Working with strings in Rust
- Clear, simple, and wrong
- A very quick UTF-8 primer
- Back to C
- Now for some Rust
- Error handling
- Iteration
- Passing strings around
- uppercase, but in Rust
- Closing words
Contents
There's a question that always comes up when people pick up the
Rust programming language: why are there two
string types? Why is there String, and &str?
My Declarative Memory Management article answers the question partially, but there is a lot more to say about it, so let's run a few experiments and see if we can conjure up a thorough defense of Rust's approach over, say, C's.
Clear, simple, and wrong
Let's start with a simple C program that prints its arguments.
// in `print.c`
#include <stdio.h> // for printf
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
printf("%s\n", arg);
}
return 0;
}
$ gcc print.c -o print $ ./print "ready" "set" "go" ./print ready set go
Okay! Simple enough.
We're using the standard C11 main function signature, which takes the
number of argument (argc, for argument count) as an int, and an "array"
of "strings" (argv, for argument vector) as a char**, or char *[].
Then we use the printf format specifier %s to print each argument
as a string - followed by \n, a newline. And sure enough, it prints each
argument on its own line.
Before proceeding, let's make sure we have a proper understanding of what's going on.
// in `print.c`
int main(int argc, char **argv) {
printf("argv = %p\n", argv); // new!
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
printf("argv[%d] = %p\n", i, argv[i]); // new!
printf("%s\n", arg);
}
return 0;
}
Now we're using the %p format specifier, which prints.. pointers!
$ gcc print.c -o print $ ./print "ready" "set" "go" argv = 0x7ffcc35d84a8 argv[0] = 0x7ffcc35d9039 ./print argv[1] = 0x7ffcc35d9041 ready argv[2] = 0x7ffcc35d9047 set argv[3] = 0x7ffcc35d904b go
Okay, so, argv is an array of addresses, and at those addresses, there is..
string data. Something like that:
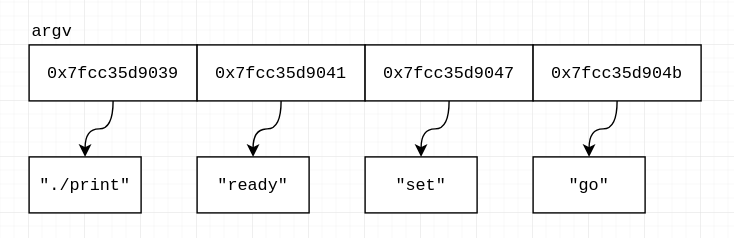
Mhh. How does printf's %s specifier know when to stop printing? Since it just
gets a single address, not a start and end address, or a start address and a length?
Let's try printing each argument ourselves:
// in `print.c`
#include <stdio.h> // printf
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
// we don't know where to stop, so let's just print 15 characters.
for (int j = 0; j < 15; j++) {
char character = arg[j];
// the %c specifier is for characters
printf("%c", character);
}
printf("\n");
}
return 0;
}
$ gcc print.c -o print $ ./print "ready" "set" "go" ./printreadys readysetgoCD setgoCDPATH=. goCDPATH=.:/ho
Uh oh. Our command-line arguments are bleeding into each other. It looks like they... all follow each other?
Let's try piping our program into a hexadecimal dumper like xxd, to see
exactly what's going on:
$ # note: "-g 1" means "show groups of one byte", $ # xxd defaults to "-g 2". $ ./print "ready" "set" "go" | xxd -g 1 00000000: 2e 2f 70 72 69 6e 74 00 72 65 61 64 79 00 73 0a ./print.ready.s. 00000010: 72 65 61 64 79 00 73 65 74 00 67 6f 00 43 44 0a ready.set.go.CD. 00000020: 73 65 74 00 67 6f 00 43 44 50 41 54 48 3d 2e 0a set.go.CDPATH=.. 00000030: 67 6f 00 43 44 50 41 54 48 3d 2e 3a 2f 68 6f 0a go.CDPATH=.:/ho.
AhAH! They do follow each other, but there's something in between - here's
the same output, annotated with ^^ where the separators are:
00000000: 2e 2f 70 72 69 6e 74 00 72 65 61 64 79 00 73 0a ./print.ready.s.
. / p r i n t ^^ r e a d y ^^
It looks like every argument is terminated by the value 0. Indeed, C has
null-terminated strings.
So we can "fix" our printing program:
#include <stdio.h> // printf
int main(int argc, char **argv) {
for (int i = 0; i < argc; i++) {
char *arg = argv[i];
// note: the loop condition is gone, we just loop forever.
// well, until a 'break' at least.
for (int j = 0;; j++) {
char character = arg[j];
// technically, we ought to use '\0' rather than just 0,
// but even `gcc -Wall -Wextra -Wpedantic` doesn't chastise
// us, so let's just go with it.
if (character == 0) {
break;
}
printf("%c", character);
}
printf("\n");
}
return 0;
}
$ gcc print.c -o print $ ./print "ready" "set" "go" ./print ready set go
All better! Although, we need to fix our diagram, too:
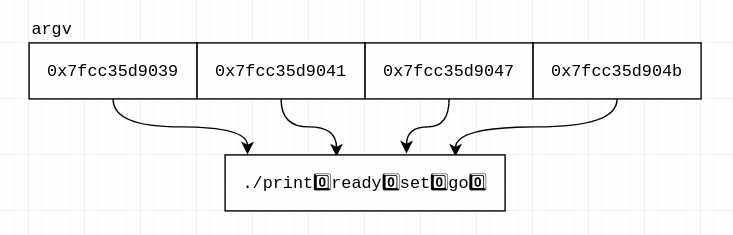
You may have noticed that when our print program went beyond the end of
our arguments, it showed CDPATH=.:/ho too.
That was (part of) an environment variable! Those are stored right next to the program's arguments in glibc, the GNU C library.
But the specifics are out of scope for this article, you may want to check out the Making our own executable packer series instead.
Okay! Now that we fully understand what's going on, let's do something a little more interesting: printing our arguments converted to upper-case.
So if we run ./print hello, it should print HELLO.
We'll also skip the first argument, because it's the name of the program, and that's not really interesting to us right now.
#include <stdio.h> // printf
#include <ctype.h> // toupper
int main(int argc, char **argv) {
// start from 1, skips program name
for (int i = 1; i < argc; i++) {
char *arg = argv[i];
for (int j = 0;; j++) {
char character = arg[j];
if (character == 0) {
break;
}
printf("%c", toupper(character));
}
printf("\n");
}
return 0;
}
$ gcc print.c -o print $ ./print "hello" HELLO
Alright! Nice going! Looks feature-complete to me, ready to be shipped.
Out of an abundance of caution, let's run one last test:
$ gcc print.c -o print $ ./print "élément" éLéMENT
Oh, uh, woops. What we really wanted was "ÉLÉMENT" but clearly, we haven't yet figured out everything that's going on.
Okay, maybe upper-casing is too complicated for now, let's do something simpler: print each character separated by a space.
// in `print.c`
#include <stdio.h> // printf
int main(int argc, char **argv) {
for (int i = 1; i < argc; i++) {
char *arg = argv[i];
for (int j = 0;; j++) {
char character = arg[j];
if (character == 0) {
break;
}
// notice the space following `%c`
printf("%c ", character);
}
printf("\n");
}
return 0;
}
$ gcc print.c -o print $ ./print "élément" l m e n t
Oh no. This won't do - it won't do at all.
Let's go back to our last well-behaved version, the one that just printed each character, without spaces in between, and see what the output actually was
// in main
// in for
// in second for
printf("%c", character); // notice the lack of space after `%c`
$ gcc print.c -o print
$ ./print "élément" | xxd -g 1
00000000: c3 a9 6c c3 a9 6d 65 6e 74 0a ..l..ment.
^^^^^ ^^^^^
If I'm, uh, reading this correctly, "é" is not a char, it's actually two
chars in a trenchcoat.
That seems... strange.
Let's write a quick JavaScript program and run it with Node.js:
// in `print.js`
const { argv, stdout } = process;
// we have to skip *two* arguments: the path to node,
// and the path to our script
for (const arg of argv.slice(2)) {
for (const character of arg) {
stdout.write(character);
stdout.write(" ");
}
stdout.write("\n");
}
$ node print.js "élément" é l é m e n t
Ah! Much better! Can Node.js also convert to upper-case properly?
// in `print.js`
const { argv, stdout } = process;
for (const arg of argv.slice(2)) {
stdout.write(arg.toUpperCase());
stdout.write("\n");
}
$ node print.js "élément" ÉLÉMENT
It can. Let's look at a hexadecimal dump:
$ node print.js "élément" | xxd -g 1
00000000: c3 89 4c c3 89 4d 45 4e 54 0a ..L..MENT.
