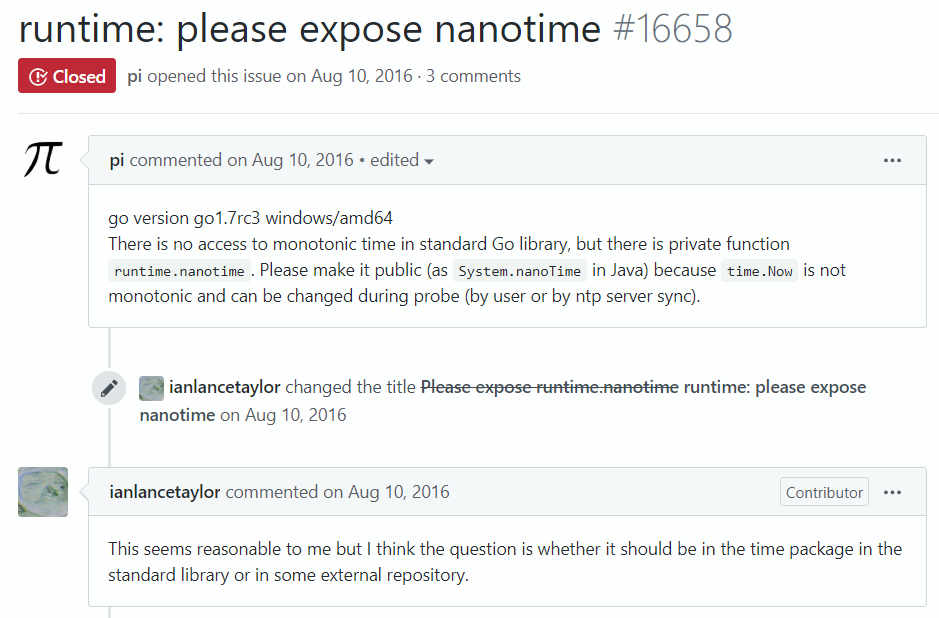
I want off Mr. Golang's Wild Ride
- Garden-variety takes on Go
- Simple is a lie
- Lots of little things
- Parting words
- April 2022 Update
Contents
My honeymoon with the Go language is extremely over.
This article is going to have a different tone from what I've been posting the past year - it's a proper rant. And I always feel bad writing those, because, inevitably, it discusses things a lot of people have been working very hard on.
In spite of that, here we are.
Having invested thousands of hours into the language, and implemented several critical (to my employer) pieces of infrastructure with it, I wish I hadn't.
If you're already heavily invested in Go, you probably shouldn't read this, it'll probably just twist the knife. If you work on Go, you definitely shouldn't read this.
I've been suffering Go's idiosyncracies in relative silence for too long, there's a few things I really need to get off my chest.
Alright? Alright.
Garden-variety takes on Go
By now, everybody knows Go doesn't have generics, which makes a lot of problems impossible to model accurately (instead, you have to fall back to reflection, which is extremely unsafe, and the API is very error-prone), error handling is wonky (even with your pick of the third-party libraries that add context or stack traces), package management took a while to arrive, etc.
But everybody also knows Go's strengths: static linking makes binaries easy to deploy (although, Go binaries get very large, even if you strip DWARF tables - stack trace annotations still remain, and are costly).
Compile times are short (unless you need cgo), there's an interactive runtime profiler (pprof) at arm's reach, it's relatively cross-platform (there's even a tiny variant for embedded), it's easy to syntax-highlight, and there's now an official LSP server for it.
I've accepted all of these - the good and the bad.
We're here to talk about the ugly.
Simple is a lie
Over and over, every piece of documentation for the Go language markets it as "simple".
This is a lie.
Or rather, it's a half-truth that conveniently covers up the fact that, when you make something simple, you move complexity elsewhere.
Computers, operating systems, networks are a hot mess. They're barely manageable, even if you know a decent amount about what you're doing. Nine out of ten software engineers agree: it's a miracle anything works at all.
So all the complexity is swept under the rug. Hidden from view, but not solved.
Here's a simple example.
This example does go on for a while, actually - but don't let the specifics distract you. While it goes rather in-depth, it illustrates a larger point.
Most of Go's APIs (much like NodeJS's APIs) are designed for Unix-like operating systems. This is not surprising, as Rob & Ken are from the Plan 9 gang.
So, the file API in Go looks like this:
// File represents an open file descriptor.
type File struct {
*file // os specific
}
func (f *File) Stat() (FileInfo, error) {
// omitted
}
// A FileInfo describes a file and is returned by Stat and Lstat.
type FileInfo interface {
Name() string // base name of the file
Size() int64 // length in bytes for regular files; system-dependent for others
Mode() FileMode // file mode bits
ModTime() time.Time // modification time
IsDir() bool // abbreviation for Mode().IsDir()
Sys() interface{} // underlying data source (can return nil)
}
// A FileMode represents a file's mode and permission bits.
// The bits have the same definition on all systems, so that
// information about files can be moved from one system
// to another portably. Not all bits apply to all systems.
// The only required bit is ModeDir for directories.
type FileMode uint32
// The defined file mode bits are the most significant bits of the FileMode.
// The nine least-significant bits are the standard Unix rwxrwxrwx permissions.
// The values of these bits should be considered part of the public API and
// may be used in wire protocols or disk representations: they must not be
// changed, although new bits might be added.
const (
// The single letters are the abbreviations
// used by the String method's formatting.
ModeDir FileMode = 1 << (32 - 1 - iota) // d: is a directory
ModeAppend // a: append-only
ModeExclusive // l: exclusive use
ModeTemporary // T: temporary file; Plan 9 only
ModeSymlink // L: symbolic link
ModeDevice // D: device file
ModeNamedPipe // p: named pipe (FIFO)
ModeSocket // S: Unix domain socket
ModeSetuid // u: setuid
ModeSetgid // g: setgid
ModeCharDevice // c: Unix character device, when ModeDevice is set
ModeSticky // t: sticky
ModeIrregular // ?: non-regular file; nothing else is known about this file
// Mask for the type bits. For regular files, none will be set.
ModeType = ModeDir | ModeSymlink | ModeNamedPipe | ModeSocket | ModeDevice | ModeCharDevice | ModeIrregular
ModePerm FileMode = 0777 // Unix permission bits
)
Makes sense for a Unix, right?
Every file has a mode, there's even a command that lets you dump it as hex:
$ stat -c '%f' /etc/hosts 81a4 $ stat -c '%f' /usr/bin/man 81ed
And so, a simple Go program can easily grab those "Unix permission bits":
package main
import (
"fmt"
"os"
)
func main() {
arg := os.Args[1]
fi, _ := os.Stat(arg)
fmt.Printf("(%s) mode = %o\n", arg, fi.Mode() & os.ModePerm)
}
$ go run main.go /etc/hosts (/etc/hosts) mode = 644 $ go run main.go /usr/bin/man (/usr/bin/man) mode = 755
On Windows, files don't have modes. It doesn't have stat, lstat, fstat
syscalls - it has a FindFirstFile family of functions (alternatively,
CreateFile to open, then GetFileAttributes, alternatively,
GetFileInformationByHandle), which takes a pointer to a WIN32_FIND_DATA
structure, which contains file
attributes.
So, what happens if you run that program on Windows?
