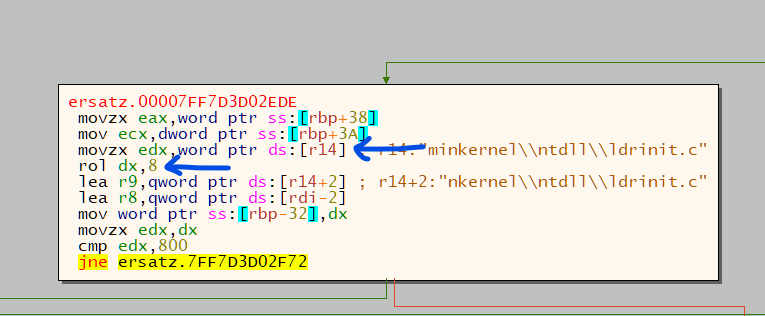
Here's another interesting bit - our fancy Rust enum? Disappeared:
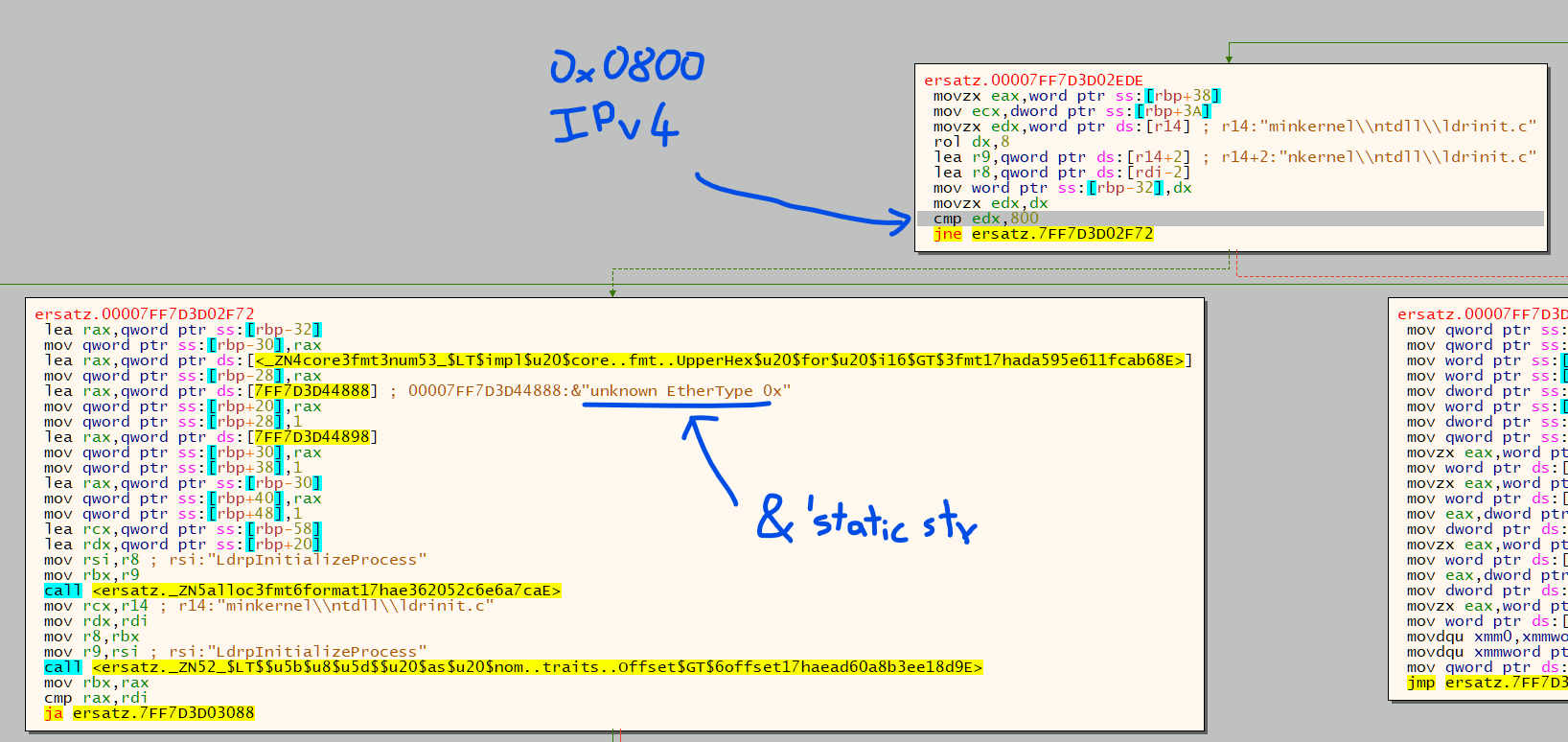
Alright, it seems that cool bear was right after all, this looks good.