^^^^^ ^^^^^
Although our Node.js program behaves as expected, we can see that É is
also different from the other letters, and that the upper-case counterpart
*of "c3 a9" is "c3 89".
Our C program didn't work - it couldn't work, because it was only seeing "c3" and "a9" individually, when it should have considered it as a single, uh, "Unicode scalar value".
Why is "é" encoded as "c3 a9"? It's time for a very quick UTF-8 encoding course.
A very quick UTF-8 primer
So, characters like "abcdefghijklmnopqrstuvwxyz", "ABCDEFGHIJKLMNOPQRSTUVWXYZ" and "123456789", and "!@#$%^&*()", etc., all have numbers.
For example, the number for "A" is 65. Why is that so? It's a convention! All a computer knows about is numbers, and we often use bytes as the smallest unit, so, a long time ago, someone just decided that if a byte has the value 65, then it refers to the letter "A".
Since ASCII is a 7-bit encoding, it has 128 possible values: from 0 to 127 (inclusive). But, on modern machines at least, a byte is 8 bits, so there's another 128 possible values.
Great! Everyone thought. We can just stuff "special characters" in there:
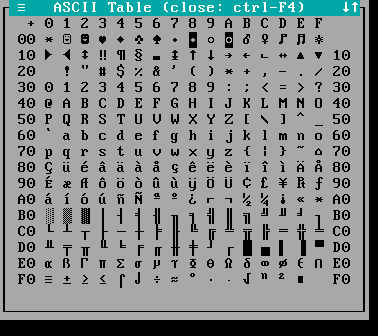
It's not... just ASCII, it's ASCII plus 128 characters of our choice. Of course, there's a lot of languages out there, so not every language's non-ASCII character can fit in those additional 128 values, so there were several alternative interpretations of those any value that was greater than 127.
Those interpretations were named "codepages". The picture above is Codepage 437, also known as CP437, OEM-US, OEM 437, PC-8, or DOS Latin US.
It's sorta adequate for languages like French, if you don't care about capital letters. It's not adequate at all for Eastern european languages, and doesn't even begin to cover Asian languages.
So, Japan came up with its own thing, where they replaced ASCII's backslash with a yen sign, the tilde with an overline (sure, why not), and introduced double-byte characters, because 128 extra characters sure wasn't enough for them.
Wait, replacing backslash? Does that mean... in file paths... ?
..yep.
And for the languages with smaller alphabets, people used other code pages like Windows-1252 for years, and most text in the Western world was still sorta kinda ASCII, also known as "extended ASCII".
But eventually, the world collectively started to put their affairs in order and settled on UTF-8, which:
- Looks like ASCII (not extended) for ASCII characters, and uses the same space.
- Allows for a lot more characters - like, billions of them with multi-byte sequences.
Of course, before that happened, people asked, isn't two bytes enough? (Or sequences of two two-byte characters?), and surely four bytes is okay, but eventually, for important reasons like compactness, and keeping most C programs half-broken instead of completely broken, everyone adopted UTF-8.
Except Microsoft.
Well, okay, they kinda did, although it feels like too little, too late. Everything is still UTF-16 internally. RIP.
Speaking of, the Bush hid the facts saga is hilarious.
So, yeah, ASCII plus multi-byte character sequences, how does it even work? Well, it's the same basic principle, each character has a value, so in Unicode, the number for "é" is "e9" - we usually write codepoints like so: "U+00E9".
And 0xE9 is 233 in decimal, which is greater than 127, so, it's not ASCII, and we need
to do multi-byte encoding.
How does UTF-8 do multi-byte encoding? With bit sequences!
- If a byte starts with
110it means we'll need two bytes - If a byte starts with
1110it means we'll need three bytes - If a byte starts with
11110it means we'll need four bytes - If a byte starts with
10, it means it's a continuation of a multi-byte character sequence.
So, for "é", which has codepoint U+00E9, its binary representation is "11101001", and we know we're going to need two bytes, so we should have something like this:
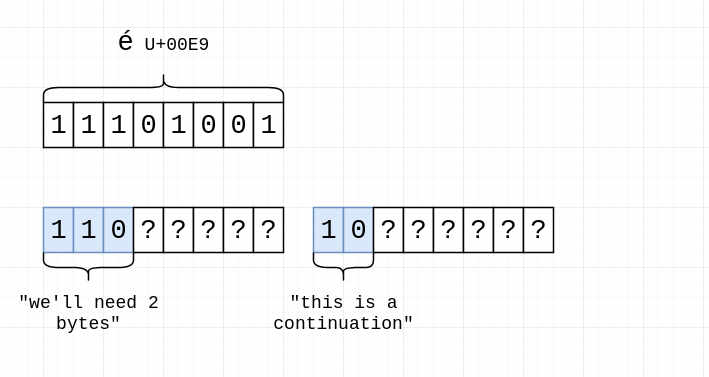
We can see in the lower part that two-byte UTF-8 sequences give us 11 bits of storage: 5 bits in the first byte, and 6 bits in the second byte. We only need to fit 8 bits, so we fill them from right to left, first the last 6 bits:
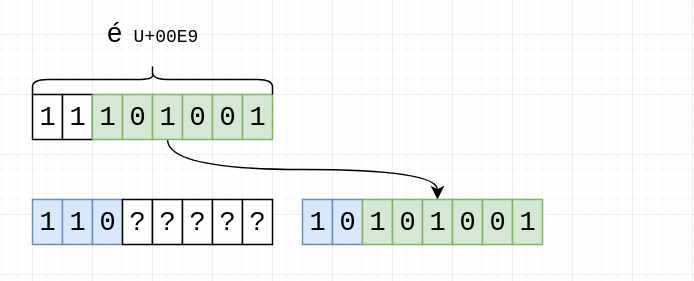
Then the remaining 2 bits:
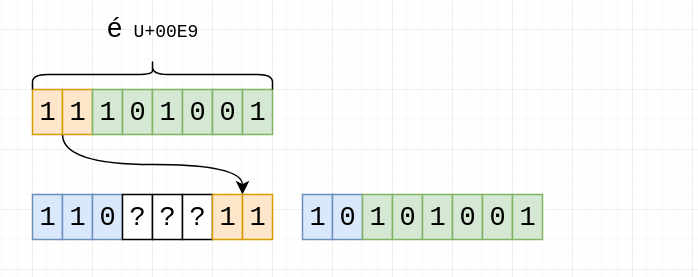
The rest is padding, filled with zeroes:
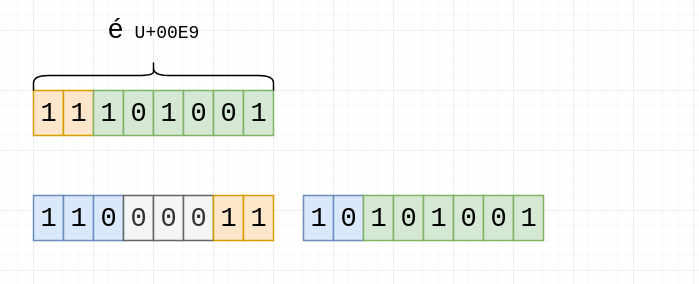
We're done! 0b11000011 is 0xC3, and 0b10101001 is 0xA9.
Which corresponds to what we've seen earlier - "é" is "c3 a9".
Back to C
So, uh, our C program. If we want to really separate characters, we have to do some UTF-8 decoding.
We can do that ourselves - no, really! Well, we can try anyway.
// in `print.c`
#include <stdio.h> // printf
#include <stdint.h> // uint8_t
void print_spaced(char *s) {
// start at the beginning
int i = 0;
while (1) {
// we're going to be shifting bytes around,
// so treat them like unsigned 8-bit values
uint8_t c = s[i];
if (c == 0) {
// reached null terminator, stop printing
break;
}
// length of the sequence, ie., number of bytes
// that encode a single Unicode scalar value
int len = 1;
if (c >> 5 == 0b110) {
len = 2;
} else if (c >> 4 == 0b1110) {
len = 3;
} else if (c >> 3 == 0b11110) {
len = 4;
}
// print the entire UTF-8-encoded Unicode scalar value
for (; len > 0; len--) {
printf("%c", s[i]);
i++;
}
// print space separator
printf(" ");
}
}
int main(int argc, char **argv) {
for (int i = 1; i < argc; i++) {
print_spaced(argv[i]);
printf("\n");
}
return 0;
}
There! Simple! None of that String and &str business. In fact, there's a
remarkable lack of Rust code for an article about Rust string handling, and
we're about ten minutes in already!
Binary literals, e.g. 0b100101010 are not standard C, they're a GNU
extension. Normally you'd see hexadecimal literals, e.g. 0xDEADBEEF, but
it's much harder to see what's going on since UTF-8 deals with individual
bits.