> go run main.go C:\Windows\notepad.exe (C:\Windows\notepad.exe) mode = 666
It makes up a mode.
// src/os/types_windows.go
func (fs *fileStat) Mode() (m FileMode) {
if fs == &devNullStat {
return ModeDevice | ModeCharDevice | 0666
}
if fs.FileAttributes&syscall.FILE_ATTRIBUTE_READONLY != 0 {
m |= 0444
} else {
m |= 0666
}
if fs.isSymlink() {
return m | ModeSymlink
}
if fs.FileAttributes&syscall.FILE_ATTRIBUTE_DIRECTORY != 0 {
m |= ModeDir | 0111
}
switch fs.filetype {
case syscall.FILE_TYPE_PIPE:
m |= ModeNamedPipe
case syscall.FILE_TYPE_CHAR:
m |= ModeDevice | ModeCharDevice
}
return m
}
Node.js does the same. There's a single fs.Stats "type" for all platforms.
Using "whatever Unix has" as the lowest common denominator is extremely common in open-source codebases, so it's not surprising.
Let's go a little bit further. On Unix systems, you can change the modes of files, to make them read-only, or flip the executable bit.
package main
import (
"fmt"
"os"
)
func main() {
arg := os.Args[1]
fi, err := os.Stat(arg)
must(err)
fmt.Printf("(%s) old mode = %o\n", arg, fi.Mode()&os.ModePerm)
must(os.Chmod(arg, 0755))
fi, err = os.Stat(arg)
must(err)
fmt.Printf("(%s) new mode = %o\n", arg, fi.Mode()&os.ModePerm)
}
func must(err error) {
if err != nil {
panic(err)
}
}
Let's run this on Linux:
$ touch test.txt $ go run main.go test.txt (test.txt) old mode = 644 (test.txt) new mode = 755
And now on Windows:
> go run main.go test.txt (test.txt) old mode = 666 (test.txt) new mode = 666
So, no errors. Chmod just silently does... nothing. Which is reasonable -
there's no equivalent to the "executable bit" for files on Windows.
What does Chmod even do on Windows?
// src/syscall/syscall_windows.go
func Chmod(path string, mode uint32) (err error) {
p, e := UTF16PtrFromString(path)
if e != nil {
return e
}
attrs, e := GetFileAttributes(p)
if e != nil {
return e
}
if mode&S_IWRITE != 0 {
attrs &^= FILE_ATTRIBUTE_READONLY
} else {
attrs |= FILE_ATTRIBUTE_READONLY
}
return SetFileAttributes(p, attrs)
}
It sets or clears the read-only bit. That's it.
We have an uint32 argument, with four billion two hundred ninety-four
million nine hundred sixty-seven thousand two hundred ninety-five possible
values, to encode... one bit of information.
That's a pretty innocent lie. The assumption that files have modes was baked into the API design from the start, and now, everyone has to live with it. Just like in Node.JS, and probably tons of other languages.
But it doesn't have to be like that.
A language with a more involved type system, and better designed libraries could avoid that pitfall.
Out of curiosity, what does Rust do?
Oh, here we go again - Rust, Rust, and Rust again.
Why always Rust?
Well, I tried real hard to keep Rust out of all of this. Among other things, because people are going to dismiss this article as coming from "a typical rustacean".
But for all the problems I raise in this article... Rust gets it right. If I had another good example, I'd use it. But I don't, so, here goes.
There's no stat-like function in the Rust standard library. There's
std::fs::metadata:
pub fn metadata<P: AsRef<Path>>(path: P) -> Result<Metadata>
This function signatures tells us a lot already. It returns a Result, which
means, not only do we know this can fail, we have to handle it. Either by
panicking on error, with .unwrap() or .expect(), or by matching it against
Result::Ok / Result::Err, or by bubbling it up with the ? operator.
The point is, this function signature makes it impossible for us to access
an invalid/uninitialized/null Metadata. With a Go function, if you ignore the
returned error, you still get the result - most probably a null pointer.
Also, the argument is not a string - it's a path. Or rather, it's something that can be turned into a path.
And String does implement
AsRef<Path>,
so, for simple use cases, it's not troublesome:
fn main() {
let metadata = std::fs::metadata("Cargo.toml").unwrap();
println!("is dir? {:?}", metadata.is_dir());
println!("is file? {:?}", metadata.is_file());
}
But paths are not necessarily strings. On Unix (!), paths can be any sequence of bytes, except null bytes.
$ cd rustfun/ $ touch "$(printf "\xbd\xb2\x3d\xbc\x20\xe2\x8c\x98")" $ ls ls: cannot compare file names ‘Cargo.lock’ and ‘\275\262=\274 ⌘’: Invalid or incomplete multibyte or wide character src target Cargo.lock Cargo.toml ''$'\275\262''='$'\274'' ⌘'
We've just made a file with a very naughty name - but it's a perfectly
valid file, even if ls struggles with it.
$ stat "$(printf "\xbd\xb2\x3d\xbc\x20\xe2\x8c\x98")" File: = ⌘ Size: 0 Blocks: 0 IO Block: 65536 regular empty file Device: 8c70d496h/2356204694d Inode: 72620543991375285 Links: 1 Access: (0644/-rw-r--r--) Uid: (197611/ amos) Gid: (197611/ amos) Access: 2020-02-28 13:12:12.783734000 +0100 Modify: 2020-02-28 13:12:12.783734000 +0100 Change: 2020-02-28 13:12:12.783329400 +0100 Birth: 2020-02-28 13:12:12.783329400 +0100
That's not something we can represent with a String in Rust, because Rust
Strings are valid utf-8, and this isn't.
Rust Paths, however, are... arbitrary byte sequences.
And so, if we use std::fs::read_dir, we have no problem listing it and
getting its metadata:
use std::fs;
fn main() {
let entries = fs::read_dir(".").unwrap();
for entry in entries {
let path = entry.unwrap().path();
let meta = fs::metadata(&path).unwrap();
if meta.is_dir() {
println!("(dir) {:?}", path);
} else {
println!(" {:?}", path);
}
}
}
$ cargo run --quiet
(dir) "./src"
"./Cargo.toml"
"./.gitignore"
"./\xBD\xB2=\xBC ⌘"
(dir) "./.git"
"./Cargo.lock"
(dir) "./target"
What about Go?
package main
import (
"fmt"
"os"
)
func main() {
arg := os.Args[1]
f, err := os.Open(arg)
must(err)
entries, err := f.Readdir(-1)
must(err)
for _, e := range entries {
if e.IsDir() {
fmt.Printf("(dir) %s\n", e.Name())
} else {
fmt.Printf(" %s\n", e.Name())
}
}
}
func must(err error) {
if err != nil {
panic(err)
}
}
$ go build
$ ./gofun ../rustfun
(dir) src
Cargo.toml
.gitignore
= ⌘
(dir) .git
Cargo.lock
(dir) target
It... silently prints a wrong version of the path.
See, there's no "path" type in Go. Just "string". And Go strings are just byte slices, with no guarantees about what's inside.
