What's in a Linux executable?
This article is part of the Making our own executable packer series.
- But first, let me write assembly
Contents
Executables have been fascinating to me ever since I discovered, as a kid,
that they were just files. If you renamed a .exe to something else, you
could open it in notepad! And if you renamed something else to a .exe,
you'd get a neat error dialog.
Clearly, something was different about these files. Seen from notepad, they were mostly gibberish, but there had to be order in that chaos. 12-year-old me knew that, although he didn't quite know how or where to dig to make sense of it all.
So, this series is dedicated to my past self. In it we'll attempt to understand how Linux executables are organized, how they are executed, and how to make a program that takes an executable fresh off the linker and compresses it - just because we can.
Since the last big series, Making our own ping, was all about Windows, this one will be focused on 64-bit Linux.
But first, let me write assembly
Throughout the course of this series, we're definitely going to want to emit our own ELF files, but - just like we did when tackling Ethernet, IPv4 and ICMP, we're first going to get our hands on a well-formed, fully-working Linux executable, and then poke it with various sticks.
ELF stands for Executable and Linkable Format. It was first published in 1983, as part of SysV 4, and it's still in use on Linux today, although new sections have been added.
I had to go back to Reading files the hard way - Part 2 to get a quick refresher on nasm - the Netwide Assembler - so I wouldn't blame you if you had to, too.
In any case, here's the short version: here's some code to print "hi there" to the standard output, followed by a newline:
; in `hello.asm`
global _start
section .text
_start: mov rdi, 1 ; stdout fd
mov rsi, msg
mov rdx, 9 ; 8 chars + newline
mov rax, 1 ; write syscall
syscall
xor rdi, rdi ; return code 0
mov rax, 60 ; exit syscall
syscall
section .data
msg: db "hi there", 10
As a reminder, Filippo's Searchable Linux Syscall Table is quite excellent.
We can build and link it quite easily:
$ nasm -f elf64 hello.asm $ ld hello.o -o hello $ file hello hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped $ ./hello hi there
Good!
Now, our executable is about 8.68 KiB as-is. If we use gzip -9 on it, we
can easily get that down to 372 B, so I'm kinda curious to see what's in
there, to be quite honest.
This is a /genuine/ curious, not a "oh god why" curious.
This series is not about lamenting the good old days when everything used to fit on a floppy. It's not about how modern software is bloated and slow. It's not about to go into a tangent about developers being "lazy" and it "not being that hard if only someone tried".
We are not developing something practical here, we are picking a challenge purely for the sake of learning stuff.
If you need a chunky dose of nostalgia instead, feel free to check out gestures vaguely at almost all of the internet.
If we look at an hex dump of hello, we see the ELF string early on, followed
by a bunch of binary data:
$ xxd < hello | head 00000000: 7f45 4c46 0201 0100 0000 0000 0000 0000 .ELF............ 00000010: 0200 3e00 0100 0000 0010 4000 0000 0000 ..>.......@..... 00000020: 4000 0000 0000 0000 3821 0000 0000 0000 @.......8!...... 00000030: 0000 0000 4000 3800 0300 4000 0600 0500 ....@.8...@..... 00000040: 0100 0000 0400 0000 0000 0000 0000 0000 ................ 00000050: 0000 4000 0000 0000 0000 4000 0000 0000 ..@.......@..... 00000060: e800 0000 0000 0000 e800 0000 0000 0000 ................ 00000070: 0010 0000 0000 0000 0100 0000 0500 0000 ................ 00000080: 0010 0000 0000 0000 0010 4000 0000 0000 ..........@..... 00000090: 0010 4000 0000 0000 2500 0000 0000 0000 ..@.....%.......
But we can pretty easily see that most of the file is made out of null (zero) bytes:
$ xxd < hello | tail -60 | head 00001f00: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f10: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f20: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f30: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f40: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f50: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f60: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f70: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f80: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00001f90: 0000 0000 0000 0000 0000 0000 0000 0000 ................
We can also find a section that contains a bunch of names, maybe they have some sort of meaning?
$ xxd < hello | tail -32 | head 000020c0: 0920 4000 0000 0000 0000 0000 0000 0000 . @............. 000020d0: 2b00 0000 1000 0200 1020 4000 0000 0000 +........ @..... 000020e0: 0000 0000 0000 0000 0068 656c 6c6f 2d6f .........hello-o 000020f0: 7269 6769 6e61 6c2e 6173 6d00 6d73 6700 riginal.asm.msg. 00002100: 5f5f 6273 735f 7374 6172 7400 5f65 6461 __bss_start._eda 00002110: 7461 005f 656e 6400 002e 7379 6d74 6162 ta._end...symtab 00002120: 002e 7374 7274 6162 002e 7368 7374 7274 ..strtab..shstrt 00002130: 6162 002e 7465 7874 002e 6461 7461 0000 ab..text..data.. 00002140: 0000 0000 0000 0000 0000 0000 0000 0000 ................ 00002150: 0000 0000 0000 0000 0000 0000 0000 0000 ................
Now, there's a whole host of tools that would let us poke this ELF file from the comfort of a terminal. Ohh yes. A slew of them. Tools and tools as far as the eye can see. But we shan't be using them today. Not today, matey.
Today, we parse things ourselves. Using the nom crate, which we used in the
Making our own ping series, and armed with
which I would be willing to parse darn near anything - even PSD.
For that, though, we'll need a few pointers. The Wikipedia page for ELF is not half bad, but it's not the greatest overview - in part because it bothers itself with 32-bit ELF, which we will, for the entire length of this series, conveniently forget.
In other words, we're going to "pull a Canonical".
So, here's what a 64-bit ELF file header looks like:

I realize that's a lot to take in - a lot of this doesn't make sense yet!
Before we start writing any code, let's do some basic exploration by hand. According
to that diagram, at offset 62 in the file, there's an "index of entry with section names".
For our hello executable, that's...
$ # -s = seek, -l = length $ xxd -s 62 -l 2 ./hello 0000003e: 0500 ..
The bytes 05 and 00 - now, we're dealing with a little-endian file, so that means 0x0005,
which is just 5. So the fifth section header in the table contains section names.
At this point we have no idea what sections are, but I think it's safe to say that the file is divided into them and that their beginning and size is stored in those section headers.
The section header table starts at...
$ # -g = group size, -e = little-endian $ xxd -s 40 -l 8 -g 8 -e ./hello 00000028: 0000000000002140
0x2140, which is...
$ echo $((0x2140)) 8512
Even though xxd itself doesn't support hexadecimal notation, we can
perform shell arithmetic with $((expr))!
According to the Wikipedia page on ELF, every section header contains the offset in the file where the section data is stored... at offset 0x18!