Something is bothering me, though. If we look at ersatz.sub_...'s code:
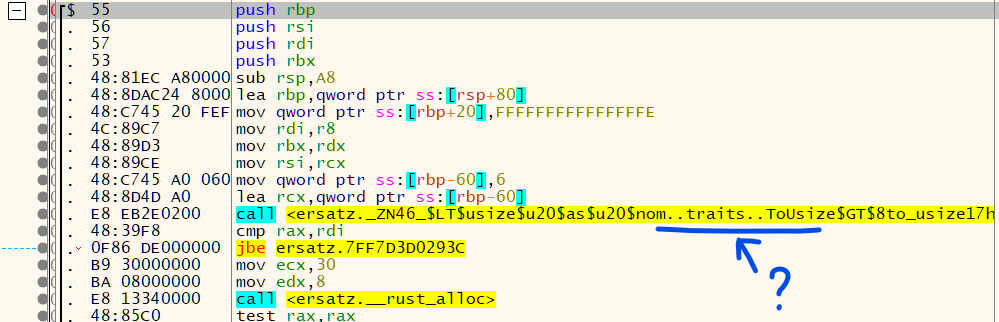
It's calling one of nom's trait methods? I wonder what it does...

Oh. Uh. Seems wasteful? Let's try turning on Link-Time Optimization:
// in `Cargo.toml` [profile.release] lto = true
$ cargo build --release
Compiling proc-macro2 v0.4.30
(many lines cut)
Compiling ersatz v0.1.0 (C:\msys64\home\amos\ftl\ersatz)
Finished release [optimized] target(s) in 34.16s
Didn't even take that much longer.
Did it make a difference in the codegen?
Looks like it! I can't find ethernet::Frame::parse anymore.
I know there's an unknown EtherType error message somewhere though.
ahAH! There it is.
Let's follow it in the graph:
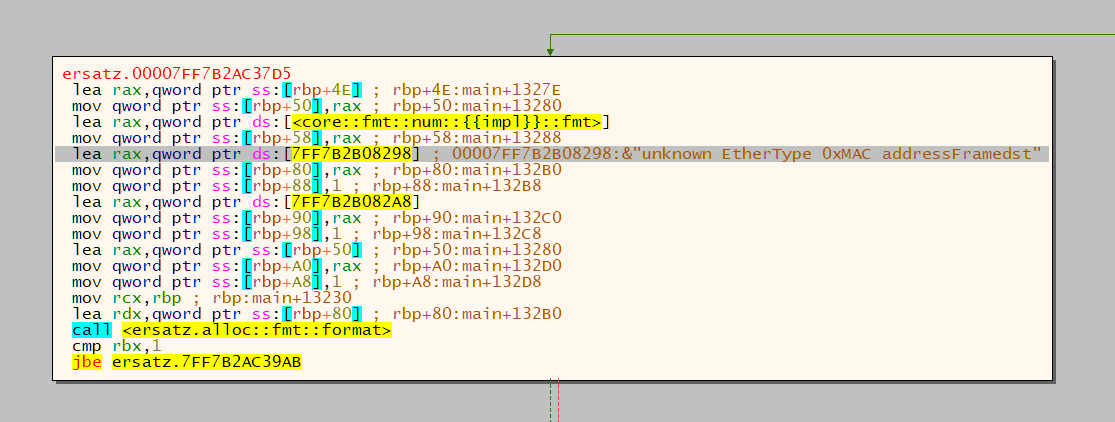
Alright, it's definitely formatting an error message. Where can we come from though?