Does our program work?
$ gcc print.c -o print $ ./print "eat the rich" e a t t h e r i c h
So far so good!
$ ./print "platée de rösti" p l a t é e d e r ö s t i
Nice!
$ ./print "23€ ≈ ¥2731" 2 3 € ≈ ¥ 2 7 3 1
Cool!
$ ./print "text 🤷 encoding" t e x t 🤷 e n c o d i n g
Alright!
Well I don't know what everyone is complaining about, UTF-8 is super easy to implement, it only took us a few minutes and it is 100% correct and accurate and standards-compliant and it will work forever on all inputs and always do the right thing
...or will it?
Here comes the counter-example... I can feel it in my bones.
Consider the following string:
$ echo "noe\\u0308l" noël
It's just Christmas in French! Surely our program can handle that, no sweat:
$ ./print $(echo "noe\\u0308l") n o e ̈ l
Uh oh.
Turns out U+0308 is a "combining diaeresis", which is fancy talk for "just slap two dots on the previous character".
In fact, we can slap more of them if we want (for extra Christmas cheer):
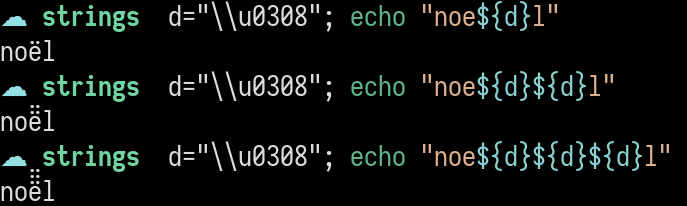
The combination of multiple scalar values that end up showing a single "shape" are called "grapheme clusters", and you should read Henri Sivonen's It’s Not Wrong that "🤦🏼♂️".length == 7 if you want to learn more about them.
Also, since I'm French, I'm writing this whole article with a Latin-1 bias, I haven't even talked about right-to-left scripts, vowel modifiers, syllable blocks, etc. - luckily, Manish Goregaokar has a great piece on that, Breaking Our Latin-1 Assumptions.
Okay. OKAY. So maybe our program doesn't implement all the subtleties of UTF-8 encoding, but, you know, we came pretty close.
We haven't tried converting things to upper-case in a while though.
Can we do that? Is that legal?
Let's find out.
So we'll disregard combining characters for now, and focus on Unicode scalar values. What we want is to:
- Decode our input, ie. transform it from UTF-8 to a series of Unicode scalar
values (we'll pick
uint32_t) - Transform said scalar values to their upper-case counterparts
- Re-encode as UTF-8
- Print to the console
So let's start with a decode_utf8 function. We'll only handle 2-byte sequences:
// in `upper.c`
#include <stdio.h> // printf
#include <stdint.h> // uint8_t, uint32_t
#include <stdlib.h> // exit
void decode_utf8(char *src, uint32_t *dst) {
int i = 0;
int j = 0;
while (1) {
uint8_t c = src[i];
if (c == 0) {
dst[j] = 0;
break; // null terminator
}
uint32_t scalar;
int len;
if (c >> 3 == 0b11110) {
fprintf(stderr, "decode_utf8: 4-byte sequences are not supported!\n");
exit(1);
} if (c >> 4 == 0b1110) {
fprintf(stderr, "decode_utf8: 3-byte sequences are not supported!\n");
exit(1);
} else if (c >> 5 == 0b110) {
// 2-byte sequence
uint32_t b1 = (uint32_t) src[i];
uint32_t b2 = (uint32_t) src[i + 1];
uint32_t mask1 = 0b0000011111000000;
uint32_t mask2 = 0b0000000000111111;
scalar = ((b1 << 6) & mask1) | ((b2 << 0) & mask2);
len = 2;
} else {
// 1-byte sequence
scalar = (uint32_t) c;
len = 1;
}
dst[j++] = scalar;
i += len;
}
}
int main(int argc, char **argv) {
uint32_t scalars[1024]; // hopefully that's enough
decode_utf8(argv[1], scalars);
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
printf("U+%04X ", scalars[i]);
}
printf("\n");
return 0;
}
$ gcc upper.c -o upper $ ./upper "noël" U+006E U+006F U+00EB U+006C
Logically, U+00EB should be the codepoint for "ë"... and it is!

Its full name is "Latin Small Letter E with Diaeresis". Okay.
So now we just have to do the reverse conversion - easy!
// in `upper.c`
void encode_utf8(uint32_t *src, char *dst) {
int i = 0;
int j = 0;
while (1) {
uint32_t scalar = src[i];
if (scalar == 0) {
dst[j] = 0; // null terminator
break;
}
if (scalar > 0b11111111111) {
fprintf(stderr, "Can only encode codepoints <= 0x%x", 0b11111111111);
exit(1);
}
if (scalar > 0b1111111) { // 7 bits
// 2-byte sequence
uint8_t b1 = 0b11000000 | ((uint8_t) ((scalar & 0b11111000000) >> 6));
// 2-byte marker first 5 of 11 bits
uint8_t b2 = 0b10000000 | ((uint8_t) (scalar & 0b111111));
// continuation last 6 of 11 bits
dst[j + 0] = b1;
dst[j + 1] = b2;
j += 2;
} else {
// 1-byte sequence
dst[j] = (char) scalar;
j++;
}
i++;
}
}
// omitted: decode_utf8
int main(int argc, char **argv) {
uint32_t scalars[1024]; // hopefully that's enough
decode_utf8(argv[1], scalars);
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
printf("U+%04X ", scalars[i]);
}
printf("\n");
uint8_t result[1024]; // yolo
encode_utf8(scalars, result);
printf("%s\n", result);
return 0;
}
$ gcc upper.c -o upper $ ./upper "noël" U+006E U+006F U+00EB U+006C noël
Fantastic!
Now all we need is some sort of conversion table! From lower-case codepoints to their upper-case equivalents.
We'll fill in just enough to support French:
#include <ctype.h> // toupper
int main(int argc, char **argv) {
uint32_t scalars[1024]; // hopefully that's enough
decode_utf8(argv[1], scalars);
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
printf("U+%04X ", scalars[i]);
}
printf("\n");
// this is the highest codepoint we can decode/encode successfully
const size_t table_size = 0b11111111111;
uint32_t lower_to_upper[table_size];
// initialize the table to just return the codepoint unchanged
for (uint32_t cp = 0; cp < table_size; cp++) {
lower_to_upper[cp] = cp;
}
// set a-z => A-Z
for (int c = 97; c <= 122; c++) { // ha.
lower_to_upper[(uint32_t) c] = (uint32_t) toupper(c);
}
// note: nested functions is a GNU extension!
void set(char *lower, char *upper) {
uint32_t lower_s[1024];
uint32_t upper_s[1024];
decode_utf8(lower, lower_s);
decode_utf8(upper, upper_s);
for (int i = 0;; i++) {
if (lower_s[i] == 0) {
break;
}
lower_to_upper[lower_s[i]] = upper_s[i];
}
}
// set a few more
set(
"éêèàâëüöïÿôîçæœ",
"ÉÊÈÀÂËÜÖÏŸÔÎÇÆŒ"
);
// now convert our scalars to upper-case
for (int i = 0;; i++) {
if (scalars[i] == 0) {
break;
}
scalars[i] = lower_to_upper[scalars[i]];
}
uint8_t result[1024]; // yolo
encode_utf8(scalars, result);
printf("%s\n", result);
return 0;
}
Let's take it for a spin:
$ gcc upper.c -o upper $ ./upper "Voix ambiguë d'un cœur qui, au zéphyr, préfère les jattes de kiwis" U+0056 U+006F U+0069 U+0078 U+0020 U+0061 U+006D U+0062 U+0069 U+0067 U+0075 U+00EB U+0020 U+0064 U+0027 U+0075 U+006E U+0020 U+0063 U+0153 U+0075 U+0072 U+0020 U+0071 U+0075 U+0069 U+002C U+0020 U+0061 U+0075 U+0020 U+007A U+00E9 U+0070 U+0068 U+0079 U+0072 U+002C U+0020 U+0070 U+0072 U+00E9 U+0066 U+00E8 U+0072 U+0065 U+0020 U+006C U+0065 U+0073 U+0020 U+006A U+0061 U+0074 U+0074 U+0065 U+0073 U+0020 U+0064 U+0065 U+0020 U+006B U+0069 U+0077 U+0069 U+0073 VOIX AMBIGUË D'UN CŒUR QUI, AU ZÉPHYR, PRÉFÈRE LES JATTES DE KIWIS
Wonderful!
Now for some Rust
Okay, so that was about 140 lines of C (with GNU extensions) - here's the gist if you want to mess with it.
Obviously, there's libraries to do all that for you, correctly. ICU is a popular choice, for its irritating completeness, but there's lighter alternatives that may suit your needs.