Every section header has length 0x40, and we want the fifth one, so...
$ xxd -s $((0x2140 + 0x40 * 5 + 0x18)) -l 8 -g 8 -e ./hello 00002298: 0000000000002118 .!......
That means that the data of the section that contains section names should be at 0x2118. Let's check it out:
$ xxd -s $((0x2118)) ./hello | head -4 00002118: 002e 7379 6d74 6162 002e 7374 7274 6162 ..symtab..strtab 00002128: 002e 7368 7374 7274 6162 002e 7465 7874 ..shstrtab..text 00002138: 002e 6461 7461 0000 0000 0000 0000 0000 ..data.......... 00002148: 0000 0000 0000 0000 0000 0000 0000 0000 ................
...those are the strings we noticed earlier, when randomly paging through the dump!
Well, that's one mystery solved. Onto the next hundred or so.
It was fun looking through the file by hand, and we learned to use xxd to
do exactly that (which might definitely come in handy in the nuclear winter
if a graphical hex viewer/editor isn't available), but we probably want
to start writing an actual parser now.
We'll name our library delf, for demystify ELF
$ cargo new --lib delf
$ cd delf/
$ cargo add nom@5
Adding nom v5.1.2 to dependencies
For convenience, we'll add a parse module with an Input and Result type:
// in `delf/src/lib.rs` mod parse;
// in `delf/src/parse.rs` pub type Input<'a> = &'a [u8]; pub type Result<'a, O> = nom::IResult<Input<'a>, O, nom::error::VerboseError<Input<'a>>>;
We can parse the first 16 bytes pretty trivially:

Like I said earlier, we're not going to bother with big-endian ELFs, or 32-bit ELFs, so we can hardcode a few values. Let's get started!
// in `delf/src/lib.rs`
#[derive(Debug)]
pub struct File {
// we'll add fields as we go
}
impl File {
const MAGIC: &'static [u8] = &[0x7f, 0x45, 0x4c, 0x46];
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{
bytes::complete::{tag, take},
error::context,
sequence::tuple,
};
let (i, _) = tuple((
// -------
context("Magic", tag(Self::MAGIC)),
context("Class", tag(&[0x2])),
context("Endianness", tag(&[0x1])),
context("Version", tag(&[0x1])),
context("OS ABI", nom::branch::alt((tag(&[0x0]), tag(&[0x3])))),
// -------
context("Padding", take(8_usize)),
))(i)?;
Ok((i, Self {}))
}
}
That looks reasonable. Let's make another crate to test the delf crate.
We'll name it "elk", for "Executable & Linker Kit"
$ cargo new --bin elk
$ cd elk/
$ cargo add --path ../delf
Adding delf (unknown version) to dependencies
// in `elk/src/main.rs`
use std::{env, error::Error, fs};
fn main() -> Result<(), Box<dyn Error>> {
let input_path = env::args().nth(1).expect("usage: elk FILE");
let input = fs::read(&input_path)?;
delf::File::parse(&input[..]).map_err(|e| format!("{:?}", e))?;
println!("input is a supported ELF file!");
Ok(())
}
And take it for a spin:
$ # in elk/ $ cargo build -q $ ./target/debug/elk /bin/true input is a supported ELF file!
Good! Good start.
Now we'll have to deal with some enums

Let's start with the type - declaring an enum in Rust is simple enough.
We'll want to derive some useful traits - Debug for printing, Clone and
Copy so it has copy semantics (instead of transmitting ownership),
PartialEq and Eq to compare Type values for equality.
// in `delf/src/lib.rs`
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub enum Type {
None,
Rel,
Exec,
Dyn,
Core,
}
When reading our ELF file though, we won't get a Type - we'll get a u16.
And similarly, when we write out an ELF file, we'll also need a u16.
We could do the mapping ourselves, like so:
// in `delf/src/lib.rs`
impl Type {
fn to_u16(&self) -> u16 {
match self {
Self::None => 0,
Self::Rel => 1,
Self::Exec => 2,
Self::Dyn => 3,
// etc.
}
}
}
Or we could just set the representation of the Type enum to u16 - and
then we'd get that for free:
// in `delf/src/lib.rs`
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
#[repr(u16)]
pub enum Type {
None = 0x0,
Rel = 0x1,
Exec = 0x2,
Dyn = 0x3,
Core = 0x4,
}
Now, we can use the as operator to cast our Type to u16 - let's
write a quick test to validate our assumptions:
// in `delf/src/lib.rs`
#[cfg(test)]
mod tests {
#[test]
fn type_to_u16() {
assert_eq!(super::Type::Dyn as u16, 0x3);
}
}
And run it:
$ # t == test, --lib == only library unit tests (not doc tests)
$ cargo t --lib
Finished test [unoptimized + debuginfo] target(s) in 0.02s
Running target/debug/deps/delf-d6fdd5529c793a0b
running 1 test
test tests::type_to_u16 ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Splendid! Now there's the small matter of going the other way - converting
an u16 to a Type. The problem here, of course, is that not all u16 values
are valid Type values.
In fact, had we written from_u16 ourselves, we would have had to deal
with this problem head-on:
// in `delf/src/lib.rs`
impl Type {
pub fn from_u16(x: u16) -> Self {
match x {
0 => Self::None,
1 => Self::Rel,
2 => Self::Exec,
3 => Self::Dyn,
4 => Self::Core,
}
}
}
The code above fails to compile, with reason:
# b = build, -q = quiet
$ cargo b -q
error[E0004]: non-exhaustive patterns: `5u16..=std::u16::MAX` not covered
--> src/lib.rs:17:15
|
17 | match x {
| ^ pattern `5u16..=std::u16::MAX` not covered
|
= help: ensure that all possible cases are being handled, possibly by adding wildcards or more match arms
To deal with that possibility, we could return an Option<Self> instead:
// in `delf/src/lib.rs`
impl Type {
pub fn from_u16(x: u16) -> Option<Self> {
match x {
0 => Some(Self::None),
1 => Some(Self::Rel),
2 => Some(Self::Exec),
3 => Some(Self::Dyn),
4 => Some(Self::Core),
_ => None,
}
}
}
#[cfg(test)]
mod tests {
// omitted: previous tests
#[test]
fn type_from_u16() {
assert_eq!(super::Type::from_u16(0x3), Some(super::Type::Dyn));
assert_eq!(super::Type::from_u16(0xf00d), None);
}
}
And that works!
$ cargo t --lib
Finished test [unoptimized + debuginfo] target(s) in 0.02s
Running target/debug/deps/delf-d6fdd5529c793a0b
running 2 tests
test tests::type_to_u16 ... ok
test tests::type_from_u16 ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
...but it's kinda tedious. We already specify a Type <-> u16 mapping, when we
first define the enum. Why should we repeat ourselves?