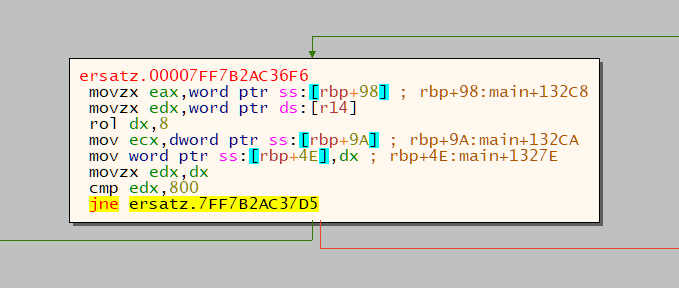
Aha! Here's our movzx and our rol.
This is in turn accessible from this part of the graph:
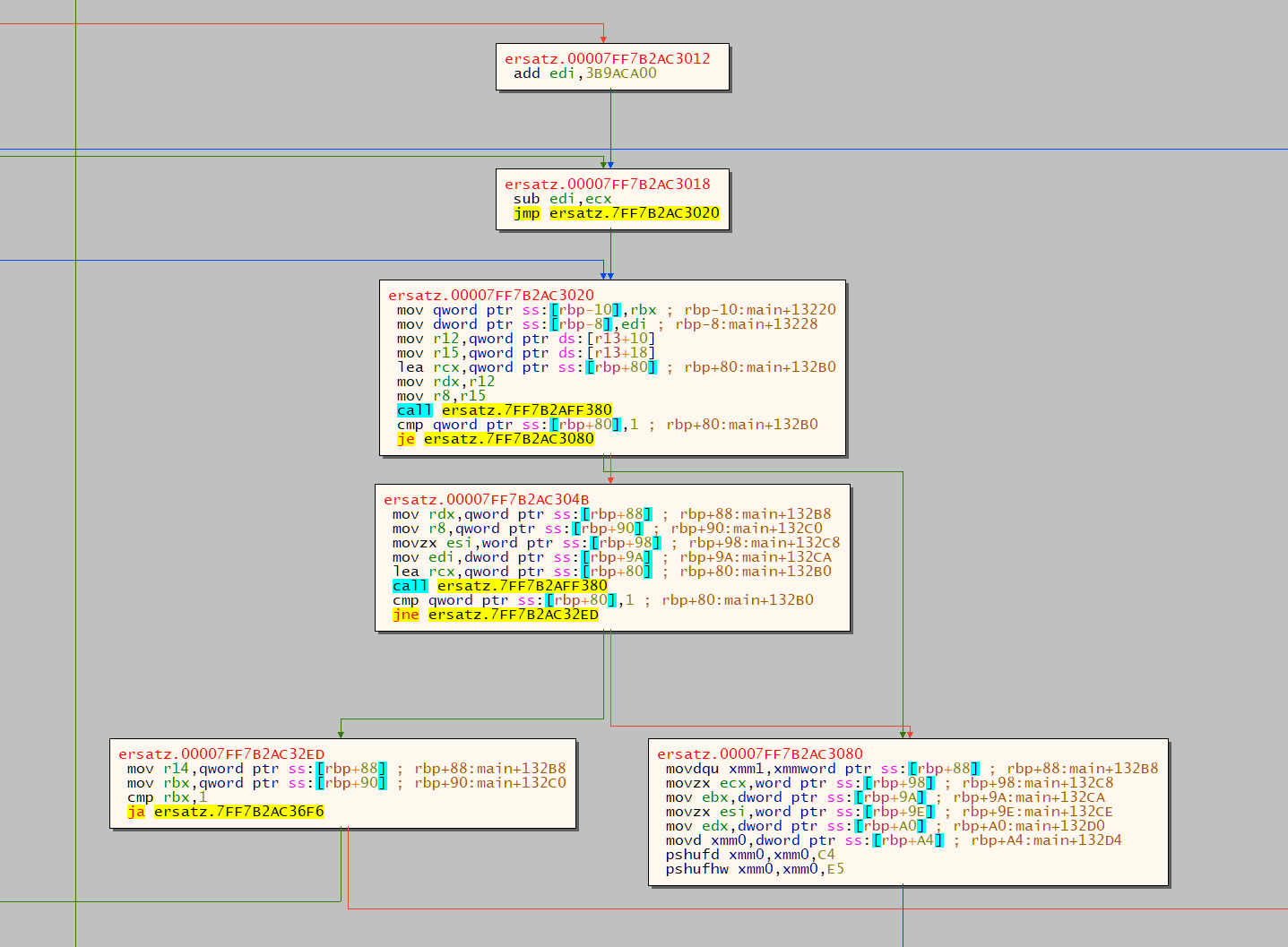