So it prints garbage, whereas in Rust, Path does not implement Display, so
we couldn't do this:
println!("(dir) {}", path);
We had to do this:
println!("(dir) {:?}", path);
And if we wanted a friendlier output, we could handle both cases: when the path happens to be a valid utf-8 string, and when it doesn't:
use std::fs;
fn main() {
let entries = fs::read_dir(".").unwrap();
for entry in entries {
let path = entry.unwrap().path();
let meta = fs::metadata(&path).unwrap();
let prefix = if meta.is_dir() {
"(dir)"
} else {
" "
};
match path.to_str() {
Some(s) => println!("{} {}", prefix, s),
None => println!("{} {:?} (invalid utf-8)", prefix, path),
}
}
}
$ cargo run --quiet
(dir) ./src
./Cargo.toml
./.gitignore
"./\xBD\xB2=\xBC ⌘" (invalid utf-8)
(dir) ./.git
./Cargo.lock
(dir) ./target
Go says "don't worry about encodings! things are probably utf-8".
Except when they aren't. And paths aren't. So, in Go, all path manipulation
routines operate on string, let's take a look at the path/filepath package.
Package filepath implements utility routines for manipulating filename paths in a way compatible with the target operating system-defined file paths.
The filepath package uses either forward slashes or backslashes, depending on the operating system. To process paths such as URLs that always use forward slashes regardless of the operating system, see the path package.
What does this package give us?
func Abs(path string) (string, error) func Base(path string) string func Clean(path string) string func Dir(path string) string func EvalSymlinks(path string) (string, error) func Ext(path string) string func FromSlash(path string) string func Glob(pattern string) (matches []string, err error) func HasPrefix(p, prefix string) bool func IsAbs(path string) bool func Join(elem ...string) string func Match(pattern, name string) (matched bool, err error) func Rel(basepath, targpath string) (string, error) func Split(path string) (dir, file string) func SplitList(path string) []string func ToSlash(path string) string func VolumeName(path string) string func Walk(root string, walkFn WalkFunc) error
Strings. Lots and lots of strings. Well, byte slices.
Speaking of bad design decisions - what's that Ext function I see?
// Ext returns the file name extension used by path. The extension is the suffix // beginning at the final dot in the final element of path; it is empty if there // is no dot. func Ext(path string) string
Interesting! Let's try it out.
package main
import (
"fmt"
"path/filepath"
)
func main() {
inputs := []string{
"/",
"/.",
"/.foo",
"/foo",
"/foo.txt",
"/foo.txt/bar",
"C:\\",
"C:\\.",
"C:\\foo.txt",
"C:\\foo.txt\\bar",
}
for _, i := range inputs {
fmt.Printf("%24q => %q\n", i, filepath.Ext(i))
}
}
func must(err error) {
if err != nil {
panic(err)
}
}
$ go run main.go
"/" => ""
"/." => "."
"/.foo" => ".foo"
"/foo" => ""
"/foo.txt" => ".txt"
"/foo.txt/bar" => ""
"C:\\" => ""
"C:\\." => "."
"C:\\foo.txt" => ".txt"
"C:\\foo.txt\\bar" => ".txt\\bar"
Right away, I'm in debating mood - is .foo's extension really .foo? But
let's move on.
This example was run on Linux, so C:\foo.txt\bar's extension, according
to filepath.Ext, is.. .txt\bar.
Why? Because the Go standard library makes the assumption that a platform has
a single path separator - on Unix and BSD-likes, it's /, and on Windows
it's \\.
Except... that's not the whole truth. I was curious, so I checked:
// in `fun.c`
void main() {
HANDLE hFile = CreateFile("C:/Users/amos/test.txt", GENERIC_WRITE, 0, NULL,
CREATE_NEW, FILE_ATTRIBUTE_NORMAL, NULL);
char *data = "Hello from the Win32 API";
DWORD dwToWrite = (DWORD) strlen(data);
DWORD dwWritten = 0;
WriteFile(hFile, data, dwToWrite, &dwWritten, NULL);
CloseHandle(hFile);
}
> cl fun.c Microsoft (R) C/C++ Optimizing Compiler Version 19.23.28107 for x64 Copyright (C) Microsoft Corporation. All rights reserved. fun.c Microsoft (R) Incremental Linker Version 14.23.28107.0 Copyright (C) Microsoft Corporation. All rights reserved. /out:fun.exe fun.obj > .\fun.exe > type C:\Users\amos\test.txt Hello from the Win32 API
No funny Unix emulation business going on - just regular old Windows 10.
And yet, in Go's standard library, the path/filepath package exports those
constants:
const (
Separator = os.PathSeparator
ListSeparator = os.PathListSeparator
)
os, in turn, exports:
// src/os/path_windows.go const ( PathSeparator = '\\' // OS-specific path separator PathListSeparator = ';' // OS-specific path list separator )
So how comes filepath.Ext works with both separators on Windows?
$ go run main.go
"/" => ""
"/." => "."
"/.foo" => ".foo"
"/foo" => ""
"/foo.txt" => ".txt"
"/foo.txt/bar" => ""
"C:\\" => ""
"C:\\." => "."
"C:\\foo.txt" => ".txt"
"C:\\foo.txt\\bar" => ""
Let's look at its implementation:
// src/path/filepath/path.go
func Ext(path string) string {
for i := len(path) - 1; i >= 0 && !os.IsPathSeparator(path[i]); i-- {
if path[i] == '.' {
return path[i:]
}
}
return ""
}
Ah. An IsPathSeparator function.
Sure enough:
// src/os/path_windows.go
// IsPathSeparator reports whether c is a directory separator character.
func IsPathSeparator(c uint8) bool {
// NOTE: Windows accept / as path separator.
return c == '\\' || c == '/'
}
(Can I just point out how hilarious that "Extension" was deemed long enough to abbreviate to "Ext", but "IsPathSeparator" wasn't?)
How does Rust handle this?
It has std::path::is_separator:
/// Determines whether the character is one of the permitted // path separators for the current platform. pub fn is_separator(c: char) -> bool
And it has std::path::MAIN_SEPARATOR - emphasis on main separator:
/// The primary separator of path components for the current platform. /// /// For example, / on Unix and \ on Windows. pub const MAIN_SEPARATOR: char
The naming alone makes it much clearer that there might be secondary path separators, and the rich Path manipulation API makes it much less likely to find this kind of code, for example:
DefaultScripts = "downloads" + string(os.PathSeparator) + "defaultScripts"
Or this kind:
if os.PathSeparator == '/' {
projname = strings.Replace(name, "\\", "/", -1)
} else if os.PathSeparator == '\\' {
projname = strings.Replace(name, "/", "\\", -1)
}
Or this... kind:
filefullpath = fmt.Sprintf("%s%c%s%c%s%c%s%c%s%s",
a.DataDir, os.PathSeparator,
m[0:1], os.PathSeparator,
m[1:2], os.PathSeparator,
m[2:3], os.PathSeparator,
m, ext)
It turns out Rust also has a "get a path's extension" function, but it's a lot more conservative in the promises it makes:
// Extracts the extension of self.file_name, if possible. // // The extension is: // // * None, if there is no file name; // * None, if there is no embedded .; // * None, if the file name begins with . and has no other .s within; // * Otherwise, the portion of the file name after the final . pub fn extension(&self) -> Option<&OsStr>
Let's submit it to the same test:
fn main() {
let inputs = [
r"/",
r"/.",
r"/.foo",
r"/foo.",
r"/foo",
r"/foo.txt",
r"/foo.txt/bar",
r"C:\",
r"C:\.",
r"C:\foo.txt",
r"C:\foo.txt\bar",
];
for input in &inputs {
use std::path::Path;
println!("{:>20} => {:?}", input, Path::new(input).extension());
}
}
On Linux:
$ cargo run --quiet
/ => None
/. => None
/.foo => None
/foo. => Some("")
/foo => None
/foo.txt => Some("txt")
/foo.txt/bar => None
C:\ => None
C:\. => Some("")
C:\foo.txt => Some("txt")
C:\foo.txt\bar => Some("txt\\bar")
On Windows:
$ cargo run --quiet
/ => None
/. => None
/.foo => None
/foo. => Some("")
/foo => None
/foo.txt => Some("txt")
/foo.txt/bar => None
C:\ => None
C:\. => None
C:\foo.txt => Some("txt")
C:\foo.txt\bar => None
Like Go, it gives a txt\bar extension for a Windows path on Linux.