As it turns out.. eyes light up in wonder there is a crate for that!
derive-try-from-primitive solves exactly that problem. Let's give it a shot:
$ cd delf/
$ cargo add derive-try-from-primitive@1
Adding derive-try-from-primitive v1.0.0 to dependencies
// in `delf/src/lib.rs`
use derive_try_from_primitive::TryFromPrimitive;
#[derive(Debug, Clone, Copy, PartialEq, Eq, TryFromPrimitive)]
#[repr(u16)]
pub enum Type {
None = 0x0,
Rel = 0x1,
Exec = 0x2,
Dyn = 0x3,
Core = 0x4,
}
#[derive(Debug, Clone, Copy, PartialEq, Eq, TryFromPrimitive)]
#[repr(u16)]
pub enum Machine {
X86 = 0x03,
X86_64 = 0x3e,
}
#[cfg(test)]
mod tests {
use super::Machine;
use std::convert::TryFrom;
#[test]
fn try_enums() {
assert_eq!(Machine::X86_64 as u16, 0x3E);
assert_eq!(Machine::try_from(0x3E), Ok(Machine::X86_64));
assert_eq!(Machine::try_from(0xFA), Err(0xFA));
}
}
In a previous version of this article, we used derive-try-from-primitive v0.1.0,
which returned an Option<T>. But, since then, derive-try-from-primitive v1.0.0
was released, which returns a Result<T, E> since it implements the standard
TryFrom interface.
Sure enough, it works as expected!
$ cargo t
Finished test [unoptimized + debuginfo] target(s) in 0.01s
Running /home/amos/ftl/elf-series/target/debug/deps/delf-2d44b198a598eda8
running 1 test
test tests::try_enums ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Doc-tests delf
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
Now, we can finally parse both the type and the machine. First let's add
them to the File struct:
// in `delf/src/lib.rs`
#[derive(Debug)]
pub struct File {
pub type: Type,
pub machine: Machine,
}
But wait... isn't type a keyword?
$ cargo b -q error: expected identifier, found keyword `type` --> src/lib.rs:24:5 | 24 | type: Type, | ^^^^ expected identifier, found keyword | help: you can escape reserved keywords to use them as identifiers | 24 | r#type: Type, | ^^^^^^
It is! We could use typ instead - but just this once, let's use the
escaped form instead, like the compiler suggests.
#[derive(Debug)]
pub struct File {
pub r#type: Type,
pub machine: Machine,
}
Better! Kinda awkward, but at least this compiles.
Let's parse:
// in `delf/src/lib.rs`
// new!
use std::convert::TryFrom;
impl File {
// omitted: magic constant
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{
bytes::complete::{tag, take},
error::context,
sequence::tuple,
combinator::map,
number::complete::le_u16,
};
// omitted: parse magic, etc.
let (i, (r#type, machine)) = tuple((
context("Type", map(le_u16, |x| Type::try_from(x).unwrap())),
context("Machine", map(le_u16, |x| Machine::try_from(x).unwrap())),
))(i)?;
let res = Self { machine, r#type };
Ok((i, res))
}
}
To try that, we'll switch back to our binary crate, elk, for a second,
and print the File struct, now that it has fields!
// in `elk/src/main.rs`
fn main() -> Result<(), Box<dyn Error>> {
let input_path = env::args().nth(1).expect("usage: elk FILE");
let input = fs::read(&input_path)?;
let (_, file) = delf::File::parse(&input[..]).map_err(|e| format!("{:?}", e))?;
// new!
println!("{:#?}", file);
Ok(())
}
$ # in elk/
$ cargo b -q
$ ./target/debug/elk /bin/true
File {
type: Dyn,
machine: X86_64,
}
Wonderful! What happens if we run it on a 32-bit ELF?
$ ./target/debug/elk /usr/lib32/libc.so
Error: "Error(VerboseError { errors: [([47, 42, 32, 71, 78, 85, 32, 108, 100, 32, 115, 99, 114, 105, 112, 116, 10, 32, 32, 32, 85, 115, 101, 32, 116, 104, 101, 32, 115, 104, 97, 114, 101, 100, 32, 108, 105, 98, 114, 97, 114, 121, 44, 32, 98, 117, 116, 32, 115, 111, 109, 101, 32, 102, 117, 110, 99, 116, 105, 111, 110, 115, 32, 97, 114, 101, 32, 111, 110, 108, 121, 32, 105, 110, 10, 32, 32, 32, 116, 104, 101, 32, 115, 116, 97, 116, 105, 99, 32, 108, 105, 98, 114, 97, 114, 121, 44, 32, 115, 111, 32, 116, 114, 121, 32, 116, 104, 97, 116, 32, 115, 101, 99, 111, 110, 100, 97, 114, 105, 108, 121, 46, 32, 32, 42, 47, 10, 79, 85, 84, 80, 85, 84, 95, 70, 79, 82, 77, 65, 84, 40, 101, 108, 102, 51, 50, 45, 105, 51, 56, 54, 41, 10, 71, 82, 79, 85, 80, 32, 40, 32, 47, 117, 115, 114, 47, 108, 105, 98, 51, 50, 47, 108, 105, 98, 99, 46, 115, 111, 46, 54, 32, 47, 117, 115, 114, 47, 108, 105, 98, 51, 50, 47, 108, 105, 98, 99, 95, 110, 111, 110, 115, 104, 97, 114, 101, 100, 46, 97, 32, 32, 65, 83, 95, 78, 69, 69, 68, 69, 68, 32, 40, 32, 47, 117, 115, 114, 47, 108, 105, 98, 51, 50, 47, 108, 100, 45, 108, 105, 110, 117, 120, 46, 115, 111, 46, 50, 32, 41, 32, 41, 10], Nom(Tag)), ([47, 42, 32, 71, 78, 85, 32, 108, 100, 32, 115, 99, 114, 105, 112, 116, 10, 32, 32, 32, 85, 115, 101, 32, 116, 104, 101, 32, 115, 104, 97, 114, 101, 100, 32, 108, 105, 98, 114, 97, 114, 121, 44, 32, 98, 117, 116, 32, 115, 111, 109, 101, 32, 102, 117, 110, 99, 116, 105, 111, 110, 115, 32, 97, 114, 101, 32, 111, 110, 108, 121, 32, 105, 110, 10, 32, 32, 32, 116, 104, 101, 32, 115, 116, 97, 116, 105, 99, 32, 108, 105, 98, 114, 97, 114, 121, 44, 32, 115, 111, 32, 116, 114, 121, 32, 116, 104, 97, 116, 32, 115, 101, 99, 111, 110, 100, 97, 114, 105, 108, 121, 46, 32, 32, 42, 47, 10, 79, 85, 84, 80, 85, 84, 95, 70, 79, 82, 77, 65, 84, 40, 101, 108, 102, 51, 50, 45, 105, 51, 56, 54, 41, 10, 71, 82, 79, 85, 80, 32, 40, 32, 47, 117, 115, 114, 47, 108, 105, 98, 51, 50, 47, 108, 105, 98, 99, 46, 115, 111, 46, 54, 32, 47, 117, 115, 114, 47, 108, 105, 98, 51, 50, 47, 108, 105, 98, 99, 95, 110, 111, 110, 115, 104, 97, 114, 101, 100, 46, 97, 32, 32, 65, 83, 95, 78, 69, 69, 68, 69, 68, 32, 40, 32, 47, 117, 115, 114, 47, 108, 105, 98, 51, 50, 47, 108, 100, 45, 108, 105, 110, 117, 120, 46, 115, 111, 46, 50, 32, 41, 32, 41, 10], Context(\"Magic\"))] })"
Oh my.