Proper UTF-8 handling is not just about computer security - software impacts actual human safety (CW: death) all the time.
Let's see what a Rust program that does the same thing would look like, though:
$ cargo new rustre
Created binary (application) `rustre` package
$ cd rustre
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("{}", arg.to_uppercase());
}
Turbo explanation of the above: std::env::args() returns an Iterator of
strings. skip(1) ignores the program name (which is usually the first
argument), next() gets the next element in the iterator (the first "real")
argument.
By that point we have an Option<String> - there might be a next argument, or
there might not be. If there isn't, .expect(msg) stops the program by printing
msg. If there is, we now have a String!
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/rustre`
thread 'main' panicked at 'should have one argument', src/libcore/option.rs:1188:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
Okay! So when we don't pass an argument, it says so. Wonderful.
Let's pass a few test strings:
$ cargo run --quiet -- "noël" NOËL $ cargo run --quiet -- "trans rights" TRANS RIGHTS $ cargo run --quiet -- "voix ambiguë d'un cœur qui, au zéphyr, préfère les jattes de kiwis" VOIX AMBIGUË D'UN CŒUR QUI, AU ZÉPHYR, PRÉFÈRE LES JATTES DE KIWIS $ cargo run --quiet -- "heinz große" HEINZ GROSSE
Everything checks out!
That last one is particularly cool - in German, "ß" (eszett) is indeed a ligature for "ss". Well, it's complicated, but that's the gist.
Error handling
So, Rust definitely behaves as if strings were UTF-8, that means it must decode our command-line arguments at some point. And that means... this can fail.
But I only see error handling for when we have no arguments at all, not for when the arguments are invalid utf-8.
Speaking of... what is invalid utf-8? Well, we've seen that "é" is encoded as "c3 e9", so this works:
$ cargo run --quiet -- $(printf "\\xC3\\xA9") É
And it works with our C program too:
$ ../print $(printf "\\xC3\\xA9") É
And we've seen that a two-byte UTF-8 sequence has:
- An indication in the first byte that it was a two-byte sequence
(the first three bits,
110) - An indication in the second byte that it was a continuation of a
multi-byte sequence (the first two bits,
10)
So.. what if we start a two-byte sequence and then abruptly stop?
What if we pass C3, but not A9?
$ cargo run --quiet -- $(printf "\\xC3") thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: "\xC3"', src/libcore/result.rs:1188:5 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
AhAH! A panic. Let's look at the backtrace:
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: "\xC3"', src/libcore/result.rs:1188:5
stack backtrace:
(cut)
13: core::result::unwrap_failed
at src/libcore/result.rs:1188
14: core::result::Result<T,E>::unwrap
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/result.rs:956
15: <std::env::Args as core::iter::traits::iterator::Iterator>::next::{{closure}}
at src/libstd/env.rs:789
16: core::option::Option<T>::map
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/option.rs:450
17: <std::env::Args as core::iter::traits::iterator::Iterator>::next
at src/libstd/env.rs:789
18: <&mut I as core::iter::traits::iterator::Iterator>::next
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/iter/traits/iterator.rs:2991
19: core::iter::traits::iterator::Iterator::nth
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/iter/traits/iterator.rs:323
20: <core::iter::adapters::Skip<I> as core::iter::traits::iterator::Iterator>::next
at /rustc/5e1a799842ba6ed4a57e91f7ab9435947482f7d8/src/libcore/iter/adapters/mod.rs:1657
21: rustre::main
at src/main.rs:2
(cut)
Okay, so, even with most of the frames cut, it's still a mouthful but basically:
- in
main() - we called
.next()on anIterator - which eventually called
.unwrap()on aResult - which panicked
This means it only panics if we try to get the arguments as a String.
If we get it as an OsString, for example, it doesn't panic:
fn main() {
let arg = std::env::args_os()
.skip(1)
.next()
.expect("should have one argument");
println!("{:?}", arg)
}
$ cargo run --quiet -- hello "hello" $ cargo run --quiet $(printf "\\xC3") "\xC3"
...but then we don't have a .to_uppercase() method. Because it's not
text. It's an OsString, ie. it's a a series of bytes which we might
be able to interpret as text (given the encoding) — or not.
Speaking of, how does our C program handle our invalid utf-8 input?
$ ../upper $(printf "\\xC3") U+00C0 U+0043 U+0044 U+0050 U+0041 U+0054 U+0048 U+003D U+002E U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0072 U+0075 U+0073 U+0074 U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0067 U+006F U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0066 U+0074 U+006C U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0070 U+0065 U+0072 U+0073 U+006F U+003A U+002F U+0068 U+006F U+006D U+0065 U+002F U+0061 U+006D U+006F U+0073 U+002F U+0077 U+006F U+0072 U+006B ÀCDPATH=.:/HOME/AMOS/RUST:/HOME/AMOS/GO:/HOME/AMOS/FTL:/HOME/AMOS/PERSO:/HOME/AMOS/WORK
The answer is: not well. Not well at all, in fact.
Our naive UTF-8 decoder first read C3 and was all like "neat, a 2-byte sequence!",
and then it read the next byte (which happened to be the null terminator), and decided
the result should be "à".
So, instead of stopping, it read past the end of the argument, right into
the environment block, finding the first environment variable, and now you can see
the places I cd to frequently (in upper-case).
Now, this seems pretty tame in this context... but what if it wasn't?
What if our C program was used as part of a web server, and its output was shown
directly to the user? And what if the first environment variable wasn't CDPATH, but
SECRET_API_TOKEN?
Then it would be a disaster. And it's not a hypothetical, it happens all the time.
By the way, our program is also vulnerable to buffer overflow attacks: if the input decodes to more than 1024 scalar values, it could overwrite other variables, potentially variables that are involved in verifying someone's credentials...
So, our C program will happily do dangerous things (which is very on-brand), but our Rust program panics early if the command-line arguments are not valid utf-8.
What if we want to handle that case gracefully?
Then we can use OsStr::to_str, which returns an Option - a value that is
either something or nothing.
fn main() {
let arg = std::env::args_os()
.skip(1)
.next()
.expect("should have one argument");
match arg.to_str() {
Some(arg) => println!("valid UTF-8: {}", arg),
None => println!("not valid UTF-8: {:?}", arg),
}
}
$ cargo run --quiet -- "é" valid UTF-8: é $ cargo run --quiet -- $(printf "\\xC3") not valid UTF-8: "\xC3"
Wonderful.
In Rust, provided you don't explicitly work around it with unsafe, values
of type String are always valid UTF-8.
If you try to build a String with invalid UTF-8, you won't get a String,
you'll get an error instead. Some helpers, like std::env::args(), hide the
error handling because the error case is very rare - but it still checks
for it, and panics if it happens, because that's the safe thing to do.
By comparison, C has no string type. It doesn't even have a real character type.
char is.. an ASCII character plus an additional bit - effectively, it's just
a signed 8-bit integer: int8_t.
There is absolutely no guarantee that anything in a char* is valid UTF-8,
or valid anything for that matter. There is no encoding associated to a char*,
which is just an address in memory. There is no length associated to it either,
so computing its length involves finding the null terminator.
Null-terminated strings are also a serious security concern. Not to mention that NUL is a valid Unicode character, so null-terminated strings cannot represent all valid UTF-8 strings.
Iteration
How would we go about separating characters by spaces?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
for c in arg.chars() {
print!("{} ", c);
}
println!()
}
$ cargo run --quiet -- "cup of tea" c u p o f t e a
That was easy! Let's try it with non-ASCII characters:
$ cargo run --quiet -- "23€ ≈ ¥2731" 2 3 € ≈ ¥ 2 7 3 1
$ cargo run --quiet -- "memory safety 🥺 please 🙏" m e m o r y s a f e t y 🥺 p l e a s e 🙏
Everything seems fine.
What if we want to print the Unicode scalar values's numbers instead of their, uh, graphemes?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
for c in arg.chars() {
print!("{} (U+{:04X}) ", c, c as u32);
}
println!()
}
$ cargo run --quiet -- "aimée" a (U+0061) i (U+0069) m (U+006D) é (U+00E9) e (U+0065)
Cool!
What if we want to show how it's encoded as UTF-8? By which I mean, print the individual bytes?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
for b in arg.bytes() {
print!("{:02X} ", b);
}
println!()
}
$ cargo run --quiet -- "aimée" 61 69 6D C3 A9 65
There's our c3 a9!
Easy enough. We didn't even have to worry about types - there hasn't been
a single String or &str in any of our Rust programs so far.
So, let's go looking for trouble.
Passing strings around
First, C.
C is easy! Just use char*! Don't worry about anything else.