And I bet you those two call (highlighted in cyan) are to ethernet::Addr::parse.
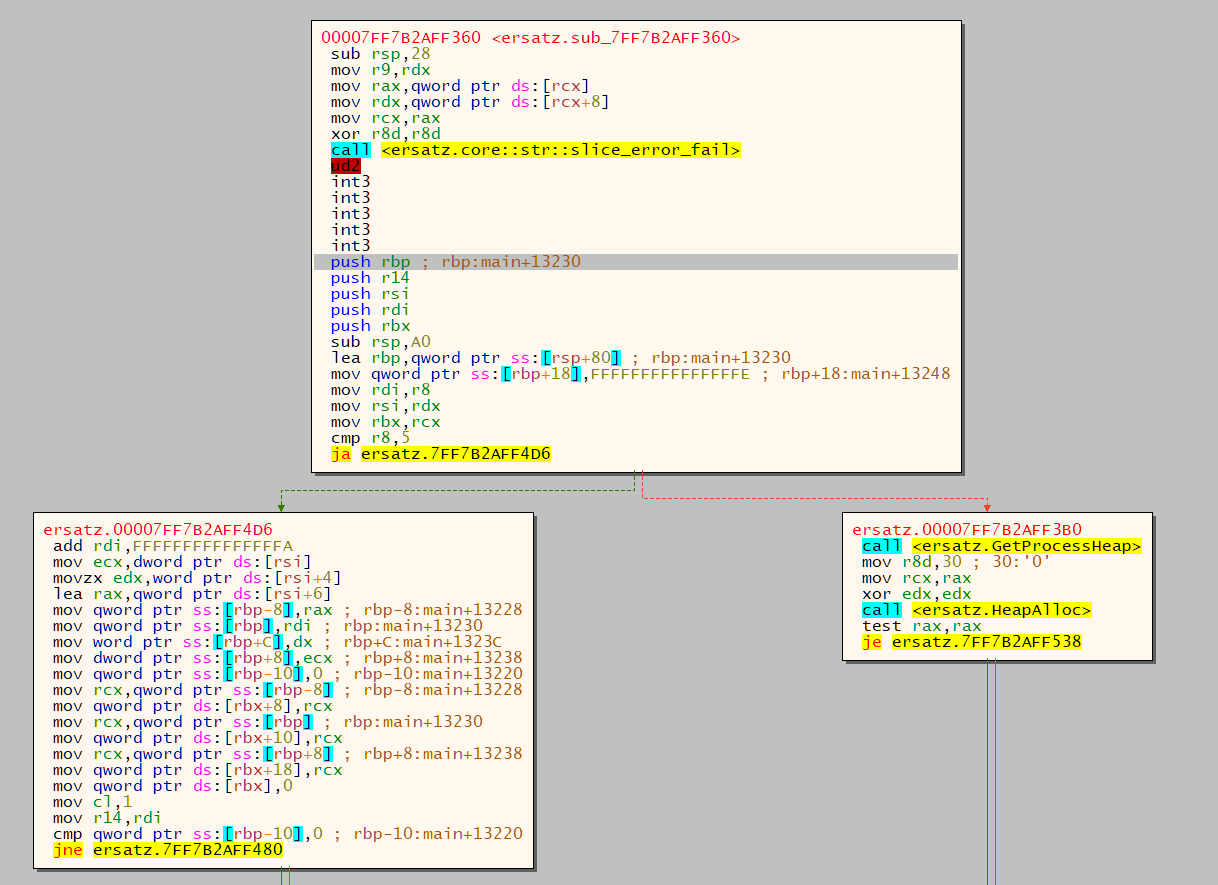
Mhhh is it? Let's look a little further down the graph...