That's too much output. And we'd rather see hexadecimal notation here, wouldn't we?
Let's make a quick helper:
// in `delf/src/lib.rs`
pub struct HexDump<'a>(&'a [u8]);
use std::fmt;
impl<'a> fmt::Debug for HexDump<'a> {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
for &x in self.0.iter().take(20) {
write!(f, "{:02x} ", x)?;
}
Ok(())
}
}
And try it. Remember there are two failure modes in nom:
nom::Err::Erroris recoverable. Maybe another branch will work (if we're trying several parsers in a row), or maybe we just need to get more input.nom::Err::Failureis unrecoverable - we've tried all the parsers, more input won't help, something is just plain wrong.
In either case, they just wrap a nom::error::VerboseError, which itself
can contain multiple nom::error::ErrorKind, along with the relevant input slice.
I know, I know - that's a lot! But thanks to pattern matching, it's not so bad.
We can make a much better error printer in just a few lines. We'll add it
directly in delf, so that we don't have use nom types in elk:
// in `delf/src/lib.rs`
impl File {
pub fn parse_or_print_error(i: parse::Input) -> Option<Self> {
match Self::parse(i) {
Ok((_, file)) => Some(file),
Err(nom::Err::Failure(err)) | Err(nom::Err::Error(err)) => {
eprintln!("Parsing failed:");
for (input, err) in err.errors {
eprintln!("{:?} at:", err);
eprintln!("{:?}", HexDump(input));
}
None
}
Err(_) => panic!("unexpected nom error"),
}
}
}
Now we can use it from elk:
// in `elk/src/main.rs`
fn main() -> Result<(), Box<dyn Error>> {
// omitted: grabbing first argument
let file = match delf::File::parse_or_print_error(&input[..]) {
Some(f) => f,
None => std::process::exit(1),
};
println!("{:#?}", file);
}
$ cargo b -q
$ ./target/debug/elk /usr/lib32/libc.so
Parsing failed:
Nom(Tag) at:
2f 2a 20 47 4e 55 20 6c 64 20 73 63 72 69 70 74 0a 20 20 20
Context("Magic") at:
2f 2a 20 47 4e 55 20 6c 64 20 73 63 72 69 70 74 0a 20 20 20
Wonderful! Well. It could be improved a lot - for now we'll just add the position of each error in the file, as a byte offset:
// in `delf/src/lib.rs`
impl File {
pub fn parse_or_print_error(i: parse::Input) -> Option<Self> {
match Self::parse(i) {
Ok((_, file)) => Some(file),
Err(nom::Err::Failure(err)) | Err(nom::Err::Error(err)) => {
eprintln!("Parsing failed:");
for (input, err) in err.errors {
// new!
use nom::Offset;
let offset = i.offset(input);
eprintln!("{:?} at position {}:", err, offset);
eprintln!("{:>08x}: {:?}", offset, HexDump(input));
}
None
}
Err(_) => panic!("unexpected nom error"),
}
}
And here's the result:
$ cargo b -q && ./target/debug/elk /usr/lib32/libz.so
Parsing failed:
Nom(Tag) at position 4:
00000004: 01 01 01 00 00 00 00 00 00 00 00 00 03 00 03 00 01 00 00 00
Context("Class") at position 4:
00000004: 01 01 01 00 00 00 00 00 00 00 00 00 03 00 03 00 01 00 00 00
We could get much, much nicer output, but let's not get distracted - there is so much to do!
If you want to read more about error handling (and pretty printing!) with
nom, read Making our own ping: Part 9.
Let's not waste any more time and move forward with our parser. One thing
I don't like about our current parser is that it panics if it encounters
say, a value for Machine it doesn't support.
We're going to allow ourselves to panic in elk - the binary crate, our CLI
tool, but we'll avoid panicking in delf - the library crate. Luckily, we've
already learned how to do that.
In our case, we want to implement parse on the Machine type. It should
return a parse::Result - like any other parser, and if we find a variant
we don't support, we shall return one of the built-in nom error kinds, say...
Alt. Because what are enums, if not a miserable little pile of alternatives?
// in `delf/src/lib.rs`
impl Machine {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
let original_i = i;
use nom::{
error::{ErrorKind, ParseError, VerboseError},
number::complete::le_u16,
Err,
};
let (i, x) = le_u16(i)?;
match Self::try_from(x) {
Some(res) => Ok((i, res)),
None => Err(Err::Failure(VerboseError::from_error_kind(
original_i,
ErrorKind::Alt,
))),
}
}
}
Okay. So.
That's a little bit on the verbose side. Also, there's no context! We won't know which enum failed to parse. I'm sure we can do a bit better than that.
We've used the map combinator before, but it won't work here - map works when
all outputs of the previous parser are valid, whereas in our case, try_from can fail.
Luckily, there's another combinator, map_res, that fits our needs. It allows
us to return a Result<O2, E2> instead - where O2 is the output of our mapping
function, and E2 is the errors our mapping function can return.
// in `delf/src/lib.rs`
impl Machine {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{combinator::map_res, error::ErrorKind, number::complete::le_u16};
map_res(le_u16, |x| match Self::try_from(x) {
Ok(x) => Ok(x),
Err(_) => Err(ErrorKind::Alt),
})(i)
}
}
Better! Now nom takes care of making a "verbose error", and picks an Err
variant for us. It even annotates with the location, since map_res has a
reference to the input before le_u16 even runs.
But our code isn't ideal right now - try_from returns a Result<T, E>, and
we're using pattern matching to turn it into another Result<T, E>. And as
much as I like pattern matching, there's a better tool for the job: map_err.
Let's look at its prototype (keep in mind it's implemented on Result<T, E>):
// rust standard library
pub fn map_err<F, O>(self, op: O) -> Result<T, F> where
O: FnOnce(E) -> F
So, if the Result is a the Err variant, map_err will call the function we
provide, op, to change it to another error type - from E to F.