Unlike Go, it:
- Doesn't think "/.foo" has a file extension
- Distinguishes between the "/foo." case (
Some("")) and the "/foo" case (None)
Let's also look at the Rust implementation of std::path::Path::extension:
pub fn extension(&self) -> Option<&OsStr> {
self.file_name().map(split_file_at_dot).and_then(|(before, after)| before.and(after))
}
Let's dissect that: first it calls file_name(). How does that work? Is it where
it searches for path separators backwards from the end of the path?
pub fn file_name(&self) -> Option<&OsStr> {
self.components().next_back().and_then(|p| match p {
Component::Normal(p) => Some(p.as_ref()),
_ => None,
})
}
No! It calls components which returns a type that implements DoubleEndedIterator -
an iterator you can navigate from the front or the back. Then it grabs the first item
from the back - if any - and returns that.
The iterator does look for path separators - lazily, in a re-usable way. There is no code duplication, like in the Go library:
// src/os/path_windows.go
func dirname(path string) string {
vol := volumeName(path)
i := len(path) - 1
for i >= len(vol) && !IsPathSeparator(path[i]) {
i--
}
dir := path[len(vol) : i+1]
last := len(dir) - 1
if last > 0 && IsPathSeparator(dir[last]) {
dir = dir[:last]
}
if dir == "" {
dir = "."
}
return vol + dir
}
So, now we have only the file name. If we had /foo/bar/baz.txt, we're now only
dealing with baz.txt - as an OsStr, not a utf-8 String. We can still have
random bytes.
We then map this result through split_file_at_dot, which behaves like so:
- For
"foo", return(Some("foo"), None) - For
"foo.bar", return(Some("foo"), Some("bar")) - For
"foo.bar.baz", return(Some("foo.bar"), Some("baz"))
and_then, we only return after if before wasn't None.
If we spelled out everything, we'd have:
pub fn extension(&self) -> Option<&OsStr> {
if let Some(file_name) = self.file_name() {
let (before, after) = split_file_at_dot(file_name);
if let Some(before) = before {
// note: `after` is already an `Option<&OsStr>` - it
// might still be `None`.
return after
}
}
None
}
The problem is carefully modelled. We can look at what we're manipulating
just by looking at its type. If it might not exist, it's an Option<T>! If
it's a path with multiple components, it's a &Path (or its owned
counterpart, PathBuf). If it's just part of a path, it's an &OsStr.
Of course there's a learning curve. Of course there's more concepts involved than just throwing for loops at byte slices and seeing what sticks, like the Go library does.
But the result is a high-performance, reliable and type-safe library.
It's worth it.
Speaking of Rust, we haven't seen how it handles the whole "mode" thing yet.
So std::fs::Metadata has is_dir() and is_file(), which return booleans.
It also has len(), which returns an u64 (unsigned 64-bit integer).
It has created(), modified(), and accessed(), all of which return an
Option<SystemTime>. Again - the types inform us on what scenarios are
possible. Access timestamps might not exist at all.
The returned time is not an std::time::Instant - it's an
std::time::SystemTime - the documentation tells us the difference:
A measurement of the system clock, useful for talking to external entities like the file system or other processes.
Distinct from the
Instanttype, this time measurement is not monotonic. This means that you can save a file to the file system, then save another file to the file system, and the second file has aSystemTimemeasurement earlier than the first. In other words, an operation that happens after another operation in real time may have an earlierSystemTime!Consequently, comparing two
SystemTimeinstances to learn about the duration between them returns aResultinstead of an infallibleDurationto indicate that this sort of time drift may happen and needs to be handled.Although a
SystemTimecannot be directly inspected, theUNIX_EPOCHconstant is provided in this module as an anchor in time to learn information about aSystemTime. By calculating the duration from this fixed point in time, aSystemTimecan be converted to a human-readable time, or perhaps some other string representation.The size of a
SystemTimestruct may vary depending on the target operating system.Source: https://doc.rust-lang.org/std/time/struct.SystemTime.html
In fairness to everyone, monotonic time is really hard.
What about permissions? Well, there it is:
pub fn permissions(&self) -> Permissions
A Permissions type! Just for that! And we can afford it, too - because
types don't cost anything at runtime. Everything probably ends up inlined
anyway.
What does it expose?
pub fn readonly(&self) -> bool {}
pub fn set_readonly(&mut self, readonly: bool) {}
Well! It exposes only what all supported operating systems have in common.
Can we still get Unix permission? Of course! But only on Unix:
Representation of the various permissions on a file.
This module only currently provides one bit of information,
readonly, which is exposed on all currently supported platforms. Unix-specific functionality, such as mode bits, is available through thePermissionsExttrait.Source: https://doc.rust-lang.org/std/fs/struct.Permissions.html
std::os::unix::fs::PermissionsExt is only compiled in on Unix, and exposes
the following functions:
fn mode(&self) -> u32 {}
fn set_mode(&mut self, mode: u32) {}
fn from_mode(mode: u32) -> Self {}
The documentation makes it really clear it's Unix-only:
But it's not just documentation. This sample program will compile and run on Linux (and macOS, etc.)
use std::fs::File;
use std::os::unix::fs::PermissionsExt;
fn main() -> std::io::Result<()> {
let f = File::open("/usr/bin/man")?;
let metadata = f.metadata()?;
let permissions = metadata.permissions();
println!("permissions: {:o}", permissions.mode());
Ok(())
}
$ cargo run --quiet permissions: 100755
But will fail to compile on Windows:
$ cargo run --quiet
error[E0433]: failed to resolve: could not find `unix` in `os`
--> src\main.rs:2:14
|
2 | use std::os::unix::fs::PermissionsExt;
| ^^^^ could not find `unix` in `os`
error[E0599]: no method named `mode` found for type `std::fs::Permissions` in the current scope
--> src\main.rs:9:47
|
9 | println!("permissions: {:o}", permissions.mode());
| ^^^^ method not found in `std::fs::Permissions`
error: aborting due to 2 previous errors
Some errors have detailed explanations: E0433, E0599.
For more information about an error, try `rustc --explain E0433`.
error: could not compile `rustfun`.
To learn more, run the command again with --verbose.