// in `woops.c`
#include <stdio.h>
int len(char *s) {
int l = 0;
while (s[l]) {
l++;
}
return l;
}
int main(int argc, char **argv) {
char *arg = argv[1];
int l = len(arg);
printf("length of \"%s\" = %d\n", arg, l);
}
$ # we're back into the parent of the "rustre" directory $ # (in case you're following along) $ gcc woops.c -o woops $ ./woops "dog" length of "dog" = 3
See? Easy! None of that String / &str nonsense. No lifetimes, no nothing.
Ah. deep breath. Simpler times.
Okay, back to reality. First of all, that's not really the length of a string. It's.. the number of bytes it takes to encode it using UTF-8.
So, for example:
$ ./woops "née" length of "née" = 4
And also:
$ ./woops "🐈" length of "🐈" = 4
But in all fairness, that was to be expected. We didn't spend half the article implementing a half-baked UTF-8 decoder and encoder just to be surprised that, without one, we can't count characters properly.
Also, that's not what's bothering me right now.
What's bothering me right now is that the compiler does nothing to prevent us from doing this:
#include <stdio.h>
int len(char *s) {
s[0] = '\0';
return 0;
}
int main(int argc, char **argv) {
char *arg = argv[1];
int l = len(arg);
printf("length of \"%s\" = %d\n", arg, l);
}
$ gcc woops.c -o woops $ ./woops "some user input" length of "" = 0
And, you know, len() is right. By the time it's done... the length of the
string is zero. (It even "works" on non-ASCII inputs!).
This would pass unit tests. And if no one bothered to look at the len
function itself - say, if it was in a third-party library, or worse, a
proprietary third-party library, then it would be... interesting... to
debug.
"But Amos!" - you interject - "C has const"!
Okay, sure, C has const:
int len(const char *s) {
s[0] = '\0';
return 0;
}
Now it doesn't compile:
woops.c: In function ‘len’:
woops.c:4:10: error: assignment of read-only location ‘*s’
4 | s[0] = '\0';
|
But C also has unbounded leniency, and so:
int len(const char *s) {
char *S = (void *) s;
S[0] = '\0';
return 0;
}
Now it compiles again. And it runs. And it doesn't fail at runtime - it silently overwrites our input string, just the same.
Even -Wall, -Wextra and -Wpedantic don't warn us about this. They warn
us about argc being unused. Which, fair enough, not passing an argument
to ./woops definitely ends up reading from unmapped memory addresses and
crashes right now.
And if this is in a proprietary library, you're lulled into a false sense of security, because you look at the header file and you see this:
int len(const char *s);
But, granted - that's a contrived example. You'd have to be a pretty evil
vendor to ship a len function that mutates its input. Unless you do it
accidentally. Which you'd never do, right? Unless you do. In which case,
well, you shouldn't have. Obviously.
Right?
Okay so let's go with a more realistic example: a function that turns a string uppercase:
// in `woops.c`
#include <stdio.h>
#include <ctype.h>
void uppercase(char *s) {
// this is peak C right there
do {
*s = toupper(*s);
} while (*s++);
}
int main(int argc, char **argv) {
char *arg = argv[1];
char *upp = arg;
uppercase(upp);
printf("upp = %s\n", upp);
}
Sounds familiar right? But we're focused on a different aspect.
Anyway, it works:
$ gcc woops.c -o woops $ ./woops "dog" upp = "DOG"
But... I'm not happy with this code. What if we needed arg later?
// in `woops.c`
#include <stdio.h>
#include <ctype.h>
void uppercase(char *s) {
// this is peak C right there
do {
*s = toupper(*s);
} while (*s++);
}
int main(int argc, char **argv) {
char *arg = argv[1];
char *upp = arg;
uppercase(upp);
printf("arg = %s\n", arg);
printf("upp = %s\n", upp);
}
$ ./woops "dog" arg = DOG upp = DOG
Woops. The arg and upp variables point to the same memory,
and uppercase works in-place, so it changed both.
Well, I can think of a few ways to fix that! Either we can duplicate
the string before we call uppercase:
// in `woops.c`
#include <stdio.h>
#include <string.h>
#include <ctype.h>
void uppercase(char *s) {
do { *s = toupper(*s); } while (*s++);
}
int main(int argc, char **argv) {
char *arg = argv[1];
char *upp = strdup(arg);
uppercase(upp);
printf("arg = %s\n", arg);
printf("upp = %s\n", upp);
}
$ ./woops "dog" arg = dog upp = DOG
Or we could have uppercase return a fresh char *.
And this way, we can even use it directly as an argument to printf.
How convenient!
// in `woops.c`
#include <stdio.h>
#include <string.h>
#include <ctype.h>
char *uppercase(char *s) {
s = strdup(s);
char *t = s;
do { *t = toupper(*t); } while (*t++);
return s;
}
int main(int argc, char **argv) {
char *arg = argv[1];
printf("upp = %s\n", uppercase(arg));
printf("arg = %s\n", arg);
}
$ ./woops "dog" upp = DOG arg = dog
Wonderful! Correctness, at last!
We did, however, just introduce a memory leak into our program.
See, arg points to somewhere in memory that is set up at process startup.
Again, the details are out of scope, but what I can tell you with confidence
is that it hasn't been allocated with malloc, and it shouldn't be freed
with free.
The result of strdup, however, definitely needs to be freed by calling
free.
In fact, valgrind can easily confirm our program is leaking memory right now:
$ valgrind ./woops "hello valgrind" ==3628== Memcheck, a memory error detector ==3628== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==3628== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info ==3628== Command: ./woops hello\ valgrind ==3628== upp = HELLO VALGRIND arg = hello valgrind ==3628== ==3628== HEAP SUMMARY: ==3628== in use at exit: 15 bytes in 1 blocks ==3628== total heap usage: 2 allocs, 1 frees, 1,039 bytes allocated ==3628== ==3628== LEAK SUMMARY: ==3628== definitely lost: 15 bytes in 1 blocks ==3628== indirectly lost: 0 bytes in 0 blocks ==3628== possibly lost: 0 bytes in 0 blocks ==3628== still reachable: 0 bytes in 0 blocks ==3628== suppressed: 0 bytes in 0 blocks ==3628== Rerun with --leak-check=full to see details of leaked memory ==3628== ==3628== For lists of detected and suppressed errors, rerun with: -s ==3628== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Of course, for a short-lived program like that, it might not matter. If we're writing a more long-lived application, maybe a desktop one, or, worse, a server one, then it matters a lot.
So now, we have to remember to call free() on the result of uppercase().
Every time.
And the only hint in the function's signature is that it returns a char *.
Which is not immediately obvious when you just look at the call site.
So here's our non-leaky program:
// in `woops.c`
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <stdlib.h>
char *uppercase(char *s) {
s = strdup(s);
char *t = s;
do { *t = toupper(*t); } while (*t++);
return s;
}
int main(int argc, char **argv) {
char *arg = argv[1];
char *upp = uppercase(arg);
free(upp);
printf("upp = %s\n", upp);
printf("arg = %s\n", arg);
}
$ ./woops "good clean code" upp = arg = good clean code
Uhhh.. hang on.
$ valgrind ./woops "good clean code" ==4132== Memcheck, a memory error detector ==4132== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==4132== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info ==4132== Command: ./woops good\ clean\ code ==4132== ==4132== Invalid read of size 1 ==4132== at 0x483BCE2: __strlen_sse2 (vg_replace_strmem.c:463) ==4132== by 0x48EC61D: __vfprintf_internal (in /usr/lib/libc-2.30.so) ==4132== by 0x48D726E: printf (in /usr/lib/libc-2.30.so) ==4132== by 0x10920D: main (in /home/amos/ftl/strings/woops) ==4132== Address 0x4a4a040 is 0 bytes inside a block of size 16 free'd ==4132== at 0x48399AB: free (vg_replace_malloc.c:540) ==4132== by 0x1091F5: main (in /home/amos/ftl/strings/woops) ==4132== Block was alloc'd at ==4132== at 0x483877F: malloc (vg_replace_malloc.c:309) ==4132== by 0x490EBEE: strdup (in /usr/lib/libc-2.30.so) ==4132== by 0x109180: uppercase (in /home/amos/ftl/strings/woops) ==4132== by 0x1091E5: main (in /home/amos/ftl/strings/woops)
Oh wow, valgrind got good.
If we built our program with -g, it'd even show us line numbers in our ".c"
sources. It does show line numbers in glibc's ".c" sources, because I
installed glibc debug symbols recently, for reasons, but yeah, whoa, look
at that output.
So anyway, silly me, I freed upp right before printing it, my fingers
slipped, luckily this never happens in real life right haha.
It would be cool if the compiler could tell me about it at compile-time but
I guess it's impossible because free() is just a regular function so who's
to say what it actually does? What if we defined our own free function that
doesn't invalidate its argument? Checkmate, static analysts.