This means we can just write:
// in `delf/src/lib.rs`
impl Machine {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{combinator::map_res, error::ErrorKind, number::complete::le_u16};
map_res(le_u16, |x| Self::try_from(x).map_err(|_| ErrorKind::Alt))(i)
}
}
We can even add some context now. It's all just combinators!
impl Machine {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{
combinator::map_res,
error::{context, ErrorKind},
number::complete::le_u16,
};
context(
"Machine",
map_res(le_u16, |x| Self::try_from(x).map_err(|_| ErrorKind::Alt)),
)(i)
}
}
And even though this implementation is much more pleasant, I wouldn't want it to write it by hand more than once, so.. let's make a macro!
We'll slap it in the parse module:
// in `delf/src/parse.rs`
// omitted: definitions for `Input` and `Result`
#[macro_export]
macro_rules! impl_parse_for_enum {
($type: ident, $number_parser: ident) => {
impl $type {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{
combinator::map_res,
error::{context, ErrorKind},
number::complete::$number_parser,
};
let parser = map_res($number_parser, |x| {
Self::try_from(x).map_err(|_| ErrorKind::Alt)
});
context(stringify!($type), parser)(i)
}
}
};
}
And now we can implement parse for both Type and Machine:
// in `delf/src/lib.rs` // omitted: struct definitions for `Type` and `Machine` impl_parse_for_enum!(Type, le_u16); impl_parse_for_enum!(Machine, le_u16);
And finally use those in our main parser:
impl File {
const MAGIC: &'static [u8] = &[0x7f, 0x45, 0x4c, 0x46];
pub fn parse(i: parse::Input) -> parse::Result<Self> {
// note: you can remove `map` and `le_u16` imports
// omitted: rest of parser
// before:
let (i, (r#type, machine)) = tuple((
context("Type", map(le_u16, |x| Type::try_from(x).unwrap())),
context("Machine", map(le_u16, |x| Machine::try_from(x).unwrap())),
))(i)?;
// after:
let (i, (r#type, machine)) = tuple((Type::parse, Machine::parse))(i)?;
let res = Self { machine, r#type };
Ok((i, res))
}
}
Phew. I feel lighter already. Nothing like a good abstraction to clear the mind.
Does everything still work?
$ cargo b -q && ./target/debug/elk /bin/true
File {
type: Dyn,
machine: X86_64,
}
It does! Good, good.
I guess it's time to parse the rest of the ELF header.
Next up is the entry point - in ELF64, it's.. a 64-bit integer. Well, it's
more of a memory address. We'll want to print that in hexadecimal. So let's make
a wrapper type!
We might end up doing some arithmetic with those addresses, so we'll quickly
grab a crate to derive more traits: derive_more:
$ cd delf/
$ cargo add derive_more@0.99
Adding derive_more v0.99.9 to dependencies
// in `delf/src/lib.rs`
use derive_more::*;
// "Add" and "Sub" are in `derive_more`
#[derive(Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Add, Sub)]
pub struct Addr(pub u64);
impl fmt::Debug for Addr {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "{:08x}", self.0)
}
}
impl fmt::Display for Addr {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
fmt::Debug::fmt(self, f)
}
}
// This will come in handy when serializing
impl Into<u64> for Addr {
fn into(self) -> u64 {
self.0
}
}
// This will come in handy when indexing / sub-slicing slices
impl Into<usize> for Addr {
fn into(self) -> usize {
self.0 as usize
}
}
// This will come in handy when parsing
impl From<u64> for Addr {
fn from(x: u64) -> Self {
Self(x)
}
}
impl Addr {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
use nom::{combinator::map, number::complete::le_u64};
map(le_u64, From::from)(i)
}
}
Well, that was a mouthful. But it should be smooth sailing from now on!
We can add it to our File struct, and our parser:
// in `delf/src/lib.rs`
#[derive(Debug)]
pub struct File {
pub r#type: Type,
pub machine: Machine,
// new!
pub entry_point: Addr,
}
impl File {
pub fn parse(i: parse::Input) -> parse::Result<Self> {
// omitted: most of parser
use nom::{combinator::verify, number::complete::le_u32};
let (i, (r#type, machine)) = tuple((Type::parse, Machine::parse))(i)?;
// this 32-bit integer should always be set to 1 in the current
// version of ELF, see the diagram. We don't *have* to check it,
// but it's so easy to, let's anyway!
let (i, _) = context("Version (bis)", verify(le_u32, |&x| x == 1))(i)?;
let (i, entry_point) = Addr::parse(i)?;
let res = Self {
machine,
r#type,
entry_point,
};
Ok((i, res))
}
}
And then give elk a go! We don't need to change anything in it -
it refers to delf by path, and we've updated delf's File to have a
new field, so we just need to build and run it again:
$ cargo b -q && ./target/debug/elk /bin/true
File {
type: Dyn,
machine: X86_64,
entry_point: 00002130,
}
Nice! But what does entry_point mean anyway?
Our diagram said it's the "address at which program execution starts".
For example, if we run it on our sample assembly program from above:
$ cargo b -q && ./target/debug/elk samples/hello
File {
type: Exec,
machine: X86_64,
entry_point: 00401000,
}
How can we verify our assumption? Well, we can debug our program!
When researching this article series, I went hunting for a good GDB GUI - and I'm sorry to report that the state of GDB graphical user interfaces is... not great. I mean, Nemiver still runs, but I didn't have to look very far to find several annoying bugs.
So, naturally, I went hunting on https://crates.io, and found... ugdb! It's a TUI (text user interface), but it's nicer than the built-in GDB TUI, has syntax highlighting, a cozy default pane layout. I like it a lot!