How can we make a program that runs on Windows too? The same way
the standard library only exposes PermissionsExt on Unix: with
attributes.
use std::fs::File;
#[cfg(target_family = "unix")]
use std::os::unix::fs::PermissionsExt;
fn main() -> std::io::Result<()> {
let arg = std::env::args().nth(1).unwrap();
let f = File::open(&arg)?;
let metadata = f.metadata()?;
let permissions = metadata.permissions();
#[cfg(target_family = "unix")]
{
println!("permissions: {:o}", permissions.mode());
}
#[cfg(target_family = "windows")]
{
println!("readonly? {:?}", permissions.readonly());
}
Ok(())
}
Those aren't #ifdef - they're not preprocessor directives. There's no risk
of forgetting an #endif. And if you miss if/else chains, there's a crate
for that.
Here's that sample program on Linux:
$ cargo run --quiet -- /usr/bin/man permissions: 100755
And on Windows:
$ cargo run --quiet -- Cargo.toml readonly? false
Can you do that in Go? Sure! Kind of!
There's two ways to do something similar, and both involve multiple files.
Here's one:
$ go mod init github.com/fasterthanlime/gofun
In main.go, we need:
package main
import "os"
func main() {
poke(os.Args[1])
}
In poke_windows.go, we need:
package main
import (
"fmt"
"os"
)
func poke(path string) {
stats, _ := os.Stat(path)
fmt.Printf("readonly? %v\n", (stats.Mode() & 0o600) == 0);
}
And in poke_unix.go, we need:
// +build !windows
package main
import (
"fmt"
"os"
)
func poke(path string) {
stats, _ := os.Stat(path)
fmt.Printf("permissions: %o\n", stats.Mode() & os.ModePerm);
}
Note how the _windows.go suffix is magic - it'll get automatically excluded
on non-Windows platforms. There's no magic suffix for Unix systems though!
So we have to add a build constraint, which is:
- A comment
- That must be "near the top of the file"
- That can only be preceded by blank space
- That must appear before the package clause
- That has its own language
From the docs:
A build constraint is evaluated as the OR of space-separated options. Each option evaluates as the AND of its comma-separated terms. Each term consists of letters, digits, underscores, and dots. A term may be negated with a preceding !. For example, the build constraint:
// +build linux,386 darwin,!cgocorresponds to the boolean formula:
(linux AND 386) OR (darwin AND (NOT cgo))A file may have multiple build constraints. The overall constraint is the AND of the individual constraints. That is, the build constraints:
// +build linux darwin>// +build 386corresponds to the boolean formula:
(linux OR darwin) AND 386
Fun! Fun fun fun. So, on Linux, we get:
$ go build $ ./gofun /usr/bin/man permissions: 755 $ ./gofun /etc/hosts permissions: 644
And on Windows, we get:
> go build > .\gofun.exe .\main.go readonly? false
Now, at least there's a way to write platform-specific code in Go.
In practice, it gets old very quickly. You now have related code split across multiple files, even if only one of the functions is platform-specific.
Build constraints override the magic suffixes, so it's never obvious exactly which files are compiled in. You also have to duplicate (and keep in sync!) function signatures all over the place.
It's... a hack. A shortcut. And an annoying one, at that.
So what happens when you make it hard for users to do things the right way? (The right way being, in this case, to not compile in code that isn't relevant for a given platform). They take shortcuts, too.
Even in the official Go distribution, a lot of code just switches on the value
of runtime.GOOS at, well, run-time:
// src/net/file_test.go
func TestFileConn(t *testing.T) {
switch runtime.GOOS {
case "plan9", "windows":
t.Skipf("not supported on %s", runtime.GOOS)
}
for _, tt := range fileConnTests {
if !testableNetwork(tt.network) {
t.Logf("skipping %s test", tt.network)
continue
}
"But these are little things!"
They're all little things. They add up. Quickly.
And they're symptomatic of the problems with "the Go way" in general. The Go way is to half-ass things.
The Go way is to patch things up until they sorta kinda work, in the name of simplicity.
Lots of little things
Speaking of little things, let's consider what pushed me over the edge and provoked me to write this whole rant in the first place.
It was this package.
What does it do?
Provides mechanisms for adding idle timeouts to
net.Connandnet.Listener.
Why do we need it?
Because the real-world is messy.
If you do a naive HTTP request in Go:
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
res, err := http.Get("http://perdu.com")
must(err)
defer res.Body.Close() // this is a *very* common gotcha
body, err := ioutil.ReadAll(res.Body)
must(err)
fmt.Printf("%s", string(body))
}
func must(err error) {
if err != nil {
panic(err)
}
}
$ go run main.go <html><head><title>Vous Etes Perdu ?</title></head><body><h1>Perdu sur l'Internet ?</h1><h2>Pas de panique, on va vous aider</h2><strong><pre> * <----- vous êtes ici</pre></strong></body></html>
Then it works. When it works.
If the server never accepts your connection - which might definitely happen if it's dropping all the traffic to the relevant port, then you'll just hang forever.
If you don't want to hang forever, you have to do something else.
Like this:
package main
import (
"fmt"
"io/ioutil"
"net"
"net/http"
"time"
)
func main() {
client := &http.Client{
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: 5 * time.Second,
}).DialContext,
},
}
req, err := http.NewRequest("GET", "http://perdu.com", nil)
must(err)
res, err := client.Do(req)
must(err)
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
must(err)
fmt.Printf("%s", string(body))
}
func must(err error) {
if err != nil {
panic(err)
}
}
Not so simple, but, eh, whatever, it works.
Unless the server accepts your connection, says it's going to send a bunch of bytes, and then never sends you anything.
Which definitely, 100%, for-sure, if-it-can-happen-it-does-happen, happens.
And then you hang forever.
To avoid that, you can set a timeout on the whole request, like so:
package main
import (
"context"
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
req, err := http.NewRequestWithContext(ctx, "GET", "http://perdu.com", nil)
must(err)
res, err := http.DefaultClient.Do(req)
must(err)
defer res.Body.Close()
body, err := ioutil.ReadAll(res.Body)
must(err)
fmt.Printf("%s", string(body))
}
func must(err error) {
if err != nil {
panic(err)
}
}
But that doesn't work if you're planning on uploading something large, for example. How many seconds is enough to upload a large file? Is 30 seconds enough? And how do you know you're spending those seconds uploading, and not waiting for the server to accept your request?
So, getlantern/idletiming adds a mechanism for timing out if there hasn't
been any data transmitted in a while, which is distinct from a dial timeout,
and doesn't force you to set a timeout on the whole request, so that it
works for arbitrarily large uploads.
The repository looks innocent enough:
Just a couple files! And even some tests. Also - it works. I'm using it in production. I'm happy with it.
There's just.. one thing.
$ git clone https://github.com/getlantern/idletiming Cloning into 'idletiming'... (cut) $ cd idletiming $ go mod graph | wc -l 196
I'm sorry?
One hundred and ninety-six packages?
Well, I mean... lots of small, well-maintained libraries isn't necessarily a
bad idea - I never really agreed that the takeaway from the left-pad disaster
was "small libraries are bad".
Let's look at what we've got there:
$ go mod graph github.com/getlantern/idletiming github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/getlantern/idletiming github.com/getlantern/fdcount@v0.0.0-20190912142506-f89afd7367c4 github.com/getlantern/idletiming github.com/getlantern/golog@v0.0.0-20190830074920-4ef2e798c2d7 github.com/getlantern/idletiming github.com/getlantern/grtrack@v0.0.0-20160824195228-cbf67d3fa0fd github.com/getlantern/idletiming github.com/getlantern/mtime@v0.0.0-20170117193331-ba114e4a82b0 github.com/getlantern/idletiming github.com/getlantern/netx@v0.0.0-20190110220209-9912de6f94fd github.com/getlantern/idletiming github.com/stretchr/testify@v1.4.0
I'm sure all of these are reasonable. Lantern is a "site unblock" product, so
it has to deal with networking a lot, it makes sense that they'd have their
own libraries for a bunch of things, including logging (golog) and some
network extensions (netx). testify is a well-known set of testing
helpers, I use it too!