Anyway let's fix it real quick:
// in `woops.c`
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <stdlib.h>
char *uppercase(char *s) {
s = strdup(s);
char *t = s;
do { *t = toupper(*t); } while (*t++);
return s;
}
int main(int argc, char **argv) {
char *arg = argv[1];
char *upp = uppercase(arg);
printf("upp = %s\n", upp);
free(upp);
printf("arg = %s\n", arg);
}
$ ./woops "good clean code" upp = GOOD CLEAN CODE arg = good clean code
Wonderful!
Except.. it's not. Not really. Having a C function return a new allocation is, well, kind of an anti-pattern. Precisely because you might forget to free it.
Instead, we'd usually have a "source" and a "destination" parameter:
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <stdlib.h>
void uppercase(const char *src, char *dst) {
do { *dst++ = toupper(*src); } while (*src++);
}
int main(int argc, char **argv) {
const char *arg = argv[1];
char *upp = malloc(strlen(arg));
uppercase(arg, upp);
printf("upp = %s\n", upp);
free(upp);
printf("arg = %s\n", arg);
}
How nice. We even use const in all the right places! I think! Except maybe argv!
Who knows? The compiler sure doesn't seem to care much. I guess casting non-const to const
is pretty harmless. Fair enough, GCC, fair enough.
So anyway this works great:
$ gcc woops.c -o woops $ ./woops "clean design" upp = CLEAN DESIGN arg = clean design
It works so well I'm sure we don't even need to run it under valgrind. Who's got the time?
Well.. we do. We have the time. Let's be super duper safe:
$ valgrind ./woops "clean design" ==5823== Memcheck, a memory error detector ==5823== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==5823== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info ==5823== Command: ./woops clean\ design ==5823== ==5823== Invalid write of size 1 ==5823== at 0x10920A: uppercase (in /home/amos/ftl/strings/woops) ==5823== by 0x1090A8: main (in /home/amos/ftl/strings/woops) ==5823== Address 0x4a4a04c is 0 bytes after a block of size 12 alloc'd ==5823== at 0x483877F: malloc (vg_replace_malloc.c:309) ==5823== by 0x10909A: main (in /home/amos/ftl/strings/woops) ==5823== ==5823== Invalid read of size 1 ==5823== at 0x483BCF4: __strlen_sse2 (vg_replace_strmem.c:463) ==5823== by 0x48EC61D: __vfprintf_internal (in /usr/lib/libc-2.30.so) ==5823== by 0x48D726E: printf (in /usr/lib/libc-2.30.so) ==5823== by 0x1090B9: main (in /home/amos/ftl/strings/woops) ==5823== Address 0x4a4a04c is 0 bytes after a block of size 12 alloc'd ==5823== at 0x483877F: malloc (vg_replace_malloc.c:309) ==5823== by 0x10909A: main (in /home/amos/ftl/strings/woops) ==5823== upp = CLEAN DESIGN arg = clean design ==5823== ==5823== HEAP SUMMARY: ==5823== in use at exit: 0 bytes in 0 blocks ==5823== total heap usage: 2 allocs, 2 frees, 1,036 bytes allocated ==5823== ==5823== All heap blocks were freed -- no leaks are possible ==5823== ==5823== For lists of detected and suppressed errors, rerun with: -s ==5823== ERROR SUMMARY: 2 errors from 2 contexts (suppressed: 0 from 0)
Ohhhhh no. What did we do now?
char *upp = malloc(strlen(arg));
Oh RIGHT haha this never happens to me I swear, but, yeah, if you're allocating space for a string, you need to account for the null terminator.
This is like, Computers 101, I'm not sure what's up with me today - students have been learning this stuff for /decades/, I must be the first dude to ever get it wrong.
Ah well, let's add that one... last... fix:
char *upp = malloc(strlen(arg) + 1);
$ gcc woops.c -o woops $ ./woops "last fix" upp = LAST FIX arg = last fix
Fantastic! Even valgrind doesn't complain!
Now our program 100% does what it should: for each character of src, we
convert it to uppercase, and then store into dst, which was allocated by
the caller, so it's, well, clear-er that it's the caller's job to free it.
But um. Speaking of null terminators... what happened to it exactly? I don't
remember setting a null terminator in dst.
Let's print everything we send to toupper:
void uppercase(const char *src, char *dst) {
do {
printf("toupper('%c') (as hex: 0x%x)\n", *src, *src);
*dst++ = toupper(*src);
} while (*src++);
}
$ gcc woops.c -o woops
$ ./woops "last fix"
toupper('l') (as hex: 0x6c)
toupper('a') (as hex: 0x61)
toupper('s') (as hex: 0x73)
toupper('t') (as hex: 0x74)
toupper(' ') (as hex: 0x20)
toupper('f') (as hex: 0x66)
toupper('i') (as hex: 0x69)
toupper('x') (as hex: 0x78)
toupper('') (as hex: 0x0)
upp = LAST FIX
arg = last fix
Oh, haha. It turns out that, the way we wrote our loop, we read the null
terminator and pass it to toupper(), eventually writing it to dst. So we
made two mistakes (iterating too far, and not writing a null terminator) but
they, kinda, canceled each other out.
Lucky toupper has no way to return an error and just returns 0 for 0,
right? Or maybe 0 is what it returns on error? Who knows! It's a C API!
Anything is possible.
Again, I don't usually make those mistakes - I'm a programmer. Humans are not known for being fallible. This is clearly just a fluke. It would never happen if I was actually writing production code, much less if I worked for a large company.
And if I did, it probably wouldn't result in remote code execution or something nasty like that. It'd probably display a playful panda instead, that asks our users to wait until some of our engineers tend to the problem.
Right?
And even if I was working for a large company, and was writing production code, some tool probably would have caught that. Obviously Valgrind didn't, but you know, some other tool. I'm sure there's a tool. Somewhere.
Unless it's a perfectly legitimate use of the C language and standard library, just.. an incorrect one. And in that case no amount of tooling will help us. But that's why we have teams! Well, if we have a team. Surely a colleague would have caught it during code review. I thought it looked a bit suspicious. Didn't I say I felt funny about the code? I could've sworn.
Anyway, let's fix it. It won't look as C-ish as before, but it's for the sake of robust code, so just go with it:
void uppercase(const char *src, char *dst) {
for (int i = 0;; i++) {
if (src[i] == '\0') {
// null terminator
dst[i] = '\0';
return;
}
dst[i] = toupper(src[i]);
}
}
$ gcc woops.c -o woops $ ./woops "last fix (for real this time)" upp = LAST FIX (FOR REAL THIS TIME) arg = last fix (for real this time)
Alright. Enough playing around. We've finally achieved C perfection.
Although.....
Things certainly might go wrong if someone were to do something like this:
int main(int argc, char **argv) {
const char *arg = argv[1];
char *upp = malloc(strlen(arg) + 1);
arg = "doggo override";
uppercase(arg, upp);
printf("upp = %s\n", upp);
free(upp);
printf("arg = %s\n", arg);
}
$ gcc woops.c -o woops $ ./woops "dog" upp = DOGGO OVERRIDE arg = doggo override
Well, nothing seems wrong.
rings bell Garçon?
$ valgrind ./woops "dog" ==8023== Memcheck, a memory error detector ==8023== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==8023== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info ==8023== Command: ./woops dog ==8023== ==8023== Invalid write of size 1 ==8023== at 0x1091E1: uppercase (in /home/amos/ftl/strings/woops) ==8023== by 0x10923F: main (in /home/amos/ftl/strings/woops) ==8023== Address 0x4a4a044 is 0 bytes after a block of size 4 alloc'd ==8023== at 0x483877F: malloc (vg_replace_malloc.c:309) ==8023== by 0x10921D: main (in /home/amos/ftl/strings/woops) ==8023== ==8023== Invalid write of size 1 ==8023== at 0x1091B1: uppercase (in /home/amos/ftl/strings/woops) ==8023== by 0x10923F: main (in /home/amos/ftl/strings/woops) ==8023== Address 0x4a4a04e is 10 bytes after a block of size 4 alloc'd ==8023== at 0x483877F: malloc (vg_replace_malloc.c:309) ==8023== by 0x10921D: main (in /home/amos/ftl/strings/woops) ==8023== ==8023== Invalid read of size 1 ==8023== at 0x483BCF4: __strlen_sse2 (vg_replace_strmem.c:463) ==8023== by 0x48EC61D: __vfprintf_internal (in /usr/lib/libc-2.30.so) ==8023== by 0x48D726E: printf (in /usr/lib/libc-2.30.so) ==8023== by 0x109257: main (in /home/amos/ftl/strings/woops) ==8023== Address 0x4a4a044 is 0 bytes after a block of size 4 alloc'd ==8023== at 0x483877F: malloc (vg_replace_malloc.c:309) ==8023== by 0x10921D: main (in /home/amos/ftl/strings/woops) ==8023== ==8023== Invalid read of size 1 ==8023== at 0x49018F4: _IO_file_xsputn@@GLIBC_2.2.5 (in /usr/lib/libc-2.30.so) ==8023== by 0x48EAB51: __vfprintf_internal (in /usr/lib/libc-2.30.so)
Oh whoa. That's a lot of output. I've cut out the rest, but it keeps going on and on.