To install it, simply run:
$ # note: you'll need cmake. use --force if updating $ cargo install ugdb
We can then load up samples/hello in ugdb simply with:
$ ugdb ./samples/hello
And be greeted with this:
Now, if we just use the start GDB command, our program will run entirely,
and we'll see its output in the right pane:
(gdb) start
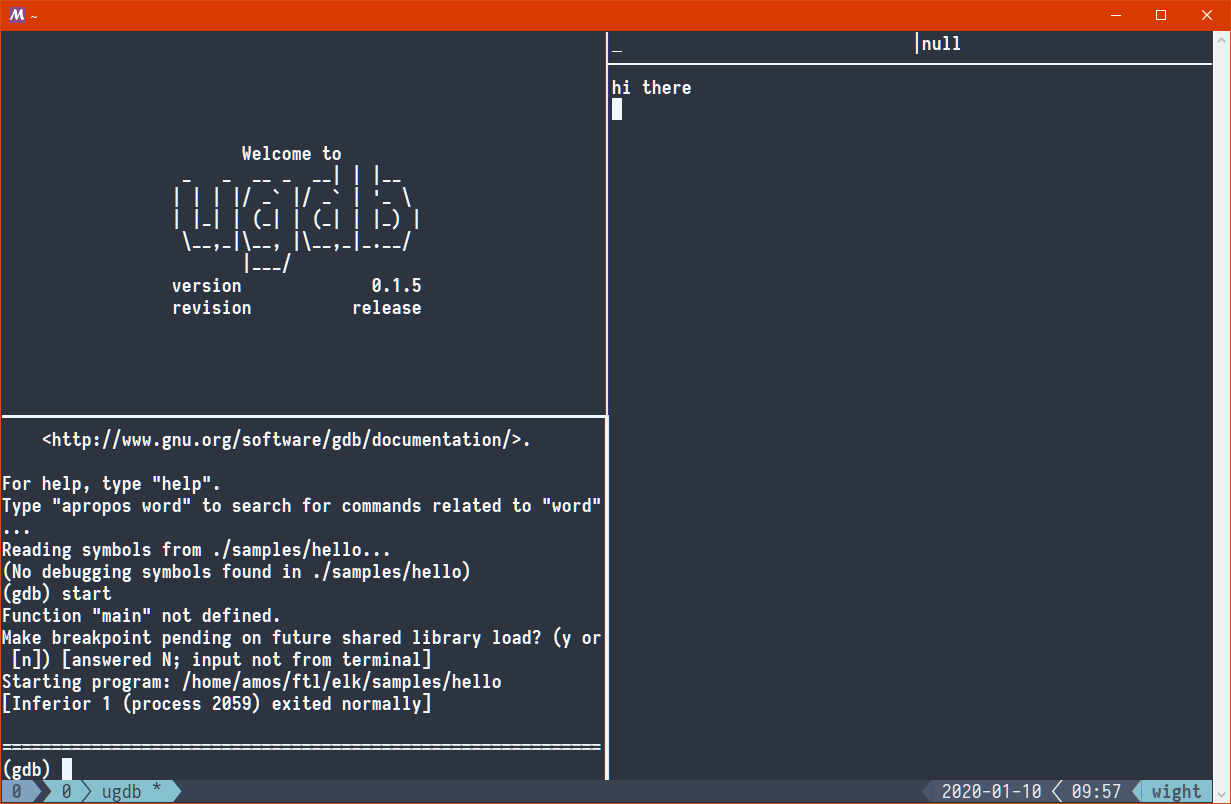
But that's not very interesting. GDB will not break anywhere in our program by
default, because our program doesn't crash - it just makes two syscalls:
write and exit.
To quit GDB (and similarly, ugdb), use the quit command (or q, for short). If it asks
for a confirmation, reply with y (and press enter).
We can't set breakpoint on syscalls... but we can set catchpoints!
(gdb) catch syscall Catchpoint 1 (any syscall) (gdb) start
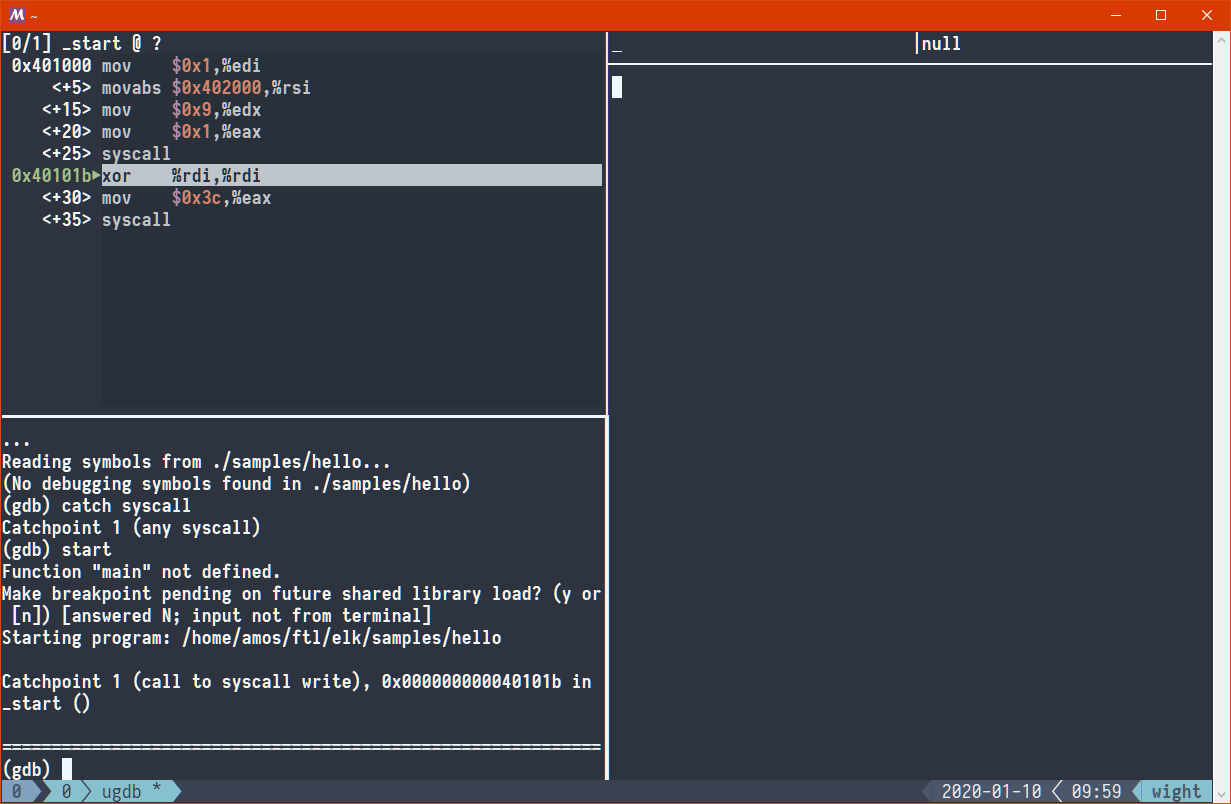
Nice! GDB paused program execution right before the write syscall was executed.
We can already see in this screenshot that the beginning of _start - our entry point -
is at 0x401000. Everything checks out so far!