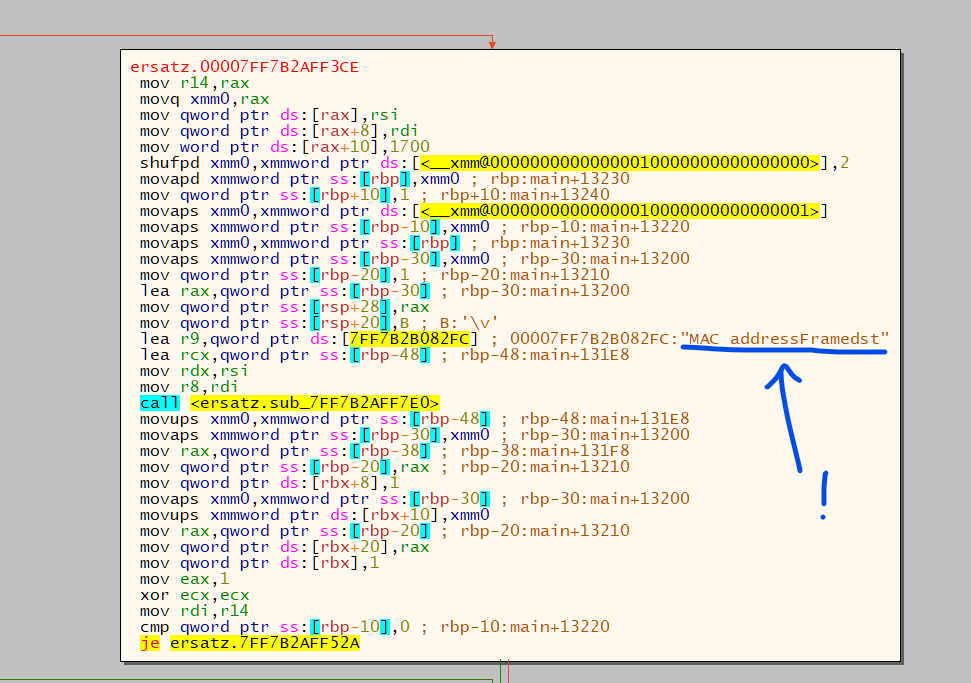
It is!
I also cannot see any trace of ToUsize::to_usize anymore, which means
rustc / LLVM / MSVC worked together to successfully perform cross-crate inlining.
Epilogue
This has been a long article, but we've got everything we need to finish
this series. Well, except the ability to send traffic, but I promise you
the rawsock crate will also let us do that.
In the meantime, we'll just slowly chip away at IPv4, and ICMP.. and then rebuild
them from the ground up to come up with the ultimate, userland-networking-powered,
version of sup.
This article is part 9 of the Making our own ping series.
If you liked what you saw, please support my work!