Let's keep going:
github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/Shopify/sarama@v1.23.1
Uhh....
github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/aristanetworks/fsnotify@v1.4.2 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/aristanetworks/glog@v0.0.0-20180419172825> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/aristanetworks/splunk-hec-go@v0.3.3 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/garyburd/redigo@v1.6.0 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/golang/protobuf@v1.3.2
Wait, I think we..
github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/influxdata/influxdb1-client@v0.0.0-201908> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/klauspost/cpuid@v1.2.1 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/klauspost/reedsolomon@v1.9.2 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/kylelemons/godebug@v1.1.0 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/onsi/ginkgo@v1.10.1 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/onsi/gomega@v1.7.0 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/openconfig/gnmi@v0.0.0-20190823184014-89b> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/openconfig/reference@v0.0.0-2019072701583> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/prometheus/client_golang@v1.1.0
I can understand some of these but...
github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/satori/go.uuid@v1.2.0 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/stretchr/testify@v1.3.0 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/templexxx/cpufeat@v0.0.0-20180724012125-c> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/templexxx/xor@v0.0.0-20181023030647-4e92f> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/tjfoc/gmsm@v1.0.1 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/xtaci/kcp-go@v5.4.5+incompatible github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 github.com/xtaci/lossyconn@v0.0.0-20190602105132-8df> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 golang.org/x/net@v0.0.0-20190912160710-24e19bdeb0f2 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 golang.org/x/sys@v0.0.0-20190912141932-bc967efca4b8 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 golang.org/x/time@v0.0.0-20190308202827-9d24e82272b4 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 golang.org/x/tools@v0.0.0-20190912185636-87d9f09c5d89 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 google.golang.org/grpc@v1.23.1 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 gopkg.in/bsm/ratelimit.v1@v1.0.0-20160220154919-db14> github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 gopkg.in/jcmturner/goidentity.v3@v3.0.0 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 gopkg.in/redis.v4@v4.2.4 github.com/aristanetworks/goarista@v0.0.0-20200131140622-c6473e3ed183 gopkg.in/yaml.v2@v2.2.2
STOP! Just stop. Stop it already.
It keeps going on, and on. There's everything.
YAML, Redis, GRPC, which in turns needs protobuf, InfluxDB, an Apache Kafka client, a Prometheus client, Snappy, Zstandard, LZ4, a chaos-testing TCP proxy, three other logging packages, and client libraries for various Google Cloud services.
What could possibly justify all this?
Let's review:
// `idletiming_listener.go` package idletiming import ( "net" "time" )
Only built-in imports. Good.
// `idletiming_conn.go` // package idletiming provides mechanisms for adding idle timeouts to net.Conn // and net.Listener. package idletiming import ( "errors" "io" "net" "sync" "sync/atomic" "time" "github.com/getlantern/golog" "github.com/getlantern/mtime" "github.com/getlantern/netx" )
This one is the meat of the library, so to say, and it requires a few of the
getlantern packages we've seen:
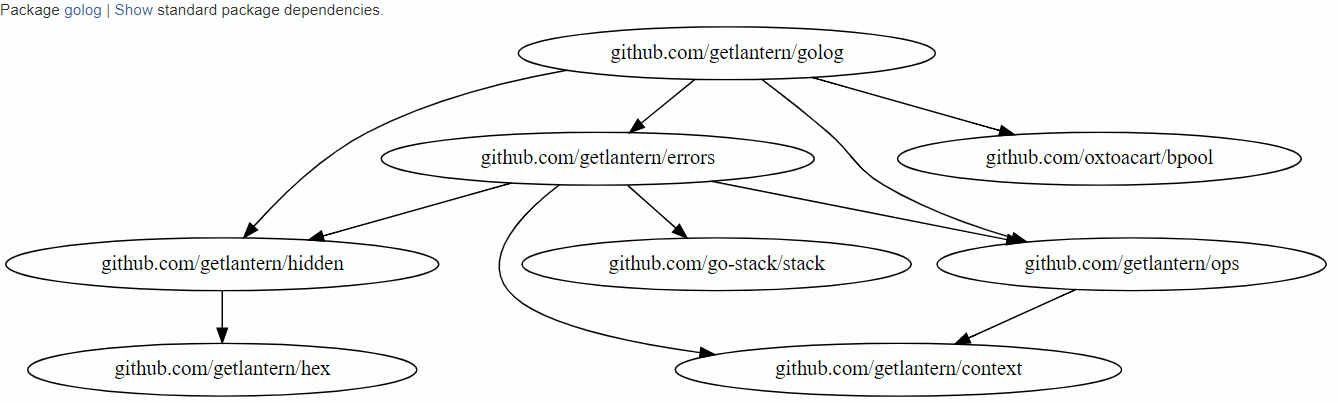
It does end up importing golang.org/x/net/http2/hpack - but that's just because
of net/http. These are built-ins, so let's ignore them for now.
getlantern/hex is self-contained, so, moving on to getlantern/mtime:

That's it? What's why Go ends up fetching the entire
github.com/aristanetworks/goarista repository, and all its transitive
dependencies?
What does aristanetworks/goariasta/monotime even do?
Mh. Let's look inside issue15006.s
// Copyright (c) 2016 Arista Networks, Inc. // Use of this source code is governed by the Apache License 2.0 // that can be found in the COPYING file. // This file is intentionally empty. // It's a workaround for https://github.com/golang/go/issues/15006
I uh... okay.
What does that issue say?
This is known and I think the empty assembly file is the accepted fix.
It's a rarely used feature and having an assembly file also make it standout.
I don't think we should make this unsafe feature easy to use.
And later (emphasis mine):
I agree with Minux. If you're looking at a Go package to import, you might want to know if it does any unsafe trickery. Currently you have to grep for an import of unsafe and look for non-.go files. If we got rid of the requirement for the empty .s file, then you'd have to grep for //go:linkname also.
That's... that's certainly a stance.
But which unsafe feature exactly?
Let's look at nanotime.go:
// Copyright (c) 2016 Arista Networks, Inc.
// Use of this source code is governed by the Apache License 2.0
// that can be found in the COPYING file.
// Package monotime provides a fast monotonic clock source.
package monotime
import (
"time"
_ "unsafe" // required to use //go:linkname
)
//go:noescape
//go:linkname nanotime runtime.nanotime
func nanotime() int64
// Now returns the current time in nanoseconds from a monotonic clock.
// The time returned is based on some arbitrary platform-specific point in the
// past. The time returned is guaranteed to increase monotonically at a
// constant rate, unlike time.Now() from the Go standard library, which may
// slow down, speed up, jump forward or backward, due to NTP activity or leap
// seconds.
func Now() uint64 {
return uint64(nanotime())
}
// Since returns the amount of time that has elapsed since t. t should be
// the result of a call to Now() on the same machine.
func Since(t uint64) time.Duration {
return time.Duration(Now() - t)
}
That's it. That's the whole package.