So the problem here is that... we allocate enough room for "DOG\0", but we
end up converting "doggo override\0" to uppercase, so we end up writing past
the area that malloc allocated for us.
I believe the technical term is a ~~~fucky wucky~~~ buffer overflow.
Well, let's look at the standard C library, for ideas on proper API design:
char *strdup(const char *s); char *strndup(const char *s, size_t n);
Ah, of course! They have this n variant that takes, well, a size, and it
won't write past that size.
But wait.. is n counting the null terminator or not?
The
strndup()function is similar, but copies at mostnbytes. Ifsis longer thann, onlynbytes are copied, and a terminating null byte ('\0') is added.
It does not.
Well, let's follow the shoulders of giants I guess (that's the expression, right?)
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#include <stdlib.h>
void nuppercase(const char *src, char *dst, int n) {
for (int i = 0; i < n; i++) {
if (src[i] == '\0') {
// null terminator
dst[i] = '\0';
return;
}
dst[i] = toupper(src[i]);
}
// null terminator in case we stopped because `i >= n`
dst[n] = '\0';
}
int main(int argc, char **argv) {
const char *arg = argv[1];
size_t upp_len = strlen(arg);
char *upp = malloc(upp_len + 1);
arg = "doggo override";
nuppercase(arg, upp, upp_len);
printf("upp = %s\n", upp);
free(upp);
printf("arg = %s\n", arg);
}
$ gcc woops.c -o woops $ ./woops "cat" upp = DOG arg = doggo override
Fantastic!
Of course, our program doesn't really do what we meant for it to do, but at least we've silenced Valgrind, so, close enough.
Also: we've only ever dealt with char*! None of that "multiple string
types" noise.
So simple. So relaxing.
uppercase, but in Rust
Okay so by now, we know that the program we ended up with can be written in Rust simply as:
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", arg.to_uppercase());
println!("arg = {}", arg);
}
$ cargo run --quiet -- "dog" upp = DOG arg = dog
But let's try to get this as close as possible to the C code, as an exercise.
First of all, doesn't this have a memory leak? We're not freeing the result
of to_uppercase anywhere! Nor are we freeing arg, for that matter.
$ cargo build --quiet $ valgrind ./target/debug/rustre "dog" ==9534== Memcheck, a memory error detector ==9534== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. ==9534== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info ==9534== Command: ./target/debug/rustre dog ==9534== upp = DOG arg = dog ==9534== ==9534== HEAP SUMMARY: ==9534== in use at exit: 0 bytes in 0 blocks ==9534== total heap usage: 23 allocs, 23 frees, 3,420 bytes allocated ==9534== ==9534== All heap blocks were freed -- no leaks are possible ==9534== ==9534== For lists of detected and suppressed errors, rerun with: -s ==9534== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
Mhh. No leaks. Very well.
But it doesn't look like the C version either. Our C version had an uppercase
function, so, let's make one:
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", uppercase(arg));
println!("arg = {}", arg);
}
fn uppercase(s: String) -> String {
s.to_uppercase()
}
$ cargo build --quiet
error[E0382]: borrow of moved value: `arg`
--> src/main.rs:8:26
|
2 | let arg = std::env::args()
| --- move occurs because `arg` has type `std::string::String`, which does not implement the `Copy` trait
...
7 | println!("upp = {}", uppercase(arg));
| --- value moved here
8 | println!("arg = {}", arg);
| ^^^ value borrowed here after move
error: aborting due to previous error
For more information about this error, try `rustc --explain E0382`.
error: could not compile `rustre`.
Oh lord here comes the compiler.
squints
Okay so... uh, the problem is that we call uppercase() which.. moves (?)
arg, and then we use arg again, and that's not good.
I guess we.. could first print arg and then call uppercase() second.
Would that work?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("arg = {}", arg);
println!("upp = {}", uppercase(arg));
}
fn uppercase(s: String) -> String {
s.to_uppercase()
}
$ cargo run --quiet -- "dog" arg = dog upp = DOG
It does! Alright!
But let's say we don't want to. Let's say we want to call uppercase first.
I guess we could pass it a copy of arg. Well, the compiler just told us
String does not implement the Copy trait, so.. I guess a clone of arg?
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", uppercase(arg.clone()));
println!("arg = {}", arg);
}
fn uppercase(s: String) -> String {
s.to_uppercase()
}
$ cargo run --quiet -- "dog" upp = DOG arg = dog
Neat!
This is kinda silly though - why do we need to clone arg? It's just the input
to uppercase. We don't need a second copy of it in memory. The first copy was just fine!
Right now, in memory we have:
arg(which is "dog")- the copy of
argwe sent touppercase()(which is "dog") - the value
uppercase()returns (which is "DOG")
Now, I'm no expert, but I'm guessing that's where &str comes in, huh?
Let's try it:
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
println!("upp = {}", uppercase(arg));
println!("arg = {}", arg);
}
fn uppercase(s: &str) -> String {
s.to_uppercase()
}
I'm not too sure about this, but in doubt, let's RTFC (Run The Friendly Compiler):
cargo run --quiet -- "dog"
error[E0308]: mismatched types
--> src/main.rs:7:36
|
7 | println!("upp = {}", uppercase(arg));
| ^^^
| |
| expected `&str`, found struct `std::string::String`
| help: consider borrowing here: `&arg`
Ahah. We were missing one piece of the puzzle.
Very well then:
println!("upp = {}", uppercase(&arg));
$ cargo run --quiet -- "dog" upp = DOG arg = dog
Nice! And still no memory leaks, if Valgrind is to be trusted.
Also, this function signature:
fn uppercase(s: &str) -> String
...can be trusted. Without using unsafe code (which you can audit for),
there is no way to modify s. It's not just "a cast away". You really,
really have to explicitly opt into doing dangerous stuff.
But, you know, still, this isn't close to the C code.
For it to be closer to the C code, we should:
- allocate a "destination"
- pass the destination to
uppercase() - have
uppercase()iterate through each character individually, convert them to uppercase, and append them to the destination
Obviously we don't have malloc and friends, and our strings aren't
null-terminated, but we can still get pretty close.
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
let mut upp = String::new();
println!("upp = {}", uppercase(&arg, upp));
println!("arg = {}", arg);
}
fn uppercase(src: &str, dst: String) -> String {
for c in src.chars() {
dst.push(c.to_uppercase());
}
dst
}
chants Run the friendly compiler! Run the friendly compiler!
$ cargo run --quiet -- "dog" error[E0308]: mismatched types --> src/main.rs:14:18 | 14 | dst.push(c.to_uppercase()); | ^^^^^^^^^^^^^^^^ expected `char`, found struct `std::char::ToUppercase`
audience ooohs
Well, this doesn't work. What the heck is a ToUppercase anyway. More types?
Just what we needed.
Let's read the docs I guess:
Returns an iterator that yields the uppercase equivalent of a char.
This
structis created by theto_uppercasemethod onchar. See its documentation for more.
Mh. Oh. OH! That's right! Remember this?
$ cargo run --quiet -- "heinz große" HEINZ GROSSE
Sometimes the upper-case equivalent of a char is.. several chars. So it returns
an iterator instead of a single char.
We didn't have that problem in woops.c, because, well, we didn't handle UTF-8 at all.
Very well, iterator, we know this - I think - we can use for x in y:
fn uppercase(src: &str, dst: String) -> String {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
dst
}
$ error[E0596]: cannot borrow `dst` as mutable, as it is not declared as mutable
--> src/main.rs:15:13
|
12 | fn uppercase(src: &str, dst: String) -> String {
| --- help: consider changing this to be mutable: `mut dst`
...
15 | dst.push(c);
| ^^^ cannot borrow as mutable
Mh. When did we ever borrow dst as mutable? I don't see a single & in uppercase.
Let's look at the declaration of String::push:
pub fn push(&mut self, ch: char)
Oh, there it is! So dst.push(c) is exactly the same as String::push(&mut dst, c).
Convenient.
So, yeah, let's make dst mut, just like the compiler suggested.
fn uppercase(src: &str, mut dst: String) -> String {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
dst
}
$ cargo run --quiet -- "dog" upp = DOG arg = dog
std::char::to_uppercase() returning an Iterator is great for performance - our C UTF-8
implementation was eager - it always decoded (or re-encoded) an entire string, but Rust's
standard library uses Iterators everywhere to make it lazy.