Another way we could've checked this is to set a breakpoint at address 0x401000,
like so:
(gdb) break *0x401000 Breakpoint 1 at 0x401000 (gdb) start
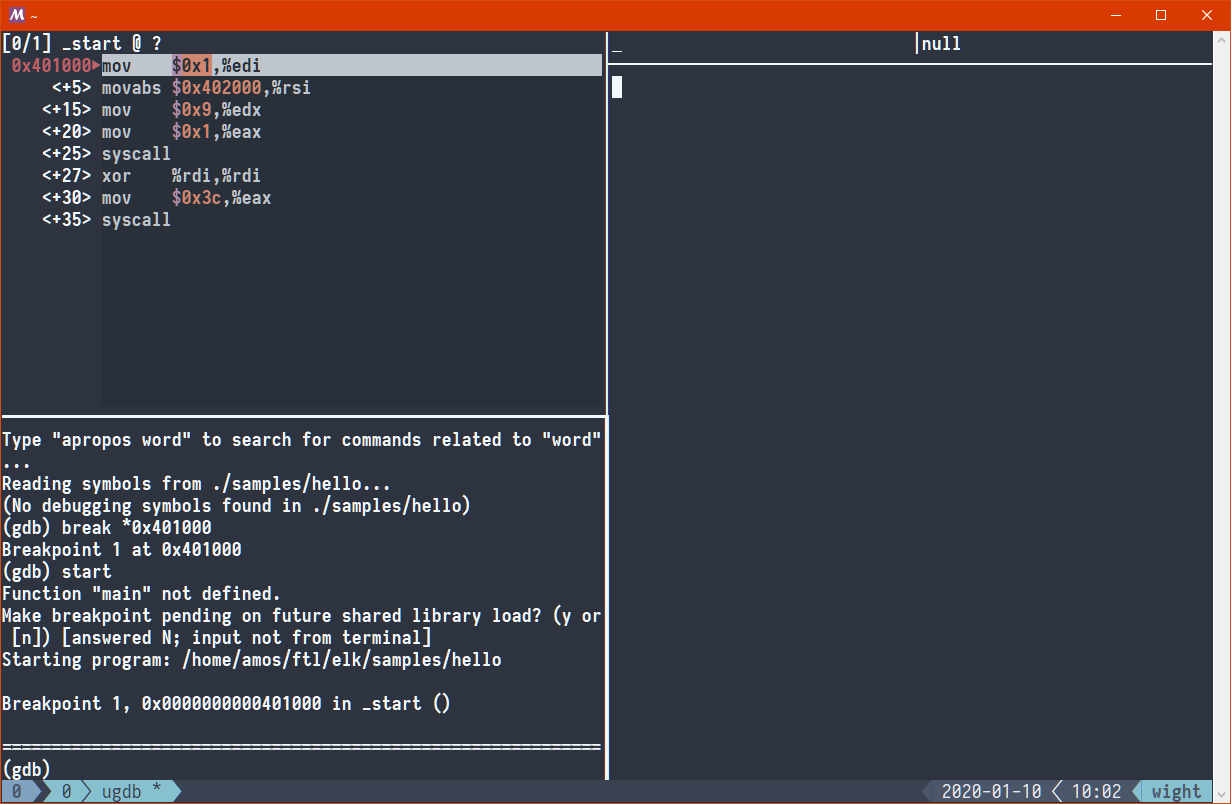
While in ugdb, we can use the stepi command (or si for short) to advance to
the next instruction.
Here's a quick video:
There's one thing that bothers me though - the disassembly shown in ugdb doesn't
really look like our source program. We wrote mov rdi, 1, not mov $0x1, %edi.
The explanation is simple: GDB is showing us AT&T assembly syntax, whereas we got
used to Intel syntax. Luckily, we can adjust that by creating a ~/.gdbinit file:
# in ~/.gdbinit set disassembly-flavor intel
Now GDB (and ugdb) shows us disassembly in Intel syntax!
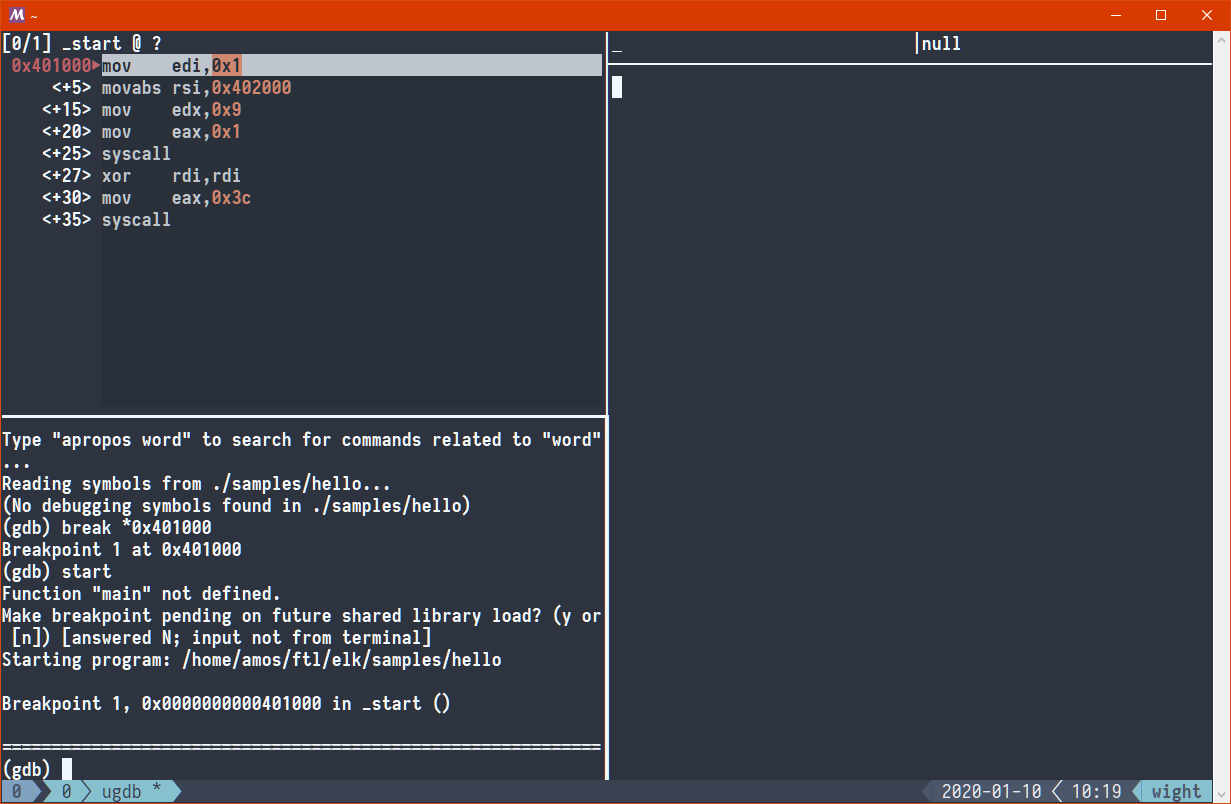
Let's try doing all that on /bin/true - the entry point for it was 0x2130, so,
(gdb) break *0x2130 (gdb) start Starting program: /usr/bin/true Warning: Cannot insert breakpoint 1. Cannot access memory at address 0x2130
Oh. That's unfortunate. What address does /bin/true start at, then?