The unsafe feature in question is being able to access unexported (read: lowercase, sigh) symbols from the Go standard library.
Why is that even needed?
If you remember from earlier, Rust has two types for time: SystemTime,
which corresponds to your... system's... time, which can be adjusted via
NTP. It can go
back, so subtraction can fail.
And it has Instant, which is weakly monotonically increasing - at worse,
it'll give the same value twice, but never less than the previous value.
This is useful to measure elapsed time within a process.
How did Go solve that problem?
At first, it didn't. Monotonic time measurement is a hard problem, so it was only available internally, in the standard library, not for regular Go developers (a common theme):
And then, it did.
Sort of. In the most "Go way" possible.
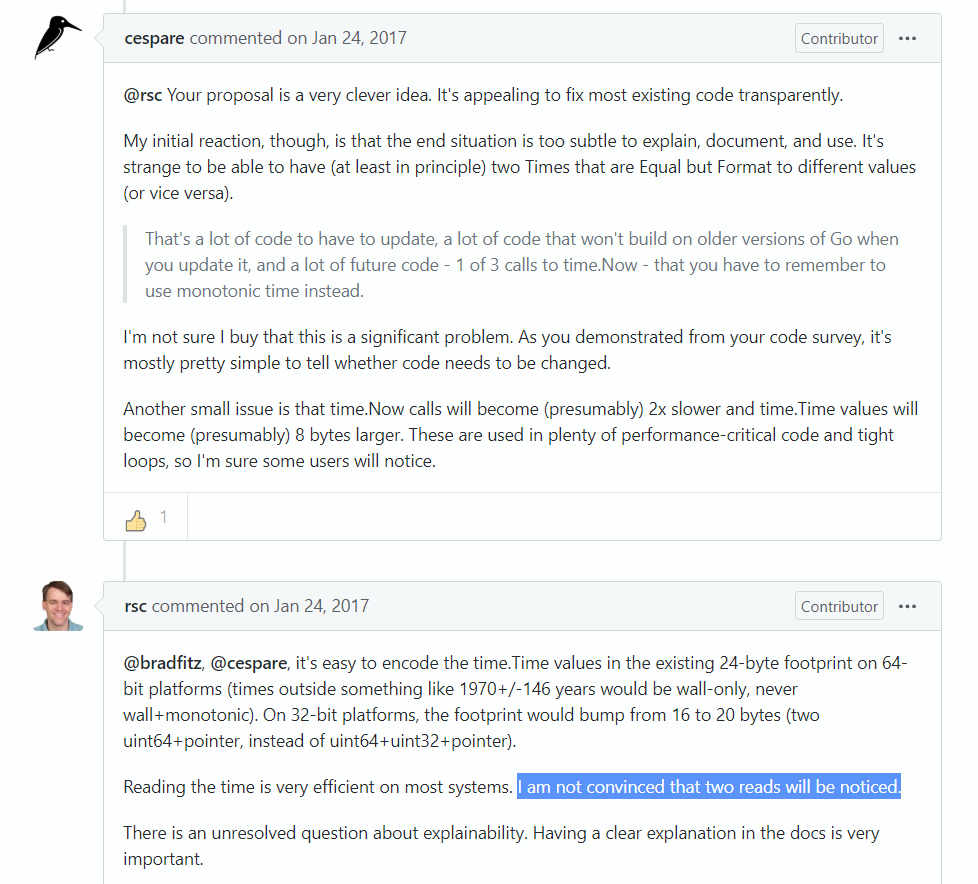
I thought some more about the suggestion above to reuse
time.Timewith a special location. The special location still seems wrong, but what if we reusetime.Timeby storing inside it both a wall time and a monotonic time, fetched one after the other?Then there are two kinds of
time.Times: those with wall and monotonic stored inside (let's call those "wall+monotonic Times") and those with only wall stored inside (let's call those "wall-only Times").Suppose further that:
time.Nowreturns a wall+monotonic Time.- for
t.Add(d), if t is a wall+monotonic Time, so is the result; if t is wall-only, so is the result.- all other functions that return Times return wall-only Times. These include:
time.Date,time.Unix,t.AddDate,t.In,t.Local,t.Round,t.Truncate,t.UTC- for
t.Sub(u), if t and u are both wall+monotonic, the result is computed by subtracting monotonics; otherwise the result is computed by subtracting wall times. -t.After(u),t.Before(u),t.Equal(u)compare monotonics if available (just liket.Sub(u)), otherwise walls.- all the other functions that operate on time.Times use the wall time only. These include:
t.Day,t.Format,t.Month,t.Unix,t.UnixNano,t.Year, and so on.Doing this returns a kind of hybrid time from
time.Now: it works as a wall time but also works as a monotonic time, and future operations use the right one.
So, as of Go 1.9 - problem solved!
If you're confused by the proposal, no worries, let's check out the release notes:
Transparent Monotonic Time support
The
timepackage now transparently tracks monotonic time in eachTimevalue, making computing durations between twoTimevalues a safe operation in the presence of wall clock adjustments. See the package docs and design document for details.
This changed the behavior of a number of Go packages, but, the core team knows best:
So, if you have a package without a minimum required Go version, you can't be
sure you have the "transparent monotonic time support" of Go 1.9, and it's
better to rely on aristanetworks/goarista/monotime, which pulls 100+ packages,
because Go packages are "simple" and they're just folders in a git repository.
It's not just idletiming that depends on monotime.
As of the time of this writing, 266 publicly-avilable Go packages import it
- and the pull in the hundred plus dependencies with it.
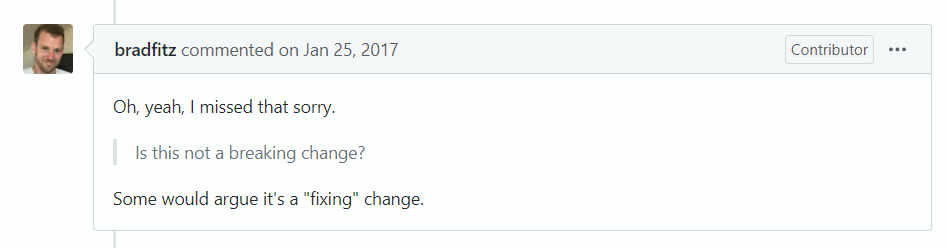
The change raised other questions: since time.Time now sometimes packs two
types of time, two calls are needed. This concern was dismissed.