If we were to iterate through the characters of a string, convert them to uppercase, and check that the result contains "S", even if the input was a very large string, we'd only have a handful of characters at a time in memory, never the full thing. Also, we'd stop decoding once we've found the "S". It's a very flexible design!
But... that's not quite what the C code did, is it? When we had the C version of uppercase
take an src and dst, it returned... void!
Very well then:
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
let upp = String::new();
uppercase(&arg, upp);
println!("upp = {}", upp);
println!("arg = {}", arg);
}
fn uppercase(src: &str, mut dst: String) {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
}
cargo run --quiet -- "dog"
error[E0382]: borrow of moved value: `upp`
--> src/main.rs:10:26
|
7 | let upp = String::new();
| --- move occurs because `upp` has type `std::string::String`, which does not implement the `Copy` trait
8 | uppercase(&arg, upp);
| --- value moved here
9 |
10 | println!("upp = {}", upp);
| ^^^ value borrowed here after move
Oh, this again.
Well, now, we definitely cannot pass a copy of upp to uppercase() (even
though it is tempting), because then uppercase would not operate on the right copy
of upp, so, this would be wrong:
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
let upp = String::new();
uppercase(&arg, upp.clone());
println!("upp = {}", upp);
println!("arg = {}", arg);
}
$ cargo run --quiet -- "dog" upp = arg = dog
As expected, the upp we print ends up empty, which is what String::new returns.
By the way, String is heap-allocated, because it's growable. Whereas a &str can refer to data
from anywhere: the heap, the stack, even the program's data segment.
If you have lots of small strings, check out the
smol_str crate, which is immutable, provides
O(1) cloning, and stack-allocates strings smaller than 22 bytes.
It's similar in spirit to the smallvec crate.
So instead, we need to... let uppercase write to upp, just for a little bit.
We need to let it... borrow upp mutably. Right? Right.
fn main() {
let arg = std::env::args()
.skip(1)
.next()
.expect("should have one argument");
let mut upp = String::new();
// was just `upp`
uppercase(&arg, &mut upp);
println!("upp = {}", upp);
println!("arg = {}", arg);
}
// was `mut dst: String`
fn uppercase(src: &str, dst: &mut String) {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
}
..and now it works again!
$ cargo run --quiet -- "dog" upp = DOG arg = dog
Of course, we're still not 100% at parity with the C version. We didn't have
to call malloc, because String::new and String::push worry about
allocation for us. We didn't have to call free, because a String going
out of scope frees it automatically.
We didn't have to make an "n" variant of our function, because dst is a
mutable reference to a growable string, so it's impossible for us to write
past the end of it.
And finally, we couldn't mishandle the null terminator, because there is none.
So, wait, growable string and all.. does that mean we could pre-allocate
a String of reasonable size, and just re-use it for multiple uppercase
calls?
fn main() {
let mut upp = String::with_capacity(512);
for arg in std::env::args().skip(1) {
upp.clear();
uppercase(&arg, &mut upp);
println!("upp = {}", upp);
println!("arg = {}", arg);
}
}
fn uppercase(src: &str, dst: &mut String) {
for c in src.chars() {
for c in c.to_uppercase() {
dst.push(c);
}
}
}
cargo run --quiet -- "dog" "cat" "parrot" upp = DOG arg = dog upp = CAT arg = cat upp = PARROT arg = parrot
Yes, it does!
C allowed us to do direct indexing, does Rust allow us to do that?
fn main() {
for arg in std::env::args().skip(1) {
for i in 0..arg.len() {
println!("arg[{}] = {}", i, arg[i]);
}
}
}
$ cargo run --quiet -- "dog"
error[E0277]: the type `std::string::String` cannot be indexed by `usize`
--> src/main.rs:4:41
|
4 | println!("arg[{}] = {}", i, arg[i]);
| ^^^^^^ `std::string::String` cannot be indexed by `usize`
|
= help: the trait `std::ops::Index<usize>` is not implemented for `std::string::String`
Mh. No we cannot.
I guess we could first convert it to an array of Unicode scalar values, and then index that:
fn main() {
for arg in std::env::args().skip(1) {
let scalars: Vec<char> = arg.chars().collect();
for i in 0..scalars.len() {
println!("arg[{}] = {}", i, scalars[i]);
}
}
}
$ cargo run --quiet -- "dog" arg[0] = d arg[1] = o arg[2] = g
Yeah, that works! And to be honest, it's better, because we only have
to decode the UTF-8 string once - and then we get random access. That's
probably why it doesn't implement Index<usize>.
Here's an interesting thing that is supported though: Index<Range<usize>>
fn main() {
for arg in std::env::args().skip(1) {
let mut stripped = &arg[..];
while stripped.starts_with(" ") {
stripped = &stripped[1..]
}
while stripped.ends_with(" ") {
stripped = &stripped[..stripped.len() - 1]
}
println!(" arg = {:?}", arg);
println!("stripped = {:?}", stripped);
}
}
$ cargo run --quiet -- " floating in space "
arg = " floating in space "
stripped = "floating in space"
And what's even more interesting, is that this doesn't involve any allocations!
None!
It's a different &str, that points to the same memory region, it just
starts and ends at different offsets.
In fact, we could make it a function:
fn main() {
for arg in std::env::args().skip(1) {
let stripped = strip(&arg);
println!(" arg = {:?}", arg);
println!("stripped = {:?}", stripped);
}
}
fn strip(src: &str) -> &str {
let mut dst = &src[..];
while dst.starts_with(" ") {
dst = &dst[1..]
}
while dst.ends_with(" ") {
dst = &dst[..dst.len() - 1]
}
dst
}
And it would work just as well.
That seems.. dangerous, though - what if the memory of the original string is freed?
fn main() {
let stripped;
{
let original = String::from(" floating in space ");
stripped = strip(&original);
}
println!("stripped = {:?}", stripped);
}
$ cargo run --quiet -- " floating in space "
error[E0597]: `original` does not live long enough
--> src/main.rs:5:26
|
5 | stripped = strip(&original);
| ^^^^^^^^^ borrowed value does not live long enough
6 | }
| - `original` dropped here while still borrowed
7 | println!("stripped = {:?}", stripped);
| -------- borrow later used here
That is neat. If we had a similar function in C, it would be real easy to just free "original" and still use "stripped", and then, boom, instant use-after-free.
Which is why we probably wouldn't do it, in C. We would probably store the stripped string separately. But in Rust? Sure, why not! The compiler has got your back. It'll check for any shenanigans.
Lastly - indexing into a String with ranges is cool, but.. is it character ranges?
fn main() {
for arg in std::env::args().skip(1) {
println!("first four = {:?}", &arg[..4]);
}
}
$ cargo run --quiet -- "want safety?" first four = "want" $ cargo run --quiet -- "🙈🙉🙊💥" first four = "🙈"
Mh, byte ranges.
Wait. WAIT A MINUTE. I thought all Rust strings were UTF-8?
But using slicing, we can end up with partial multi-byte sequences, just like we crafted by hand earlier. And then, boom, invalid UTF-8, just like that.
Unless...
fn main() {
for arg in std::env::args().skip(1) {
println!("first two = {:?}", &arg[..2]);
}
}
$ cargo run --quiet -- "🙈🙉🙊💥" thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '🙈' (bytes 0..4) of `🙈🙉🙊💥`', src/libcore/str/mod.rs:2069:5 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
That is... that is just excellent. Not just the fact that it panics - which is the safe thing to do - but look at that message. I'm just completely in awe. No, I hadn't tried it before writing this article but DARN look at that thing.
Closing words
Anyway, this article is getting pretty long.
Hopefully it's a nice enough introduction to the world of string handling in
Rust, and it should motivate why Rust has both String and &str.
The answer, of course, is safety, correctness, and performance. As usual.
We did encounter roadblocks when writing our last Rust string manipulation program, but they were mostly compile-time errors, or panics. Not once have we:
- Read from an invalid address
- Written to an invalid address
- Forgotten to free something
- Overwritten some other data
- Needed an additional sanitizer tool to tell us where the problem was
And that, plus the amazing compiler messages, and the community, is the beauty of Rust.
If you want to learn more about Rust, check out A half-hour to learn Rust and Declarative Memory Management.
There's another string-ish type I haven't mentioned, and if you're curious, I definitely recommend reading Pascal Hertleif's The Secret Life Of Cows.
It's about "clone-on-write" strings, which let us do even fewer allocations.
And if you do read that, you should definitely take a look at
cow-utils, which implements clone-on-write
versions of replace, to_lowercase, to_uppercase and more.
If you liked what you saw, please support my work!