And how can we break at the entry point, if it's not 0x2130?
Recent versions of gdb come with the starti command, which does exactly that.
We can use it to inspect at which address /bin/true actually starts:
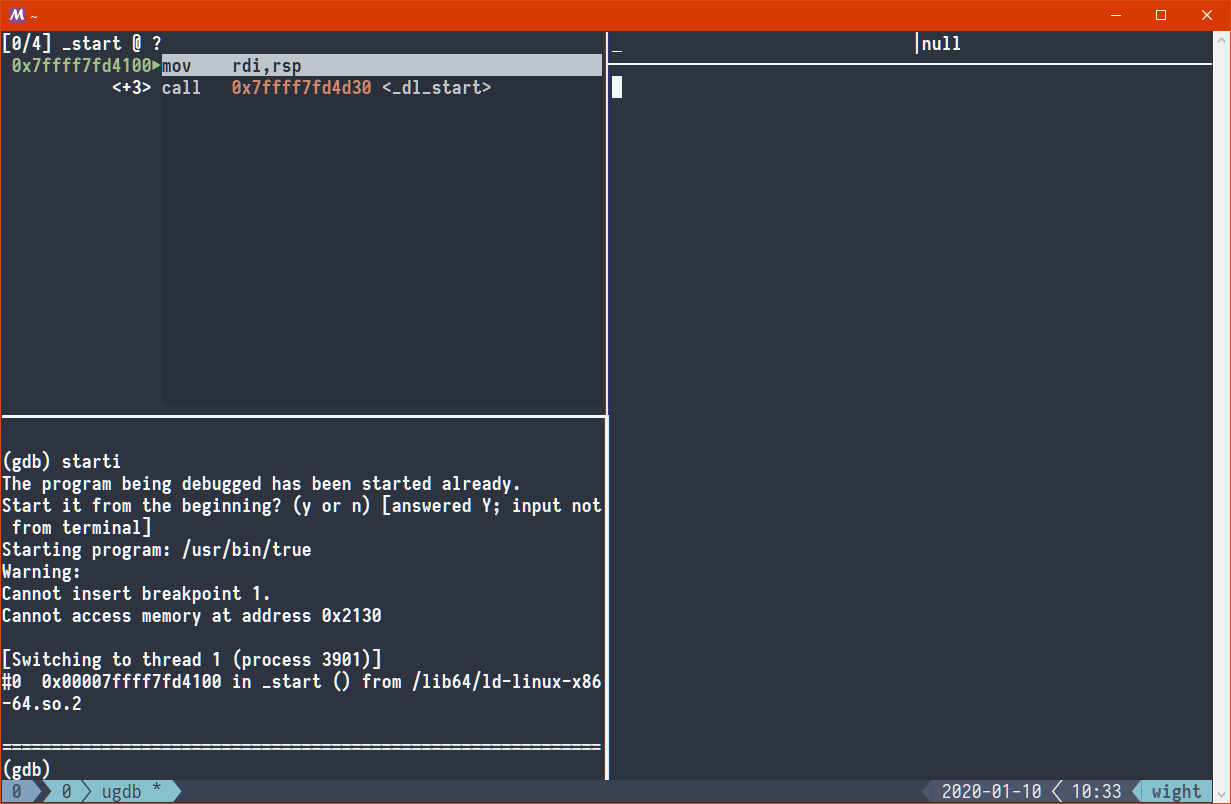
Oh. 0x7ffff7fd4100. Okay. Well, that's 140 terabytes. I sorta doubt /bin/true
needs that much memory to proceed, but uh...
Okay, forget /bin/true for a minute - let's make a C program that prints
the address of main. That should be the entry point, right?
// in `elk/samples/entry_point.c`
#include <stdio.h>
int main() {
printf("main is at %p\n", &main);
}
$ # in `elk/samples/`
$ gcc entry_point.c -o entry_point
$ ../target/debug/elk
File {
type: Dyn,
machine: X86_64,
entry_point: 00001040,
}
$ ./entry_point
main is at 0x562601e0f139
$ ./entry_point
main is at 0x56311bd0c139
$ ./entry_point
main is at 0x5588a0a39139
$ ./entry_point
main is at 0x559c3e3df139
$ ./entry_point
main is at 0x557578dc4139
$ ./entry_point
main is at 0x55c80e189139
Okay.
Uh.
Let's try gdb?
(gdb) starti Starting program /home/amos/ftl/elk/samples/entry_point Program stopped. 0x0000000000401ac0 in _start () (gdb) c Continuing. main is at 0x401be5 [Inferior 1 (process 7394) exited normally] (gdb) starti Starting program: /home/amos/ftl/elk/samples/entry_point Program stopped. 0x0000000000401ac0 in _start () (gdb) c Continuing. main is at 0x401be5 [Inferior 1 (process 7397) exited normally] (gdb) starti Starting program: /home/amos/ftl/elk/samples/entry_point Program stopped. 0x0000000000401ac0 in _start () (gdb) c Continuing. main is at 0x401be5 [Inferior 1 (process 7398) exited normally]
Well.
That doesn't answer any of my questions.
If anything, I have more questions now.
- Why is the entry point stored in an ELF file sometimes the same one we see in GDB and sometimes not?
- Why is the entry point a valid offset into the ELF file and sometimes not?
- Why is the entry point always the same in GDB but not when running the executable directly?
Clearly, we have a lot more detective work to do...
The ELF binary file format is old, but still in use today! It contains
information about the Operating System's Application Binary Interface (OS
ABI) and the processor architecture (ie. the Machine), among other things.
It is easily parsed with nom. For Rust
enums, we can use the
derive-try-from-primitive
crate to convert back and forth between the integer representation (u8, u16, u32) and the Rust enum variant.
The ELF header also contains the "entry point" for a program - where it should start executing. Although, when we run a program, we sometimes find a different address being executed.
We can use xxd to visualize the contents of a binary file - it's a
"hexdump" (hexadecimal.. printer) tool. It accepts options such as: offset,
length, endianness, and how many bytes to group together when printing. It does
not understand hexadecimal offsets, but we can use shell arithmetic - $(()) -
to do that.
GDB, the GNU debugger, will let us start a program and step through it, even if doesn't have debug or source information - in that case, it will show us disassembly of the program. We can even ask GDB to use Intel syntax when showing assembly. ugdb is a nice text UI frontend to GDB.
This article is part 1 of the Making our own executable packer series.
If you liked what you saw, please support my work!