In order for time.Time not to grow, both values were packed inside it, which
restricted the range of times that could be represented with it:
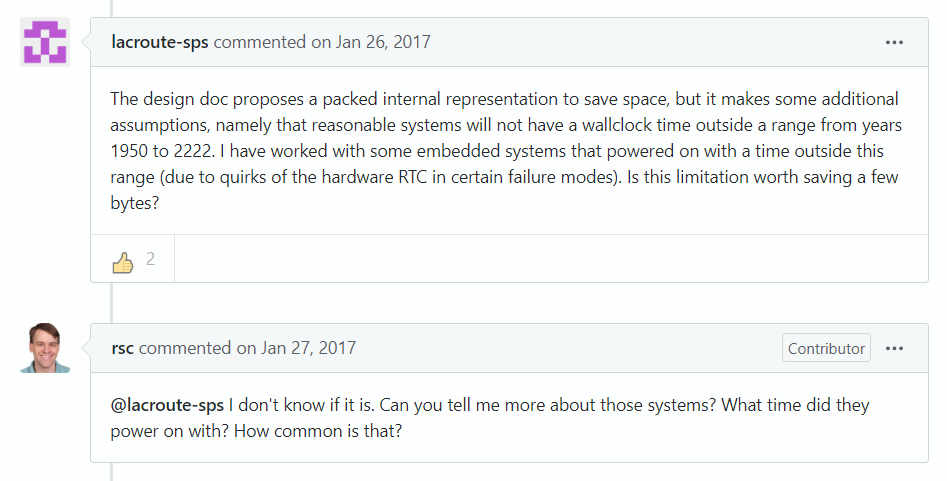
This issue was raised early on in the design process:
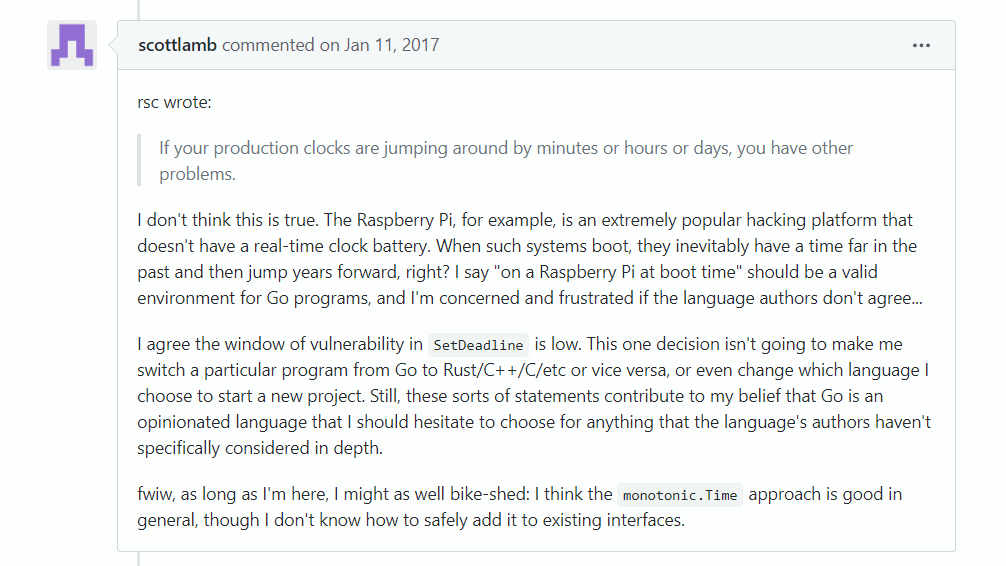
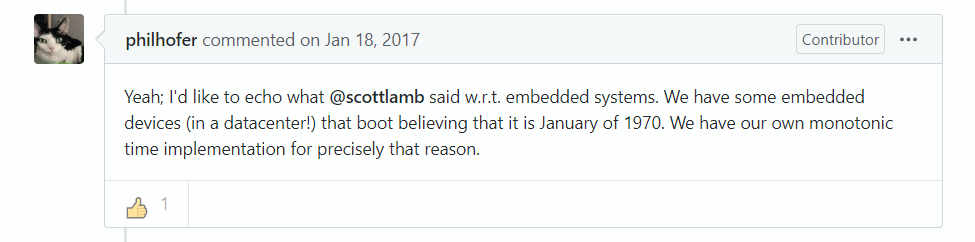
You can check out the complete thread for a full history.
Parting words
This is just one issue. But there are many like it - this one is as good an example as any.
Over and over, Go is a victim of its own mantra - "simplicity".
It constantly takes power away from its users, reserving it for itself.
It constantly lies about how complicated real-world systems are, and optimize for the 90% case, ignoring correctness.
It is a minefield of subtle gotchas that have very real implications - everything looks simple on the surface, but nothing is.
The Channel Axioms are a good example. There is nothing explicit about them. They are invented truths, that were convenient to implement, and who everyone must now work around.
Here's a fun gotcha I haven't mentioned yet:
// IdleTimingConn is a net.Conn that wraps another net.Conn and that times out
// if idle for more than idleTimeout.
type IdleTimingConn struct {
// Keep 64-bit words at the top to make sure 64-bit alignment, see
// https://golang.org/pkg/sync/atomic/#pkg-note-BUG
lastActivityTime uint64
// (cut)
}
The documentation reads:
BUGS
On ARM, x86-32, and 32-bit MIPS, it is the caller's responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
If the condition isn't satisfied, it panics at run-time. Only on 32-bit platforms. I didn't have to go far to hit this one - I got bit by this bug multiple times in the last few years.
It's a footnote. Not a compile-time check. There's an in-progress lint, for very simple cases, because Go's simplicity made it extremely hard to check for.
This fake "simplicity" runs deep in the Go ecosystem. Rust has the opposite problem - things look scary at first, but it's for a good reason. The problems tackled have inherent complexity, and it takes some effort to model them appropriately.
At this point in time, I deeply regret investing in Go.
Go is a Bell Labs fantasy, and not a very good one at that.
April 2022 Update
I wrote this in 2020, and have changed jobs twice since. Both jobs involved Go in some capacity, where it's supposed to shine (web services). It has not been a pleasant experience either - I've lost count of the amount of incidents directly caused by poor error handling, or Go default values.
If folks walk away with only one new thought from this, please let it be that: defaults matter. Go lets you whip something up quickly, but making the result "production-ready" is left as an exercise to the writer. Big companies that have adopted it have developed tons of tooling around it, use all available linters, do code generation, check the disassembly, and regularly pay the engineering cost of just using Go at all.
That's not how most Go code is written though. I'm interested not in what the language lets you do, but what is typical for a language - what is idiomatic, what "everyone ends up doing", because it is encouraged.
Because that's the kind of code I inevitably end up being on-call for, and I'm tired of being woken up due to the same classes of preventable errors, all the time. It doesn't matter that I don't personally write Go anymore: it's inescapable. If it's not internal Go code, it's in a SAAS we pay for: and no matter who writes it, it fails in all the same predictable ways.
Generics will not solve this. It is neat that they found a way to sneak them into the language, but it's not gonna change years of poor design decisions, and it's definitely not gonna change the enormous amount of existing Go code out there, especially as the discourse around them not being the usability+performance win everyone thought they would be keeps unfolding.
As I've mentioned recently on Twitter, what makes everything worse is that you cannot replace Go piecemeal once it has taken hold in a codebase: its FFI story is painful, the only good boundary with Go is a network boundary, and there's often a latency concern there.
Lastly: pointing out that I have been teaching Rust is a lazy and dismissive response to this. For me personally, I have found it to be the least awful option in a bunch of cases. I am yearning for even better languages, ones that tackle the same kind of issues but do it even better. I like to remind everyone that we're not out there cheering for sports team, just discussing our tools.
If you're looking to reduce the whole discourse to "X vs Y", let it be "serde vs crossing your fingers and hoping user input is well-formed". It is one of the better reductions of the problem: it really is "specifying behavior that should be allowed (and rejecting everything else)" vs "manually checking that everything is fine in a thousand tiny steps", which inevitably results in missed combinations because the human brain is not designed to hold graphs that big.
If you liked what you saw, please support my work!

